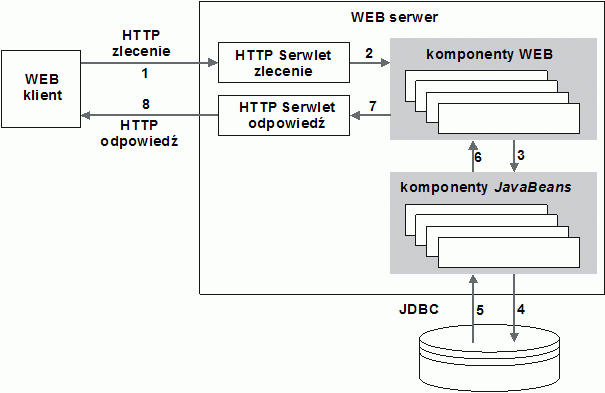
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.4"
xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee web-app_2_4.xsd">
...
... inne elementy
...
</web-app>
Uwaga: obecnie dostępna jest specyfikacja Servlet API 2.5, ale
nie wnosi ona zbyt wielu zmian i interesujących dodatków, możemy więc
spokojnie pzostać przy 2.4.
<welcome-file-list>
<welcome-file>plik1.jsp</welcome-file>
<welcome-file>plik2.jsp</welcome-file>
...
</welcome-file-list>
a w głównym katalogu aplikacji znajdują się któreś z tych plików, to zostanie wywołany pierwszy z listy, który jest w katalogu (jest to również sposób na dostarczenie użytkownikowi zwykłego pliku html, z którego albo mogą prowadzić linki do róznych części aplikacji, albo można dostarczyć form logowania, albo może on informować użytkownika, że zapomniał dodać do adresu zlecenia dodatkowej specyfikacji, np. zmapowanej nazwy serwletu i przez to nie może uruchomić aplikacji),
<?xml version="1.0"?>
<web-app version="2.4"
xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
<display-name>Sklep ogrodniczy</display-name>
<welcome-file-list>
<welcome-file>run.jsp</welcome-file>
</welcome-file-list>
</web-app>
została wdrożona poprzez
umieszczenie jej w podkatalugu gs katalogu webapps:import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
public class Msg extends HttpServlet {
// Początek HTML i właściwości <body> - tło, kolor tekstu i linków
private String prolog =
"<html><title>Przykład</title>" +
"<body background=\"images/os2.jpg\" text=\"antiquewhite\"" +
"link=\"white\" vlink=\"white\">";
// Tagi zamykające
private String epilog = "</body></html>";
// Metoda obsługi zlecenia GET
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
// Możemy w ten sposób ustalić typ treści i stronę kodową
// łatwiej niż przez generowanie metatagów HTML
response.setContentType("text/html; charset=ISO-8859-2");
// Strumień wyjściowy, tu generowana treść strony HTML
// PrintWriter umożliwia użycie metod print i println
PrintWriter out = response.getWriter();
out.println(prolog); // piszemy początek html i tag <body ... >
// Piszemy treść
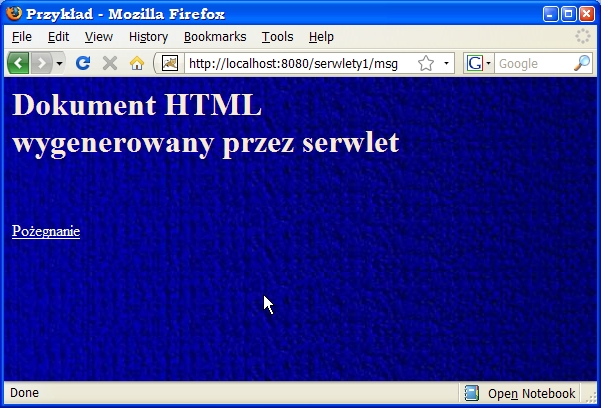
out.println("<h1>Dokument HTML<br>wygenerowany przez serwlet</h1>");
out.println("<br><br><a href=\"Bye.html\">Pożegnanie</a>");
// Znaczniki zamykające
out.println(epilog);
out.close();
}
}
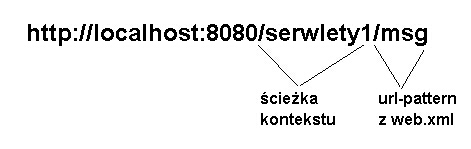
Ważne jest w tym przykładzie, aby zauważyć sposób odwołania z generowanej
strony do zasobów aplikacji (plików os2.jpg i Bye.html). Klasa serwletu
znajduje się w katalogu serwlety1/WEB-INF/classes. Odwołania do zasobów są
jednak zrelacjonowane wobec głównego katalogu aplikacji. Zatem odwołanie
"images/os2.jpg" jest - gdy patrzymy na naszą strukturę katalogową - odwołaniem "serwlety1/images/os2.jpg", a
odwołanie "Bye.html" znaczy "serwlety1/Bye.html". <servlet>
<servlet-name>HTMLMsg</servlet-name>
<description>Prosty napis</description>
<servlet-class>Msg</servlet-class>
</servlet>
Widzimy tu, że: <servlet-mapping>
<servlet-name>HTMLMsg</servlet-name>
<url-pattern>/msg</url-pattern>
</servlet-mapping>
Przy tym:<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.4"
xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
<display-name>Serwlety 1</display-name>
<description>Proste przykladowe serwlety</description>
<servlet>
<servlet-name>HTMLMsg</servlet-name>
<description>Prosty serwlet</description>
<servlet-class>Msg</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>HTMLMsg</servlet-name>
<url-pattern>/msg</url-pattern>
</servlet-mapping>
</web-app>
<Context path="/Show" docBase="G:/Programy/serwlety1/build"> </Context>KontekstE.xml
<Context path="/wa1" docBase="../../WebAplikacja1"> </Context>Tu zwrócmy uwagę na relatywną ścieżkę (zaczynamy z katalogu aplikacji E:/Serwery/apache-tomcat-6.0.13/webapps, .. /.. przenosi nas do katalogu E:/ i stąd wskazujemy katalog WebAplikacja1.
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.util.*;
import java.net.*;
public class Msg2 extends HttpServlet {
private ServletContext context;
private PrintWriter out;
public void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
out = resp.getWriter();
out.println("To jest strona wygenerowana przez serwlet " +
this.getClass().getName()+ ".class");
out.println("-------------------------------------------------------");
// Jak wygladal URL z ktorego przyszlo zlecenie
String requestURL = req.getRequestURL().toString();
out.println("RequestURL: " + requestURL);
// Uzyskujemy kontekst
context = this.getServletContext();
// Możemy od niego pobrać informacje o serwerze
out.println("\nServer info\n" + context.getServerInfo() );
// Możemy dowiedzieć się jaka jest nazwa aplikacji
// określona w <display-name>
out.println("\nAplikacja ma nazwe: " + context.getServletContextName() );
// Informacje o ścieżkach
String contextPath = req.getContextPath();
String servletPath = req.getServletPath();
// Od kontekstu możemy dowiedzieć się też jakie są fizyczne ścieżki
// prowadzace do "wirtualnych" URLI
out.println("\nInformacja o sciezkach");
msg("ContextPath", contextPath);
msg("ServletPath", servletPath);
// I nasze pliki "zasobowe" (HTML, JPG)
msg("Plik Bye.html", "Bye.html");
msg("Plik os2.jpg", "images/os2.jpg");
// Lista zasobów aplikacji
out.println("\nLista zasobow aplikacji");
listResources("/");
// Możemy na tych zasobach wykonywać op we-wy
InputStream in = context.getResourceAsStream("/WEB-INF/web.xml");
BufferedReader br = new BufferedReader( new InputStreamReader(in));
out.println("\nPierwszy wiersz pliku web.xml");
out.println(br.readLine());
br.close();
// W jakim katalogu działa serwlet?
File dir = new File(".");
out.println("\nA serwlet dzialal w katalogu: " + dir.getAbsolutePath());
out.close();
}
// Listuje zasoby aplikacji
private void listResources(String path) {
if (path == null) return;
Set res = context.getResourcePaths(path);
for (Iterator iter = res.iterator(); iter.hasNext(); ) {
String resItem = (String) iter.next();
if (resItem.endsWith("/")) listResources(resItem);
else out.println(resItem);
}
}
private void msg(String info, String path) {
out.println("------------------------------------------");
out.println(info);
String realPath = context.getRealPath(path);
out.println("Virtual: " + path);
out.println("Real : " + realPath);
}
}
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.4"
xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
<display-name>Serwlety 1</display-name>
<description>Proste przykladowe serwlety</description>
<servlet>
<servlet-name>HTMLMsg</servlet-name>
<description>Prosty serwlet</description>
<servlet-class>Msg</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>HTMLMsg</servlet-name>
<url-pattern>/msg</url-pattern>
</servlet-mapping>
<servlet>
<servlet-name>Msg2</servlet-name>
<description>Info o sciezkach</description>
<servlet-class>Msg2</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>Msg2</servlet-name>
<url-pattern>/paths</url-pattern>
</servlet-mapping>
</web-app<
a struktura naszej aplikacji jest teraz taka:To jest strona wygenerowana przez serwlet Msg2.class ------------------------------------------------------- RequestURL: http://localhost:8080/serwlety1/paths Server info Apache Tomcat/6.0.13 Aplikacja ma nazwe: Serwlety 1 Informacja o sciezkach ------------------------------------------ ContextPath Virtual: /serwlety1 Real : E:\Serwery\apache-tomcat-6.0.13\webapps\serwlety1\serwlety1 ------------------------------------------ ServletPath Virtual: /paths Real : E:\Serwery\apache-tomcat-6.0.13\webapps\serwlety1\paths ------------------------------------------ Plik Bye.html Virtual: Bye.html Real : E:\Serwery\apache-tomcat-6.0.13\webapps\serwlety1\Bye.html ------------------------------------------ Plik os2.jpg Virtual: images/os2.jpg Real : E:\Serwery\apache-tomcat-6.0.13\webapps\serwlety1\images\os2.jpg Lista zasobow aplikacji /Bye.html /images/os2.jpg /WEB-INF/classes/Msg.class /WEB-INF/classes/Msg2.class /WEB-INF/web.xml Pierwszy wiersz pliku web.xml <?xml version="1.0" encoding="UTF-8"?> A serwlet dzialal w katalogu: E:\Serwery\apache-tomcat-6.0.13\bin\.
<project name="nazwa projektu" default="build" basedir=".">
<target name="init">
<tstamp/>
</target>
Uwagi:app=serwlety1 app.path=E:/webaps/SERWLETYi użyjemy ich w pliku ant-a build.xml jako wartości zmiennych (oznaczanych przez ${nazwa_zmiennej}:
<property file="build.properties"/>
<property name="build" value="${app.path}/${app}/build" />
<property name="context.path" value="${app}" />
Powyżej, uzyskaliśmy wartości z pliku build.properties, po czym użyliśmy
ich do ustalenia właściwości build i context.path. Od tego momentu, zmienna
${build} ma wartość <target name="prepare" depends="init"
description="Buduje katalogi build">
<mkdir dir="${build}" />
<mkdir dir="${build}/WEB-INF" />
<mkdir dir="${build}/WEB-INF/classes" />
<mkdir dir="${build}/WEB-INF/lib" />
<mkdir dir="${build}/WEB-INF/tags" />
</target>
Uwagi: <!-- Sciezka klas dla kompilacji -->
<path id="classpath">
<fileset dir="${catalina.home}/lib">
<include name="*.jar"/>
</fileset>
</path>
Uwaga: <target name="build" depends="prepare"
description="Kompilacja i kopiowanie" >
<javac srcdir="src" destdir="${build}/WEB-INF/classes" debug="on">
<include name="**/*.java" />
<classpath refid="classpath"/>
</javac>
<copy todir="${build}/WEB-INF">
<fileset dir="web/WEB-INF" >
<include name="**/*.xml" />
<include name="**/*.html" />
<include name="**/*.tld" />
<include name="**/*.properties" />
<include name="**/*.txt" />
</fileset>
</copy>
<copy todir="${build}">
<fileset dir="web">
<include name="**/*.html" />
<include name="**/*.jsp" />
<include name="**/*.jspf" />
<include name="**/*.gif" />
</fileset>
</copy>
<copy todir="${build}/WEB-INF/tags">
<fileset dir="web">
<include name="**/*.tag" />
</fileset>
</copy>
</target>
Kompilowane i kopiowane są tylko te pliki, które zostały zmodyfikowane.<!-- definiowane zadania Anta dla Tomcata --> <taskdef name="install" classname="org.apache.catalina.ant.InstallTask"/> <taskdef name="reload" classname="org.apache.catalina.ant.ReloadTask"/> <taskdef name="remove" classname="org.apache.catalina.ant.RemoveTask"/> <taskdef name="deploy" classname="org.apache.catalina.ant.DeployTask"/> <taskdef name="undeploy" classname="org.apache.catalina.ant.UndeployTask"/>Po czym możemy ich użyć np.:
<target name="install" description="Instaluje aplikacje"
depends="build">
<install url="${url}" username="${username}" password="${password}"
path="/${context.path}" war="file:${build}"/>
</target>
<target name="install-config"
description="Instaluje w oparciu o context.xml" depends="build">
<install url="${url}" path="niewazne"
config="file:${app.path}/${app}/context.xml"
username="${username}" password="${password}"/>
</target>
<target name="reload" description="Przeladowuje aplikacje"
depends="build">
<reload url="${url}" username="${username}" password="${password}"
path="/${context.path}"/>
</target>
<target name="remove" description="Usuwa aplikacje">
<remove url="${url}" username="${username}" password="${password}"
path="/${context.path}"/>
</target>
Uwaga:username=admin password=admin catalina.home=E:/Serwery/apache-tomcat-6.0.13
<!--
Projekt
-->
<!DOCTYPE project [
<!ENTITY defbuild SYSTEM "../../common/defbuild.xml">
]>
<project name="moja aplikacja" default="build" basedir=".">
<target name="init">
<tstamp/>
</target>
&defbuild;
</project>
Zapis &defbuild włącza zawartości pliku defbuild.xml z katalogu common. <!-- Wlasciwosci dla dostepu do Managera aplikacji -->
<property name="url" value="http://localhost:8080/manager"/>
<!-- Konfiguracja wlasciwosci -->
<property file="../../common/build.properties"/>
<property file="build.properties"/>
<property name="build" value="${app.path}/${app}/build" />
<property name="context.path" value="${app}" />
<!-- Sciezka klas dla kompilacji -->
<path id="classpath">
<fileset dir="${catalina.home}/lib">
<include name="*.jar"/>
</fileset>
</path>
<!-- definiowane zadania Anta dla Tomcata -->
<taskdef name="install" classname="org.apache.catalina.ant.InstallTask"/>
<taskdef name="reload" classname="org.apache.catalina.ant.ReloadTask"/>
<taskdef name="remove" classname="org.apache.catalina.ant.RemoveTask"/>
<taskdef name="deploy" classname="org.apache.catalina.ant.DeployTask"/>
<taskdef name="undeploy" classname="org.apache.catalina.ant.UndeployTask"/>
<target name="prepare" depends="init"
description="Buduje katalogi build">
<mkdir dir="${build}" />
<mkdir dir="${build}/WEB-INF" />
<mkdir dir="${build}/WEB-INF/classes" />
<mkdir dir="${build}/WEB-INF/lib" />
<mkdir dir="${build}/WEB-INF/tags" />
</target>
<!-- wykonanie zadan -->
<target name="install" description="Instaluje aplikacje"
depends="build">
<install url="${url}" username="${username}" password="${password}"
path="/${context.path}" war="file:${build}"/>
</target>
<target name="install-config"
description="Instaluje w oparciu o context.xml" depends="build">
<install url="${url}" path="/${context.path}" war="file:${build}"
config="file:${app.path}/${app}/context.xml"
username="${username}" password="${password}"/>
</target>
<target name="reload" description="Przeladowuje aplikacje"
depends="build">
<reload url="${url}" username="${username}" password="${password}"
path="/${context.path}"/>
</target>
<target name="remove" description="Usuwa aplikacje">
<remove url="${url}" username="${username}" password="${password}"
path="/${context.path}"/>
</target>
<target name="build" depends="prepare"
description="Kompilacja i kopiowanie" >
<javac srcdir="src" destdir="${build}/WEB-INF/classes" debug="on">
<include name="**/*.java" />
<classpath refid="classpath"/>
</javac>
<copy todir="${build}/WEB-INF">
<fileset dir="web/WEB-INF" >
<include name="**/*.xml" />
<include name="**/*.html" />
<include name="**/*.tld" />
<include name="**/*.properties" />
<include name="**/*.txt" />
</fileset>
</copy>
<copy todir="${build}">
<fileset dir="web">
<include name="**/*.html" />
<include name="**/*.jsp" />
<include name="**/*.jspf" />
<include name="**/*.gif" />
</fileset>
</copy>
<copy todir="${build}/WEB-INF/tags">
<fileset dir="web">
<include name="**/*.tag" />
</fileset>
</copy>
</target>
oraz przykładowy plik build.properties (konkretnej aplikacji), np rozwijanej w katalogu G:/webaps/SERWLETY/jsp-testapp=jsp-test app.path=G:/webaps/SERWLETY
<target name="package"
description="Pakuje WAR">
<delete file="dist/${war.file}" />
<jar jarfile="dist/${war.file}" >
<fileset dir="${build}" />
</jar>
</target>
Katalog dist jest katalogiem "dystrybucji" i musi być oczywiście wcześniej utworzony.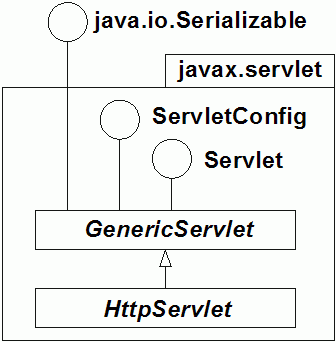
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.util.*;
public class Test extends HttpServlet {
static String loadMsg = "Klasa zaladowana " + new Date();
String createMsg = "\nSerwlet utworzony " + new Date();
String initMsg;
String config1Msg = "\nW konstruktorze ServletConfig ",
config2Msg = "\nW metodzie init ServletConfig ";
public Test() {
ServletConfig conf = getServletConfig();
if (conf == null)
config1Msg += "nie istnieje,\n" +
"zatem nie ma dostepu do kontekstu i inicjalnych parametrów";
else config1Msg += " istnieje !!??";
}
public void init() {
initMsg = "\nSerwlet zainicjowany " + new Date();
ServletConfig conf = getServletConfig();
if (conf == null) config2Msg += "nie istnieje !!??";
else {
config2Msg += "istnieje.\nMozemy odwolac sie do kontekstu" +
" i inicjalnych parametrów:\n";
// Uzyskanie kontekstu i dostęp do niego - dwa równoważne sposoby
ServletContext context1 = conf.getServletContext();
// poniższe odwolanie oznacza getConfig().getServletContext()
ServletContext context2 = getServletContext();
String name = context2.getServletContextName();
}
}
PrintWriter out;
public void service(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
out = resp.getWriter();
out.println(loadMsg);
out.println(createMsg);
out.println(config1Msg);
out.println(config2Msg);
out.println("obsluga zlecenia przez metode service " + new Date());
// Jezeli przedefinujemy metodę servis
// zazwyczaj będziemy wołać super.service(...)
// by przekazać zlecenie do obsługi przez konkretne metody
// np. doGet lub doPost
super.service(req, resp);
out.close();
}
public void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
out.println("\nWywolana metoda doGet " + new Date());
out.close();
}
}
który wywołany z paska adresu przeglądarki (co jest równoważne zleceniu GET)
utworzy i zwróci przeglądarce stronę rekstową o następującej zawartości:Klasa zaladowana Mon Sep 01 01:59:04 CEST 2008 Serwlet utworzony Mon Sep 01 01:59:04 CEST 2008 W konstruktorze ServletConfig nie istnieje, zatem nie ma dostepu do kontekstu i inicjalnych parametrów W metodzie init ServletConfig istnieje. Mozemy odwolac sie do kontekstu i inicjalnych parametrów: obsluga zlecenia przez metode service Mon Sep 01 01:59:04 CEST 2008 Wywolana metoda doGet Mon Sep 01 01:59:04 CEST 2008Na życzenie administratora serwera lub gdy aplikacja jest nieaktywna przez określony czas (ustalony przez odpowiednie opcje serwera) - serwlet jest usuwany. Wtedy wywoływana jest jego metoda destroy(). Możemy ją przedefiniować, szczególnie w tym celu, by uporządkować środowisko (np. zamknąć połączenia z bazami danych, usunąc jakieś niepotrzebne zasoby itp.).
| Zlecenie (metoda) |
Znaczenie |
Metoda klasy HTTPServlet |
| GET | uzyskanie zasobu identyfikowanego przez URL |
doGet |
| HEAD | Uzyskanie nagłówków |
doHead |
| POST | Wysłanie danych o nielimiotowanej długości |
doPost |
| PUT | Zapisanie zasobu |
doPut |
| DELETE | Usunięcie zasobu |
doDelete |
| OPTIONS | Zwrcaa metody HTTP podtrzymywane przez serwer |
doOptions |
| TRACE | Zwraca nagłówki wysłane zleceniem TRACE (do celów testowania_ |
doTrace |
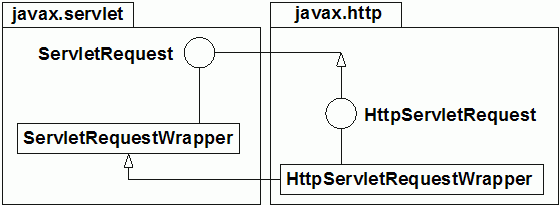
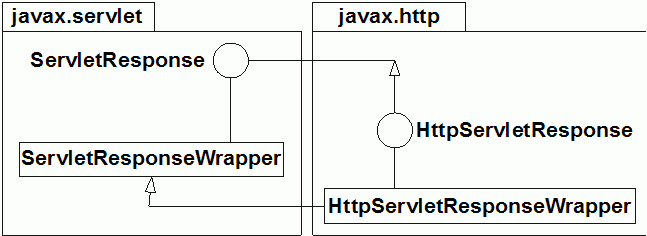
package international;
import java.util.*;
public class Messages_en extends ListResourceBundle {
public Object[][] getContents() {
return contents;
}
static final Object[][] contents = {
{ "hello", "Hello!" },
{ "now", "Now is: " },
{ "charset", "ISO-8859-1" }
};
}
package international;
import java.util.*;
public class Messages_pl extends ListResourceBundle {
public Object[][] getContents() {
return contents;
}
static final Object[][] contents = {
{ "hello", "Dzień dobry!" },
{ "now", "Teraz będzie, a właściwie już jest" },
{ "charset", "ISO-8859-2" }
};
}
Uwagi: import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.util.*;
import java.text.*;
public class Time1 extends HttpServlet {
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, java.io.IOException
{
// Jaki jest preferowany język klienta?
Locale locale = request.getLocale();
// Uzyskanie odpowiedniego zlokalizowanego zasobu
ResourceBundle msg = ResourceBundle.getBundle(
"international.Messages", locale);
// Zlokalizowane komunikaty i odpowiednia strona kodowa
String hello = msg.getString("hello");
String now = msg.getString("now");
String charset = msg.getString("charset");
// Ustalenie typu i kodowania odpowiedzi
// Musi być ustalone przed uzyskaniem strumienia wyjściowego
response.setContentType("text/html; charset=" + charset);
// Pobranie strumienia wyjściowego
// z zapewnieniem własciwego kodowania
// czasami wystarcza samo: PrintWriter out = response.getWriter()
PrintWriter out = new PrintWriter(
new OutputStreamWriter(response.getOutputStream(), charset),
true);
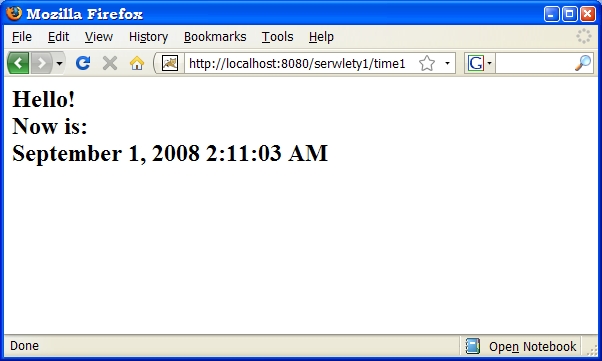
out.println("<h2>" + hello + "<br>" + now + "<br>" );
out.println(getDate(locale) + "</h2>");
out.close();
}
private String getDate(Locale loc) {
Date data = new Date();
DateFormat df = DateFormat.getDateTimeInstance(DateFormat.LONG,
DateFormat.MEDIUM,
loc);
return df.format(data);
}
}
a wynik jego działania będzie zależał nie tylko od aktualnej daty i czasu,
ale również od ustawień językowych przeglądarki klienta.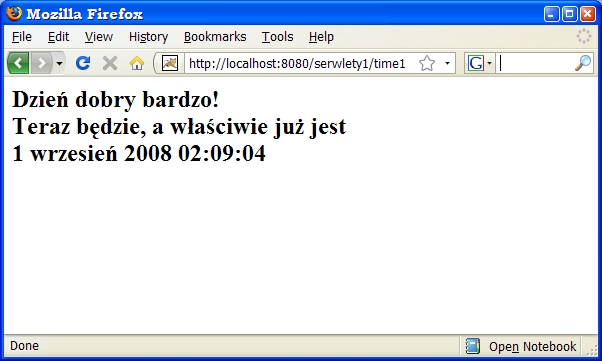
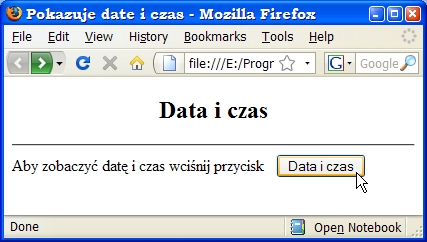
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=windows-1250"> <title>Pokazuje date i czas</title> </head> <body> <center><h2>Data i czas</h2></center> <hr> <form method="post" action ="http://localhost:8080/serwlety1/Time"> Aby zobaczyć datę i czas wciśnij przycisk   <input type="submit" value="Data i czas"> </form> </body> </html>możemy wywołać nasz serwlet (jako część aplikacji o kontekście serwlety1 z mapowaniem nazwy serwletu na odwołanie /Time)
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.util.*;
import java.text.*;
public class ShowTime0 extends HttpServlet {
public void serviceRequest(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
Locale locale = req.getLocale();
// ...
out.close();
}
// ...
//--- Stanadardowa część serwletu -----------------------------------
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
serviceRequest(request, response);
}
public void doPost(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
serviceRequest(request, response);
}
}
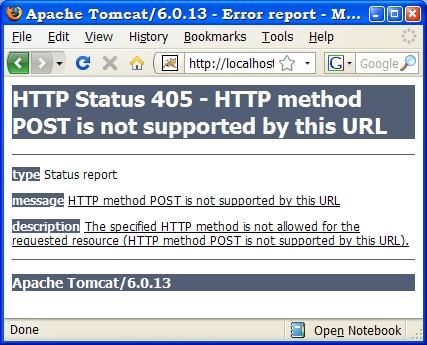
Oczywiście, w tym przykładzie nie ma żadnego sensu (choć jest możliwe) posyłanie
zlecenia POST, bo jak wspomniano służy ono głównie do przekazywania informacji
zawartych w formularzach (a tu żadnej informacji użytkownik nie dostarcza).
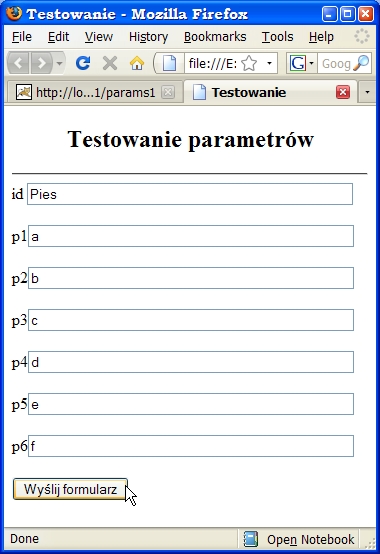
Ale również zlecenie GET może być użyte w tym samym celu. <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=windows-1250"> <title>Testowanie</title> </head> <body> <center><h2>Testowanie parametrów</h2></center> <hr> <form method="get" action="http://localhost:8080/serwlety1/params1"> id<input type="text" size="50" name="ident"><br> p1<input type="text" size="50" name="p1"><br> p2<input type="text" size="50" name="p2"><br> p3<input type="text" size="50" name="p3"><br> p4<input type="text" size="50" name="p4"><br> p5<input type="text" size="50" name="p5"><br> p6<input type="text" size="50" name="p6"><br> _ <br><input type="submit" value="Wyślij formularz"> </form> </body></html>Mamy tu 7 pól tekstowych, każde z nich ma nadaną nazwę (ident, p1, ...p6).
public void serviceRequest(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
PrintWriter out = resp.getWriter();
out.println("Metoda: " + req.getMethod());
out.println("Query : " + req.getQueryString());
out.println("Parametry:");
Enumeration pnams = req.getParameterNames();
while (pnams.hasMoreElements()) {
String name = (String) pnams.nextElement();
String value = req.getParameter(name);
out.println(name + " = " + value);
}
out.println("Dostęp przez mapę");
Map map = req.getParameterMap();
String[] val = (String[]) map.get("ident");
out.println("Parametr o nazwie ident");
out.println("- z mapy uzyskujemy tablice String[]");
out.println("- jej rozmiar " + val.length );
out.println("- jej elementy:" );
for (int i=0; i<val.length; i++) out.println(val[i]);
out.close();
}
Widzimy tu różne sposoby uzyskiwania wartości parametrów. Warte szczególnej
uwagi jest to, że wartości mapy parametrów są tablicami typu String[] (oczywiście klucze
to nazwy parametrów).Metoda: GET Query : ident=Pies&p1=a&p2=b&p3=c&p4=d&p5=e&p6=f Parametry: p6 = f p5 = e p4 = d p3 = c ident = Pies p2 = b p1 = a Dostep przez mape Parametr o nazwie ident - z mapy uzyskujemy tablice String[] - jej rozmiar 1 - jej elementy: Pies
... <form method="post" action="http://localhost:8080/serwlety1/params1"> ...i znowy poślemy go do przykładowego serwletu uzyskamy nieco inny wynik:
Metoda: POST Query : null // ... dalej jak w metodzie GETAle możemy również bezpośrednio odczytać treść zlecenia ze strumienia związanego z obiektem zlecenia:
public void serviceRequest(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
PrintWriter out = resp.getWriter();
out.println("Metoda: " + req.getMethod());
// Przy zleceniu POST
// Albo uzyskujemy parametry przez metody getParameter...
// albo czytamy je ze strumienia jako "ciało" zlecenia
// ale nie równocześnie i to i to
boolean readBodyStream = true; // czytamy ze strumienia
if (!readBodyStream) {
// ... poprzedni kod
}
else {
out.println("Czytanie tresci (ciała) zlecenia ze strumienia:");
BufferedReader br = req.getReader();
String line;
while ((line = br.readLine()) != null) out.println(line);
br.close();
}
out.close();
}
co da w wyniku:Metoda: POST Czytanie tresci (ciala) zlecenia ze strumienia: ident=Pies&p1=a&p2=b&p3=c&p4=d&p5=e&p6=fOczywiście, treść zlecenia nie musi mieć nic wspólnego z formularzami i parametrami. Klient HTTP może posłać za pomocą metody POST dowolną informację, o dowolnym rozmiarze
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=windows-1250"> <title>Testowanie</title> </head> <body> <center><h2>Testowanie wyrażeń regularnych</h2></center> <hr> <form method="post" action="http://localhost:8080/serwlety1/regex1"> Wzorzec: <br> <input type="text" size="30" name="regex"><br> Tekst:<br> <input type="text" size="50" name="input"><br><br> <input type="submit" value="Pokaż wynik wyszukiwania"> </form> </body></html>i wygeneruje stronę wynikową. Metoda serviceRequest (już tradycyjnie będziemy ją stosowac jako cel odwołań zarówno z doGet jak i doPost) wygląda następująco:
public void serviceRequest(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
String charset = "windows-1250";
// Uwaga. Należy ustalić właściwą stronę kodową zlecenia
// bez tego parametry nie będą właściwie odczytane
// Tu - ustalamy stronę windows-1250, bo nasz formularz
// jest zapisany w takim właśnie kodowaniu
req.setCharacterEncoding(charset);
resp.setContentType("text/html; charset=" + charset);
PrintWriter out = resp.getWriter();
String regex = req.getParameter("regex");
String input = req.getParameter("input");
if (regex == null || input == null) {
out.println("<h2>Wadliwe argumenty wywołania</h2>");
out.close();
return;
}
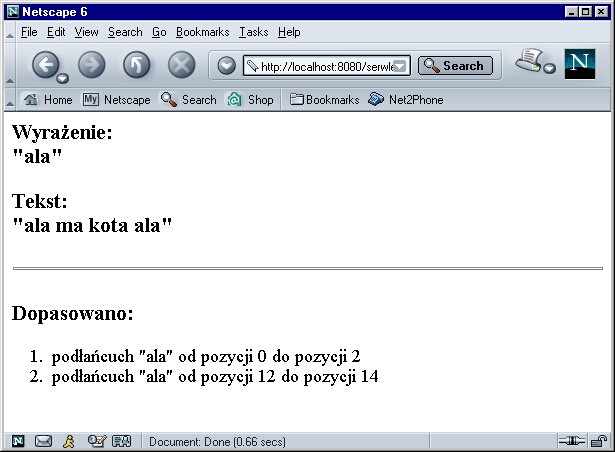
out.println("<h3>Wyrażenie:<br>\"" + regex + "\"</h3>");
out.println("<h3>Tekst:<br>\"" + input + "\"</h3>");
out.println("<hr>");
try {
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
boolean found = matcher.find();
if (!found)
out.println("<h3>Nie znaleziono żadnego podłańcucha " +
"pasującego do wzorca</h3>");
else {
out.println("<h3>Dopasowano:</h3>");
out.println("<ol>");
do {
out.println("<li>podłańcuch \"" + matcher.group() +
"\" od pozycji " + matcher.start() +
" do pozycji " + (matcher.end()-1) + "</li>");
} while(matcher.find());
out.println("</ol>");
}
} catch (PatternSyntaxException exc) {
out.println("<h2>Błąd w wyrażeniu</h2>");
} finally {
out.close();
}
}
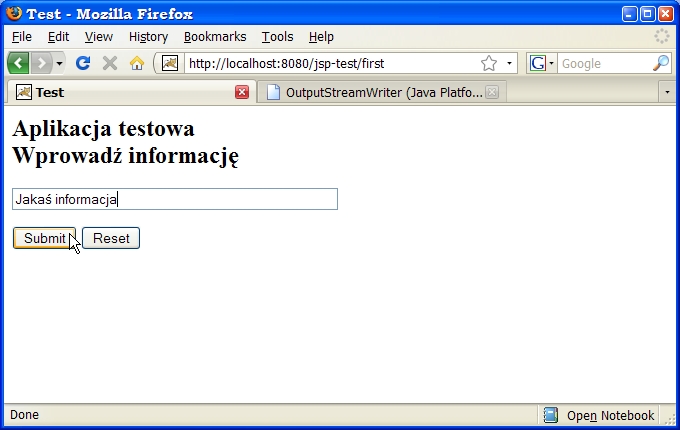
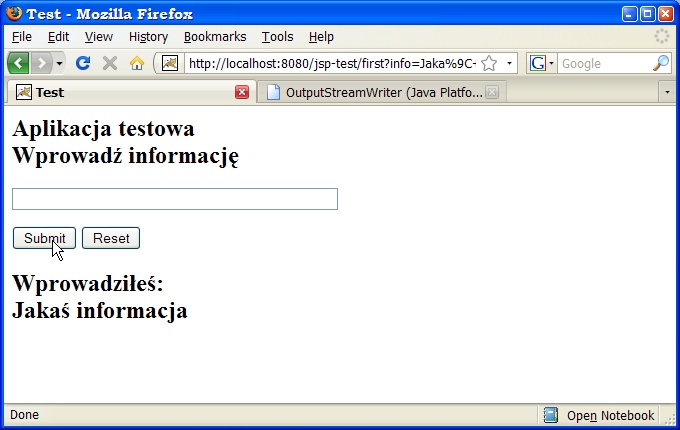
a działanie serwletu ilustrują rysunki: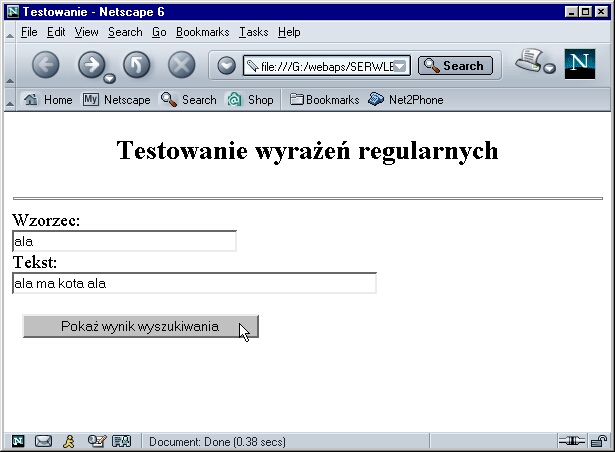
<center><h2>Testowanie wyrażeń regularnych</h2></center> <hr> <form method="post"> Wzorzec: <br> <input type="text" size="30" name="regex"><br> Tekst:<br> <input type="text" size="50" name="input"><br><br> <input type="submit" value="Pokaż wynik wyszukiwania"> </form>
<servlet>
<servlet-name>RegexTest</servlet-name>
<description>Regularne wyrazenia 1</description>
<servlet-class>RegexTest</servlet-class>
<init-param>
<param-name>regexFormFile</param-name>
<param-value>regexform.html</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>RegexTest</servlet-name>
<url-pattern>/regex1</url-pattern>
</servlet-mapping>
Nowy kod serwletu wygląda w następujący sposób:public class RegexTest extends HttpServlet {
private PrintWriter out;
private void printEndTag() { out.println("</body></html>"); }
public void serviceRequest(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
String charset = "ISO8859-2";
req.setCharacterEncoding(charset);
resp.setContentType("text/html; charset=" + charset);
out = resp.getWriter();
out.println("<html>");
out.println("<head><title>Testowanie</title></head>");
out.println("<body>");
// Nazwę pliku z formularzem dostarczymy
// jako parametr inicjalny serwletu
String formFile = getInitParameter("regexFormFile");
// Przeczytamy go i wpiszemy na generowaną stronę
ServletContext context = getServletContext();
InputStream in = context.getResourceAsStream("/WEB-INF/"+formFile);
BufferedReader br = new BufferedReader( new InputStreamReader(in));
String line;
while ((line = br.readLine()) != null) out.println(line);
// Pobieramy parametry formularza
String regex = req.getParameter("regex");
String input = req.getParameter("input");
// Przy pierwszym odwołaniu do serwletu - parametrów nie ma
// zatem poprzestajemy na wygenerowaniu formularza
if (regex == null || input == null) {
printEndTag();
out.close();
return;
}
// W przeciwnym razie jakieś parametry (chcoćby puste) już są
// Przetwarzamy je i uzupełniamy stronę z formularzem
out.println("<hr>");
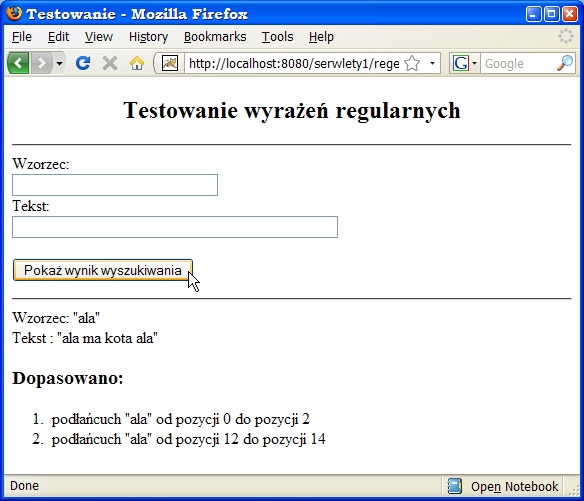
out.println("Wzorzec: \"" + regex + "\"<br>");
out.println("Tekst : \"" + input + "\"<br>");
try {
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
boolean found = matcher.find();
if (!found)
out.println("<h3>Nie znaleziono żadnego podłańcucha " +
"pasującego do wzorca</h3>");
else {
out.println("<h3>Dopasowano:</h3>");
out.println("<ol>");
do {
out.println("<li>podłańcuch \"" + matcher.group() +
"\" od pozycji " + matcher.start() +
" do pozycji " + (matcher.end()-1) + "</li>");
} while(matcher.find());
out.println("</ol>");
}
} catch (PatternSyntaxException exc) {
out.println("<h2>Błąd w wyrażeniu</h2>");
} finally {
printEndTag();
out.close();
}
}
// ... metody doGet o doPost wołające serviceRequest
}
Teraz wywołujemy serwlet bezpośrednio (proszę zwrócić uwagę na pasek adresu na poniższym rysunku) i wpisujemy dane: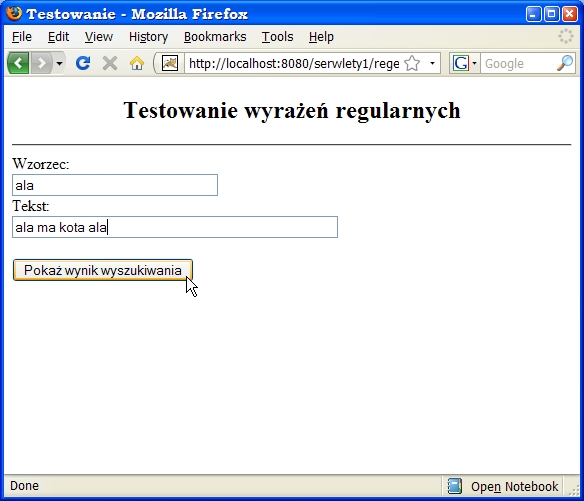
try {
Pattern pattern = Pattern.compile(regex); // Logika
Matcher matcher = pattern.matcher(input); // Logika
boolean found = matcher.find(); // Logika
if (!found) // Logika
out.println("<h3>Nie znaleziono żadnego podłańcucha " + // Prezentacja
"pasującego do wzorca</h3>");
else { // Logika
out.println("<h3>Dopasowano:</h3>"); // Prezentacja
out.println("<ol>"); // Prezentacja
do {
out.println("<li>podłańcuch \"" + matcher.group() + // L + P
"\" od pozycji " + matcher.start() + // L + P
" do pozycji " + (matcher.end()-1) + "</li>"); // L + P
} while(matcher.find());
out.println("</ol>"); // Prezentacja
}
} catch (PatternSyntaxException exc) { // Logika
out.println("<h2>Błąd w wyrażeniu</h2>"); // Prezentacja
} finally { // Logika
printEndTag(); // Prezentacja
out.close(); // Prezentacja
}
|
Różnica pomiędzy parametrami i atrybutami kontekstu
|
|
|
Parametry
|
Atrybuty
|
|---|---|
| Parametry mogą być ustalone wyłacznie w pliku web.xml za pomocą elementu context-param | Atrybuty mogą być ustalane dynamicznie przez serwlety (albo przez serwer). |
| Wartości są typu String. | Wartości są referencjami do dowolnych obiektów (ogólnie klasy Object), klucze (nazwy atrybutów) są typu String. |
|
Metody dotyczące atrybutów
|
|
| void | setAttribute(String name, Object value) |
| Object | getAttribute(String name) |
| Enumeration | getAttributeNames() |
| void |
removeAttribute(String name) |
| W klasach: ServletRequest - dotyczą danego zlecenia HttpSession - dotyczą danej sesji (tego samego klienta) ServletContext - dotyczą całej aplikacji (wszystkich sesji i klientów) |
|
|
Przekazywanie zleceń
RequestDispatcher Uzyskujemy od kontekstu (ServletContext) lub zlecania (ServletRequest) za pomocą metody getRequestDispatcher(), podając odniesienie do zasobu (np. innego serwletu, który ma przejąć obsługę zlecenia) | ||
|---|---|---|
void forward(ServletRequest, ServletResponse) Przekazuje zlecenie do obsługi przez inny aktywny komponent (serwlet). Odpowiedź nie może być zatwierdzona (commited). Sterowanie nie wraca do "wywołującego" serwletu. | ||
| void include(ServletRequest, ServletResponse) Przekazuje zlecenie do obsługi tymczasowo, po czym można kontynuować dalszą obsługę tego zlecenia w "wywołującym" serwlecie. Również pozwala na włączanie statycznych zasobów (np. stron HTML). |
import java.util.*;
public interface Command {
void init();
void setParameter(String name, Object value);
Object getParameter(String name);
void execute();
List getResults();
void setStatusCode(int code);
int getStatusCode();
}
Zatem każda klasa dzialania powinna implementować metody inicjacji, ustalania
i pobierania ew. parametrów, wykonania działania, ustalenia i pobrania kodu
wyniku, pobrania wyniko działania. Umówimy się, że wyniki będą dostępne jako
lista.import java.util.*;
import java.io.*;
public class CommandImpl implements Serializable, Command {
private Map parameterMap = new HashMap();
private List resultList = new ArrayList();
private int statusCode;
public CommandImpl() {}
public void init() {}
public void setParameter(String name, Object value) {
parameterMap.put(name, value);
}
public Object getParameter(String name) {
return parameterMap.get(name);
}
public void execute() {}
public List getResults() {
return resultList;
}
public void addResult(Object o) {
resultList.add(o);
}
public void addResult(String s) {
addResult(new Object[] { s } );
}
public void clearResult() {
resultList.clear();
}
public void setStatusCode(int code) {
statusCode = code;
}
public int getStatusCode() {
return statusCode;
}
}
import java.util.*;
import java.io.*;
import java.util.regex.*;
public class FindCommand extends CommandImpl implements Serializable {
public FindCommand() {}
public void execute() {
clearResult();
String regex = (String) getParameter("regex");
String input = (String) getParameter("input");
if (regex == null || input == null) {
setStatusCode(1);
return;
}
Pattern pattern;
try {
pattern = Pattern.compile(regex);
} catch (PatternSyntaxException exc) {
setStatusCode(2);
return;
}
Matcher matcher = pattern.matcher(input);
boolean found = matcher.find();
if (!found) setStatusCode(3);
else {
setStatusCode(0);
do {
addResult( new Object[] { "\"" + matcher.group() + "\"",
new Integer(matcher.start()),
new Integer(matcher.end()-1)
});
} while(matcher.find());
}
}
}
Tę klasę możemy wykorzystać w najprzeróźniejszy sposób. Teraz zastosujemy ją jako element aplikacji WEB. .....
<context-param>
<param-name>presentationServ</param-name>
<param-value>/presentation</param-value>
</context-param>
<context-param>
<param-name>getParamsServ</param-name>
<param-value>/getparams</param-value>
</context-param>
<context-param>
<param-name>commandClassName</param-name>
<param-value>FindCommand</param-value>
</context-param>
.....
i pobierając je przy inicjacji serwletupublic class ControllerServ extends HttpServlet {
private ServletContext context;
private Command command; // obiekt klasy dzialania
private String presentationServ; // nazwa serwlet prezentacji
private String getParamsServ; // mazwa serwletu pobierania parametrów
private Object lock = new Object(); // semafor dla synchronizacji
// odwołań wielu wątków
public void init() {
context = getServletContext();
presentationServ = context.getInitParameter("presentationServ");
getParamsServ = context.getInitParameter("getParamsServ");
String commandClassName = context.getInitParameter("commandClassName");
// Załadowanie klasy Command i utworzenie jej egzemplarza
// który będzie wykonywał pracę
try {
Class commandClass = Class.forName(commandClassName);
command = (Command) commandClass.newInstance();
} catch (Exception exc) {
throw new NoCommandException("Nie mogę stworzyć obiektu klasy " +
commandClassName);
}
}
// ...
Zwróćmy uwagę, że piszemy ten kod w kategoriach interfejsu Command. Dynamicznie
ładujemy klasę podaną jako parametr kontekstu (tu FindCommand) i tworzymy
jej obiekt. Zmiana wykonywanego działania (np. zamiast wyszukiwania jakieś
obliczenia matematyczne) wymaga tylko podania innej wartości parametru kontekstu
commandClassName. Może się okazać, że podamy niewłaściwą nazwę klasy lub
będzie ona źle zbudowana (np. brak konstruktora bezparaemtrowego). Wtedy
- jak już wiemy - wystąpi wyjątek ClassNotFoundException lub InstantiantionException.
Obsługujemy oba te wyjątki poprzez zgłoszenie własnego wyjątku NoComamndException.public class NoCommandException extends RuntimeException {
public NoCommandException() { super(); }
public NoCommandException(String msg) { super(msg); }
}
Jak widać, klasę wyjątku uczyniliśmy pochodną od RunTimeException, dzięki
czemu nie musimy go ani obsługiwać w tym miejscu ani zgłaszać w klauzuli
throws metody init(), co byłoby niedozowolone (bowiem metoda init() w klasie
GenericServlet deklaruje możliwość zgłaszania wyjątku klasy ServletException,
a jej przedefiniowanie nie może tego zmienić). Ten sposób oprogramowania
umożliwia np. przygotowanie strony HTML z komunikatem o przyczynach błędu,
która będzie automatycznie ładowana jeśli użyjemy elementu error-pages w
pliku deskryptora wdrożenia.public class ControllerServ extends HttpServlet {
private ServletContext context;
private Command command; // obiekt klasy wykonawczej
private String presentationServ; // nazwa serwlet prezentacji
private String getParamsServ; // mazwa serwletu pobierania parametrów
private Object lock = new Object(); // semafor dla synchronizacji
// odwołań wielu wątków
public void init() {
context = getServletContext();
presentationServ = context.getInitParameter("presentationServ");
getParamsServ = context.getInitParameter("getParamsServ");
String commandClassName = context.getInitParameter("commandClassName");
// Załadowanie klasy Command i utworzenie jej egzemplarza
// który będzie wykonywał pracę
try {
Class commandClass = Class.forName(commandClassName);
command = (Command) commandClass.newInstance();
} catch (Exception exc) {
throw new NoCommandException("Couldn't find or instantiate " +
commandClassName);
}
}
// Obsługa zleceń
public void serviceRequest(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
resp.setContentType("text/html");
// Wywolanie serwletu pobierania parametrów
RequestDispatcher disp = context.getRequestDispatcher(getParamsServ);
disp.include(req,resp);
// Pobranie bieżącej sesji
// i z jej atrybutów - wartości parametrów
// ustalonych przez servlet pobierania parametrów
// Różne informacje o aplikacji (np. nazwy parametrów)
// są wygodnie dostępne poprzez własną klasę BundleInfo
HttpSession ses = req.getSession();
String[] pnames = BundleInfo.getCommandParamNames();
for (int i=0; i<pnames.length; i++) {
String pval = (String) ses.getAttribute("param_"+pnames[i]);
if (pval == null) return; // jeszcze nie ma parametrów
// Ustalenie tych parametrów dla Command
command.setParameter(pnames[i], pval);
}
// Wykonanie działań definiowanych przez Command
// i pobranie wyników
// Ponieważ do serwletu może naraz odwoływać sie wielu klientów
// (wiele watków) - potrzebna jest synchronizacja
// przy czym rrygiel zamkniemy tutaj, a otworzymy w innym fragmnencie kodu
// - w serwlecie przentacji (cały cykl od wykonania cmd do poazania wyników jest sekcją krytyczną)
Lock mainLock = new ReentrantLock();
mainLock.lock();
// wykonanie
command.execute();
// pobranie wyników
List results = (List) command.getResults();
// Pobranie i zapamiętanie kodu wyniku (dla servletu prezentacji)
ses.setAttribute("StatusCode", new Integer(command.getStatusCode()));
// Wyniki - będą dostępne jako atrybut sesji
ses.setAttribute("Results", results);
ses.setAttribute("Lock", mainLock); // zapiszmy lock, aby mozna go było otworzyć później
// Wywołanie serwletu prezentacji
disp = context.getRequestDispatcher(presentationServ);
disp.forward(req, resp);
}
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
serviceRequest(request, response);
}
public void doPost(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
serviceRequest(request, response);
}
}
Widzimy, że opisuje on wyłącznie logikę działania, bez elementów prezentacji
(drobnym, niestety nieuniknionym wyjątkiem jest ustalenie content-type odpowiedzi
na "text/html"; w przeciwnym razie metoda include RequestDispatchera włączy
źrólo generowanej przez serwlet pobierania parametrów strony, a nie zinterpertowany
HTML). public class RegexParamsDef_pl extends ListResourceBundle {
public Object[][] getContents() {
return contents;
}
static final Object[][] contents = {
{ "charset", "ISO-8859-2" },
{ "header", new String[] { "Testowanie wyrażeń regularnych" } },
{ "param_regex", "Wzorzec:" },
{ "param_input", "Tekst:" },
{ "submit", "Pokaż wyniki wyszukiwania" },
{ "footer", new String[] { } },
{ "resCode", new String[]
{ "Dopasowano", "Brak danych",
"Wadliwy wzorzec", "Nie znaleziono dopasowania" }
},
{ "resDescr",
new String[] { "podłańcuch", "od poz.", "do poz.", "" } },
};
}
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.util.*;
class BundleInfo {
static private String[] commandParamNames;
static private String[] commandParamDescr;
static private String[] statusMsg;
static private String[] headers;
static private String[] footers;
static private String[] resultDescr;
static private String charset;
static private String submitMsg;
static void generateInfo(ResourceBundle rb) {
synchronized (BundleInfo.class) { // konieczne ze względu
// na możliwość odwołań
List cpn = new ArrayList(); // z wielu egzemplarzy serwletów
List cpv = new ArrayList();
Enumeration keys = rb.getKeys();
while (keys.hasMoreElements()) {
String key = (String) keys.nextElement();
if (key.startsWith("param_")) {
cpn.add(key.substring(6));
cpv.add(rb.getString(key));
}
else if (key.equals("header")) headers = rb.getStringArray(key);
else if (key.equals("footer")) footers = rb.getStringArray(key);
else if (key.equals("resCode")) statusMsg = rb.getStringArray(key);
else if (key.equals("resDescr")) resultDescr = rb.getStringArray(key);
else if (key.equals("charset")) charset = rb.getString(key);
else if (key.equals("submit")) submitMsg = rb.getString(key);
}
commandParamNames = (String[]) cpn.toArray(new String[0]);
commandParamDescr = (String[]) cpv.toArray(new String[0]);
}
}
public static String getCharset() {
return charset;
}
public static String getSubmitMsg() {
return submitMsg;
}
public static String[] getCommandParamNames() {
return commandParamNames;
}
public static String[] getCommandParamDescr() {
return commandParamDescr;
}
public static String[] getStatusMsg() {
return statusMsg;
}
public static String[] getHeaders() {
return headers;
}
public static String[] getFooters() {
return footers;
}
public static String[] getResultDescr() {
return resultDescr;
}
}
// Serwlet włączany wyłącznie z serwletu pobierania parametrów
// Ładuje ResourceBundle i przekazuje go klasie BundleInfo,
// która odczytuje info i daje wygodną formę jej pobierania
// w innych serwletach.
// Ładowanie zasobów i ich przygotowanie przez klasę BundleInfo
// następuje tylko raz na sesję.
public class ResourceBundleServ extends HttpServlet {
private String resBundleName;
public void init() {
resBundleName = getServletContext().getInitParameter("resBundleName");
}
public void serviceRequest(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
HttpSession ses = req.getSession();
ResourceBundle paramsRes = (ResourceBundle) ses.getAttribute("resBundle");
// W tej sesji jeszcze nie odczytaliśmy zasobów
if (paramsRes == null) {
Locale loc = req.getLocale();
paramsRes = ResourceBundle.getBundle(resBundleName, loc);
ses.setAttribute("resBundle", paramsRes);
// Przygotowanie zasobów w wygodnej do odczytu formie
BundleInfo.generateInfo(paramsRes);
}
// ... a jeśli sesja się nie zmieniła - to nie mamy nic do roboty
}
//...
}
// SERWLET POBIERANIA PARAMETRÓW
public class GetParamsServ extends HttpServlet {
private ServletContext context;
private String resBundleServ; // nazwa serwletu przygotowującego
// sparametryzowaną informacje
// Inicjacja
public void init() {
context = getServletContext();
resBundleServ = context.getInitParameter("resBundleServ");
}
// Obsługa zleceń
public void serviceRequest(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
// Włączenie serwletu przygotowującego informacje z z zasobów
// (ResourceBundle). Informacja będzie dostępna poprzez
// statyczne metody klasy BundleInfo
RequestDispatcher disp = context.getRequestDispatcher(resBundleServ);
disp.include(req, resp);
// Pobranie potrzebnej informacji
// ktora została wczesniej przygotowana
// przez klasę BundleInfo na podstawie zlokalizowanych zasobów
// Zlokalizowana strona kodowa
String charset = BundleInfo.getCharset();
// Napisy nagłówkowe
String[] headers = BundleInfo.getHeaders();
// Nazwy parametrów (pojawią się w formularzu,
// ale również są to nazwy parametrów dla Command)
String[] pnames = BundleInfo.getCommandParamNames();
// Opisy parametrów - aby było wiadomo co w formularzu wpisywać
String[] pdes = BundleInfo.getCommandParamDescr();
// Napis na przycisku
String submitMsg = BundleInfo.getSubmitMsg();
// Ew. końcowe napisy na stronie
String[] footers = BundleInfo.getFooters();
// Ustalenie właściwego kodowania zlecenia
// - bez tego nie będzie można własciwie odczytać parametrów
req.setCharacterEncoding(charset);
// Pobranie aktualnej sesji
// w jej atrybutach są/będą przechowywane
// wartości parametrów
HttpSession session = req.getSession();
// Generowanie strony
resp.setCharacterEncoding(charset);
PrintWriter out = resp.getWriter();
out.println("<center><h2>");
for (int i=0; i<headers.length; i++)
out.println(headers[i]);
out.println("</center></h2><hr>");
// formularz
out.println("<form method=\"post\">");
for (int i=0; i<pnames.length; i++) {
out.println(pdes[i] + "<br>");
out.print("<input type=\"text\" size=\"30\" name=\"" +
pnames[i] + "\"");
// Jezeli są już wartości parametrów - pokażemy je w formularzu
String pval = (String) session.getAttribute("param_"+pnames[i]);
if (pval != null) out.print(" value=\"" + pval + "\"");
out.println("><br>");
}
out.println("<br><input type=\"submit\" value=\"" + submitMsg + "\">");
out.println("</form>");
// Pobieranie parametrów z formularza
for (int i=0; i<pnames.length; i++) {
String paramVal = req.getParameter(pnames[i]);
// Jeżeli brak parametru (ów) - konczymy
if (paramVal == null) return;
// Jest parametr - zapiszmy jego wartość jako atrybut sesji.
// Zostanie on pobrany przez Controller
// który ustali te wartości dla wykonania Command
session.setAttribute("param_" + pnames[i], paramVal);
}
}
//..metody doGet i doPost - wywołują serviceRequest
}
public class ResultPresent extends HttpServlet {
public void serviceRequest(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
ServletContext context = getServletContext();
// Włączenie strony generowanej przez serwlet pobierania parametrów
// (formularz)
String getParamsServ = context.getInitParameter("getParamsServ");
RequestDispatcher disp = context.getRequestDispatcher(getParamsServ);
disp.include(req,resp);
// Uzyskanie wyników i wyprowadzenie ich
// Controller po wykonaniu Command zapisał w atrybutach sesji
// - referencje do listy wyników jako atrybut "Results"
// - wartośc kodu wyniku wykonania jako atrybut "StatusCode"
HttpSession ses = req.getSession();
Lock mainLock = (Lock) ses.getAttribute("Lock");
mainLock.unlock();
List results = (List) ses.getAttribute("Results");
Integer code = (Integer) ses.getAttribute("StatusCode");
PrintWriter out = resp.getWriter();
out.println("<hr>");
// Uzyskanie napisu właściwego dla danego "statusCode"
String msg = BundleInfo.getStatusMsg()[code.intValue()];
out.println("<h2>" + msg + "</h2>");
// Elementy danych wyjściowych (wyników) mogą być
// poprzedzane jakimiś opisami (zdefiniowanymi w ResourceBundle)
String[] dopiski = BundleInfo.getResultDescr();
// Generujemy raport z wyników
out.println("<ul>");
for (Iterator iter = results.iterator(); iter.hasNext(); ) {
out.println("<li>");
int dlen = dopiski.length; // długość tablicy dopisków
Object res = iter.next();
if (res.getClass().isArray()) { // jezeli element wyniku jest tablicą
Object[] res1 = (Object[]) res;
int i;
for (i=0; i < res1.length; i++) {
String dopisek = (i < dlen ? dopiski[i] + " " : "");
out.print(dopisek + res1[i] + " ");
}
if (dlen > res1.length) out.println(dopiski[i]);
}
else { // może nie być tablicą
if (dlen > 0) out.print(dopiski[0] + " ");
out.print(res);
if (dlen > 1) out.println(" " + dopiski[1]);
}
out.println("</li>");
}
out.println("</ul>");
}
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
serviceRequest(request, response);
}
public void doPost(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
serviceRequest(request, response);
}
}
Uruchamiając tę aplikację uzyskamy znany nam już obraz dzialania (stronę
z formy\ularzem , która po wpisaniu regularnego wyrażenia i przeszukiwanego
tekstu zostanie uzupełniona o listę komunikatów o odnalezionych dopasowaniach).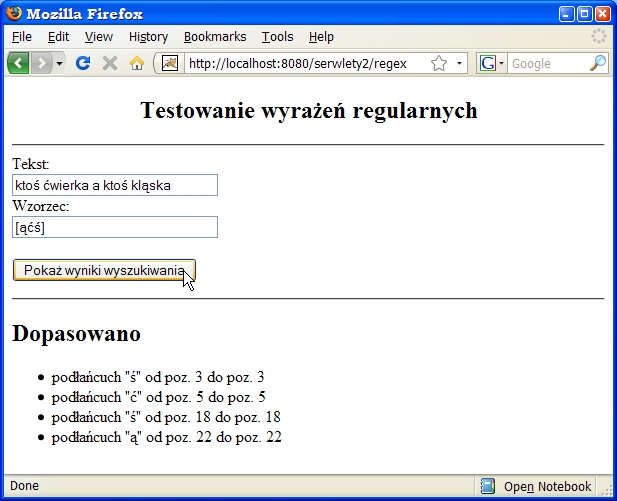
import java.util.*;
public class StringCmdDef_pl extends ListResourceBundle {
public Object[][] getContents() {
return contents;
}
static final Object[][] contents = {
{ "charset", "ISO-8859-2" },
{ "header", new String[] { "Działania na Stringach" } },
{ "param_input1", "Tekst 1:" },
{ "param_input2", "Tekst 2:" },
{ "param_cmd", "Polecenie:" },
{ "submit", "Wykonaj" },
{ "footer", new String[] { } },
{ "resCode", new String[]
{ "Wynik:", "Brak danych",
"Wadliwe polecenie, dostępne: upper, lower, words" }
},
{ "resDescr",
new String[] { "" } },
};
}
import java.io.*;
import java.util.*;
public class StringCommand extends CommandImpl implements Serializable {
public StringCommand() {}
public void execute() {
clearResult();
String input1 = (String) getParameter("input1");
String input2 = (String) getParameter("input2");
String cmd = (String) getParameter("cmd");
if (input1 == null || input2 == null || cmd == null) {
setStatusCode(1);
return;
}
String input = input1 + " " + input2;
setStatusCode(0);
if (cmd.equals("upper")) addResult(input.toUpperCase());
else if (cmd.equals("lower")) addResult(input.toLowerCase());
else if (cmd.equals("words")) {
StringTokenizer st = new StringTokenizer(input);
while (st.hasMoreTokens()) addResult(st.nextToken());
}
else setStatusCode(2);
}
}
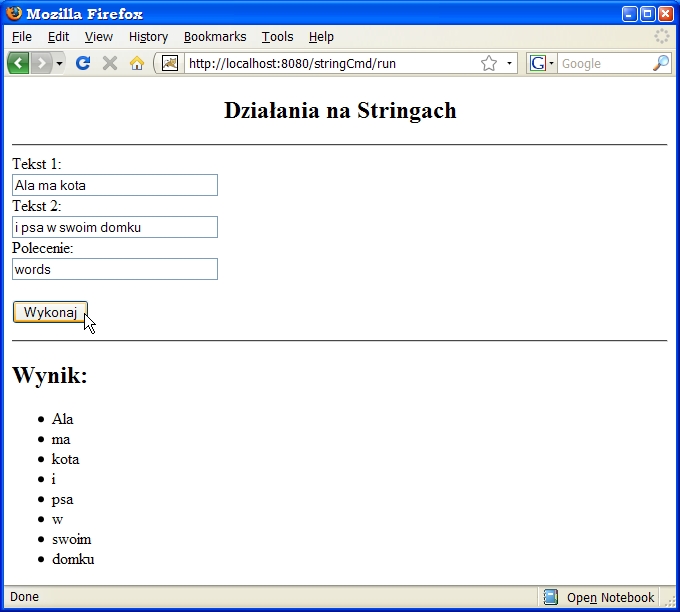
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.util.*;
import java.sql.*;
import javax.sql.*;
public class DbServlet1 extends HttpServlet {
String url = "jdbc:derby://localhost/ksidb";
String uid = "APP";
String pwd = "APP";
Connection con;
public void init() throws ServletException {
try {
con = DriverManager.getConnection(url, uid, pwd); // JDBC 4.0 - dostęp przez SPI
} catch (Exception exc) {
throw new ServletException("Nie ustanowiono połaczenia z bazą", exc);
}
}
public void serviceRequest(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
resp.setContentType("text/html; charset=windows-1250");
PrintWriter out = resp.getWriter();
out.println("<h2>Lista dostępnych książek</h2>");
String sel = "select * from pozycje";
out.println("<ol>");
try {
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(sel);
while (rs.next()) {
String tytul = rs.getString("tytul");
float cena = rs.getFloat("cena");
out.println("<li>" + tytul + " - cena: " + cena + "</li>");
}
rs.close();
stmt.close();
} catch (SQLException exc) {
out.println(exc.getMessage());
}
out.close();
}
public void destroy() {
try {
con.close();
} catch (Exception exc) {}
}
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
serviceRequest(request, response);
}
public void doPost(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
serviceRequest(request, response);
}
}
// Drugie wadliwe rozwiązanie
public void serviceRequest(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
resp.setContentType("text/html; charset=windows-1250");
PrintWriter out = resp.getWriter();
out.println("<h2>Lista dostępnych książek</h2>");
Connection con;
String sel = "select * from pozycje";
try {
con = DriverManager.getConnection(...);
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(sel);
out.println("<ol>");
while (rs.next()) {
String tytul = rs.getString("tytul");
float cena = rs.getFloat("cena");
out.println("<li>" + tytul + " - cena: " + cena + "</li>");
}
rs.close();
stmt.close();
con.close();
} catch (Exception exc) {
out.println(exc.getMessage());
}
out.close();
}
To rozwiązanie jest jednak również niewłaściwe. Nie tylko dlatego, że (tak
jak poprzednio) zawiera statycznie zapisane w kodzie nazwy zasobów i nie
przestrzega reguł architektury MVC (z tym umiemy sobie już radzić), ale przede
wszystkim dlatego, że jest niefektywne i nieskalowalne. Uzyskanie połączenia
z bazą danych jest bowiem operacją relatywnie kosztowną czasowo, zatem przy
dużej, rosnącej liczbie zleceń ta aplikacja będzie znacząco tracić na efektywności
działania.<Context path="/db" docBase="E:/Programming/webaps/SERWLETY/db/build">
<Resource name="jdbc/ksidb" auth="Container"
type="javax.sql.DataSource"
description="Baza danych ksiazek"
driverClassName="org.apache.derby.jdbc.ClientDriver"
url="jdbc:derby://localhost/ksidb"
username="APP"
password="APP"
maxActive="20" />
</Context>
Dostęp do żródła danych z poziomu aplikacji uzyskujemy za pomocą JNDI (java naming and directory interface). Context init = new InitialContext();
Context contx = (Context) init.lookup("java:comp/env");
DataSource dataSource = (DataSource) contx.lookup("jdbc/ksidb");
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.util.*;
import javax.naming.*;
import java.sql.*;
import javax.sql.*;
public class DbServlet3 extends HttpServlet {
DataSource dataSource; // źrodło danych
public void init() throws ServletException {
try {
Context init = new InitialContext();
Context contx = (Context) init.lookup("java:comp/env");
dataSource = (DataSource) contx.lookup("jdbc/ksidb");
} catch (NamingException exc) {
throw new ServletException(
"Nie mogę uzyskać źródła java:comp/env/jdbc/ksidb", exc);
}
}
public void serviceRequest(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
resp.setContentType("text/html; charset=windows-1250");
PrintWriter out = resp.getWriter();
out.println("<h2>Lista dostępnych książek</h2>");
Connection con = null;
try {
synchronized (dataSource) {
con = dataSource.getConnection();
}
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery("select * from pozycje");
out.println("<ol>");
while (rs.next()) {
String tytul = rs.getString("tytul");
float cena = rs.getFloat("cena");
out.println("<li>" + tytul + " - cena: " + cena + "</li>");
}
rs.close();
stmt.close();
} catch (Exception exc) {
out.println(exc.getMessage());
} finally {
try { con.close(); } catch (Exception exc) {}
}
out.close();
}
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
serviceRequest(request, response);
}
public void doPost(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
serviceRequest(request, response);
}
}
W powyższym kodzie zwróćmy uwagę na potrzebę synchronizacji: obiekt DataSource
może być wspóldzielony przez wiele wątków, zatem musimy synchroniziwać odwołania
do niego.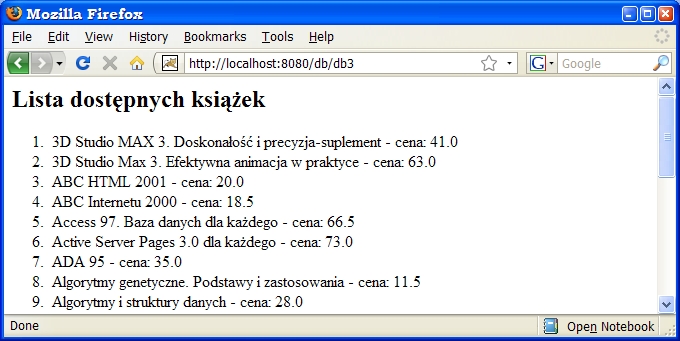
import java.io.*;
import java.util.*;
import javax.naming.*;
import java.sql.*;
import javax.sql.*;
public class DbAccess extends CommandImpl {
private DataSource dataSource;
public void init() {
try {
Context init = new InitialContext();
Context jndiCtx = (Context) init.lookup("java:comp/env");
String dbName = (String) getParameter("dbName");
dataSource = (DataSource) jndiCtx.lookup(dbName);
} catch (NamingException exc) {
setStatusCode(1);
}
}
public void execute() {
clearResult();
setStatusCode(0);
Connection con = null;
try {
synchronized(this) {
con = dataSource.getConnection();
}
Statement stmt = con.createStatement();
String cmd = (String) getParameter("command");
if (cmd.startsWith("select")) {
ResultSet rs = stmt.executeQuery(cmd);
// Będziemy zapisywać wynik jako skonkatenowane
// wartości z kolumn ResultSetu
// Oczywiście, w różnych kwerendach będą różne kolumny
// zatem korzystamy z ResultSetMetaData, by do nich dotrzeć
ResultSetMetaData rsmd = rs.getMetaData();
int cols = rsmd.getColumnCount();
while (rs.next()) {
String wynik = "";
for (int i=1; i<=cols; i++)
wynik += rs.getObject(i) + " ";
addResult(wynik);
}
rs.close();
}
else if (cmd.startsWith("insert")) {
int upd = stmt.executeUpdate(cmd);
addResult("Dopisano " + upd + " rekordów");
}
else setStatusCode(3);
} catch (SQLException exc) {
setStatusCode(2);
throw new DbAccessException("Błąd w dostępie do bazy lub w SQL", exc);
} finally {
try {
con.close();
} catch (Exception exc) {}
}
}
}
Serwlet-kontroler w znany nam już sposób odczytuje wyniki i przekazuje
do prezentacji. Ze względu na naturę dostępu przez DataSource musieliśmy
jednak poczynić drobną zmianę w metodzie inicjacji serwletu-kontrolera, a
mianowicie - ustalić nazwę bazy danych (pobraną z parametrów kontekstu) jako
parametr dla klasy działania i zainicjować jej obiekt. Te dodatki są na poniższym
wydruku zaznaczone pogrubionym tekstem..import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.util.*;
import java.text.*;
public class ControllerServ extends HttpServlet {
private ServletContext context;
private Command command; // obiekt klasy dzialania (wykonawczej)
private String presentationServ; // nazwa serwlet prezentacji
private String getParamsServ; // mazwa serwletu pobierania parametrów
public void init() {
context = getServletContext();
presentationServ = context.getInitParameter("presentationServ");
getParamsServ = context.getInitParameter("getParamsServ");
String commandClassName = context.getInitParameter("commandClassName");
String dbName = context.getInitParameter("dbName");
// Załadowanie klasy Command i utworzenie jej egzemplarza
// który będzie wykonywał pracę
try {
Class commandClass = Class.forName(commandClassName);
command = (Command) commandClass.newInstance();
// ustalamy, na jakiej bazie ma działać Command i inicjujemy obiekt
command.setParameter("dbName", dbName);
command.init();
} catch (Exception exc) {
throw new NoCommandException("Couldn't find or instantiate " +
commandClassName);
}
}
// ... dalej znany już kod obsługi zleceń
Przygotujemy oczywiście zasoby definicyjne:import java.util.*;
public class DbAccessDef_pl extends ListResourceBundle {
public Object[][] getContents() {
return contents;
}
static final Object[][] contents = {
{ "charset", "ISO-8859-2" },
{ "header", new String[] { "Baza danych książek" } },
{ "param_command", "Polecenie (select lub insert):" },
{ "submit", "Wykonaj" },
{ "footer", new String[] { } },
{ "resCode", new String[]
{ "Wynik:", "Brak bazy", "Błąd SQL",
"Wadliwe polecenie; musi zaczynać się od select lub insert" }
},
{ "resDescr",
new String[] { "" } },
};
}
a w serwletach pobierania parametrów i prezentacji zmienimy szerokość
pola tekstowego oraz rodzaj listy (niech teraz będzie numerowana). W sumie
10 minut pracy i mamy dość uniwersalną i elastyczną aplikaację bazodanową
(zob. rys).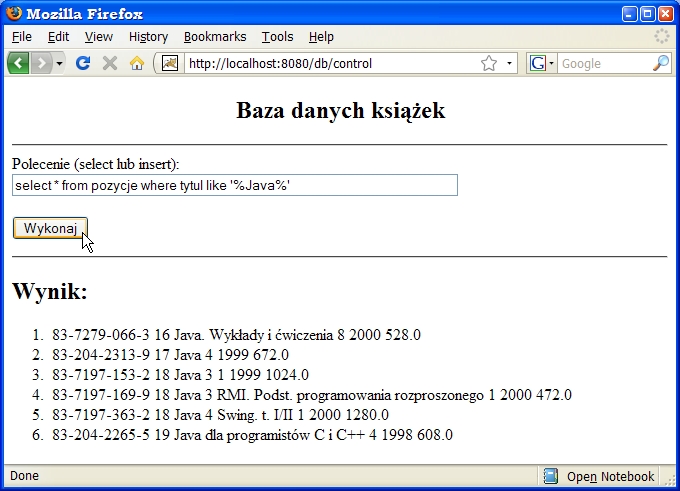
public class DbAccessException extends RuntimeException {
public DbAccessException(String msg, Throwable cause) {
super(msg, cause);
}
}
Wyjątki tej klasy będziemy zgłaszać w reakcji na wystąpienie wyjątku SQLException,
przy czym zastosujemy łańcuchowanie wyjątków: przyczyna powstania naszego
wyjątku - czyli wyjątek SQLExecption zostanie dowiązany do naszego wyjątku: public void execute() {
//....
try {
// łączenie z bazą i operacje na niej
// ...
} catch (SQLException exc) {
setStatusCode(2);
throw new DbAccessException("Błąd w dostępie do bazy lub w SQL", exc);
} finally {
try {
con.close();
} catch (Exception exc) {}
}
}
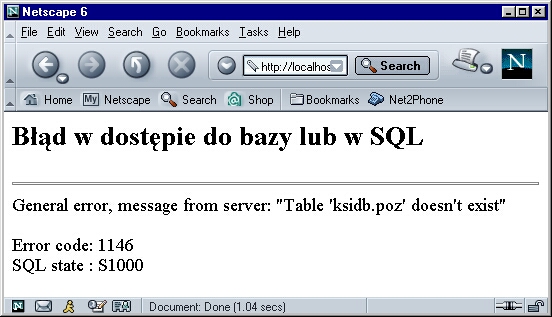
Zatem oprócz enigmatycznego "statusCode" 2 ( opisanego jako "Błąd w SQL")
mamy zgłoszony wyjątek, precyzyjnie opisujący przyczyny błędu. Ale jak go
obsłużyć? Przecież serwlet-kontroler, który wywołuje execute(...) nie będzie
zajmował się prezentacją opisów błędów.| javax.servlet.error.message | Komunikat o błędzie (String) |
| javax.servlet.error.servlet_name | Nazwa serwletu, w którym powstał bład |
| javax.servlet.error.exception_type | Klasa wyjątku (Class) |
| javax.servlet.error.exception | Obiekt wyjątku (ogólnie klasy Throwable) |
public class ErrorHandler extends HttpServlet {
public void serviceRequest(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
String charset = BundleInfo.getCharset();
resp.setContentType("text/html; charset=" + charset);
Throwable exc = (Throwable)
req.getAttribute("javax.servlet.error.exception");
if (exc != null) {
PrintWriter out = resp.getWriter();
out.println("<h2>" + exc.getMessage() + "</h2><hr>");
Throwable cause = exc.getCause();
if (cause instanceof SQLException) {
SQLException sqlexc = (SQLException) cause;
out.println(sqlexc.getMessage() + "<br><br>");
out.println("Error code: " + sqlexc.getErrorCode() + "<br>");
out.println("SQL state : " + sqlexc.getSQLState() + "<br>");
}
out.close();
}
}
//... metody doGet i doPost wołają serviceRequest
a w deskryptorze wdrożenia zaznaczmy, że to właśnie on powinien otrzymać
sterowanie, gdy wystąpi nasz wyjątek DbAccessException: // ...
<servlet>
<servlet-name>ErrorHandler</servlet-name>
<servlet-class>ErrorHandler</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>ErrorHandler</servlet-name>
<url-pattern>/errorhandler</url-pattern>
</servlet-mapping>
<error-page>
<exception-type>DbAccessException</exception-type>
<location>/errorhandler</location>
</error-page>
//..
public class CookieAndSess extends HttpServlet {
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
resp.setContentType("text/html");
PrintWriter out = resp.getWriter();
Cookie[] cookies = req.getCookies();
Cookie countCookie = null;
HttpSession session = null;
if (cookies != null) {
for (int i=0; i<cookies.length; i++) {
String name = cookies[i].getName();
String value = cookies[i].getValue();
out.println("<br>" + name + " " + value);
if (name.equals("count")) {
countCookie = cookies[i];
int count = Integer.parseInt(countCookie.getValue()) + 1;
countCookie.setValue(String.valueOf(count));
if (count > 3) session = req.getSession();
}
}
}
if (session != null) {
out.println("<hr>");
out.println("Sesja: " + session.getId());
}
if (countCookie == null) countCookie = new Cookie("count", "1");
resp.addCookie(countCookie);
out.close();
}
}
Przy trzecim polączeniu tworzona jest sesja (metoda getSession() tworzy sesje,
jeśli jeszcze nie została utworzona) i od tego momentu widzimy, że wraz
z naszym cookie-licznikiem przychodzi też cookie (o nazwie JSESSIONID) z
identyfikatorem sesji: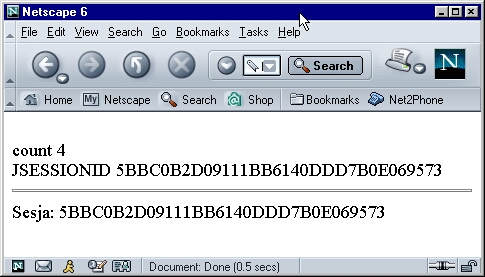
Zdarzenie | Klasa zdarzenia | Interfejs obsługi | Metody obsługi |
| inicjacja i usuwanie kontekstu aplikacji | ServletContextEvent | ServletContextListener | contextInitialized contextDestroyed |
| zapis, zmiana i usuwanie atrybutów kontekstu | ServletContextAttributeEvent | ServletContextAtrributeListener | attributeAdded attributeRemoved attributeReplaced |
| inicjacja i zakończenie obsługi zlecenia | ServletRequestEvent | ServletRequestListener | requestInitialized requestDestroyed |
| zapis, zmiana i usuwanie atrybutów zlecenia | ServletRequestAttributeEvent | ServletRequestAttributeListener | atrributeAdded attributeRemoved attributeReplaced |
| utworzenie i zamknięcie sesji | HttpSessionEvent | HttpSestionActivationListener | sessionCreated sessionDestroyed |
| aktywacja i pasywacja sesji | HttpSessionEvent | HttpSestionActivationListener | sessionDidActive sessionWillPassivated |
| zapis, zmiana i usuwanie atrybutów sesji | HttpSessionBindingEvent | HttpSessionAttributeListener | attributeAdded attributeRemoved attributeReplaced |
| zmiana dowiązania obiektu do sesji | HttpSessionBindingEvent | HttpSessionBindingListener | valueBound valueUnbound |
<listener>
<listener-class>[nazwa_pakietu.]nazwa_klasy_słuchacza</listener-class>
</listener>
Można również definiować słuchaczy w deskryptorze kontekstu, dodając element Listener:<Context path="/jakas" ...> ... <Listener className="[nazwa_pakietu.]nazwa_klasy_słuchacza" ... > ... </Context>W tym elemencie można umieścić dodatkowe definicje właściwości JavaBeans (oczywiście klasa słuchacza musi spełniać protokół JavaBeans), podając nazwy właściwości i ich wartości.
package listeners;
import java.util.*;
public class Report {
private static List rep = new ArrayList();
public static void add(String s) {
rep.add(s);
}
public static List get() { return rep; }
}
package listeners;
import javax.servlet.*;
public class TestContextListener implements ServletContextListener{
public void contextInitialized(ServletContextEvent p0) {
Report.add("Kontekst utworzony");
ServletContext context = p0.getServletContext();
context.setAttribute("Liczba", new Integer(1));
}
public void contextDestroyed(ServletContextEvent p0) {
}
}
import javax.servlet.*;
public class TestContextAttributeListener implements ServletContextAttributeListener{
public void attributeAdded(ServletContextAttributeEvent p0) {
Report.add("Do kontekstu dodano atrybut " + p0.getName() +
" = " + p0.getValue());
}
public void attributeRemoved(ServletContextAttributeEvent p0) {
Report.add("Z kontekstu usunięto atrybut " + p0.getName() +
" = " + p0.getValue());
}
public void attributeReplaced(ServletContextAttributeEvent p0) {
Report.add("W kontekście zmieniono atrybut " + p0.getName() +
" = " + p0.getValue());
}
}
package listeners;
import javax.servlet.http.*;
public class TestSesAttrListener implements HttpSessionAttributeListener{
public void attributeAdded(HttpSessionBindingEvent p0) {
Report.add("Do sesji dodany atrybut " + p0.getName() + " = " + p0.getValue());
}
public void attributeRemoved(HttpSessionBindingEvent p0) {
Report.add("Z sesji usunięty atrybut " + p0.getName() + " = " + p0.getValue());
}
public void attributeReplaced(HttpSessionBindingEvent p0) {
Report.add("Zmieniony sesji atrybut " + p0.getName() + " = " + p0.getValue());
}
}
Zauważmy, że od przekazanych zdarzeń, za pomoca metod ich klas uzyskujemy niezbędne informacje:<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.4"
xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee web-app_2_4.xsd">
<display-name>Adds</display-name>
<description>Dodatkowi słuchacze</description>
<listener>
<listener-class>listeners.TestContextListener</listener-class>
</listener>
<listener>
<listener-class>listeners.TestContextAttributeListener</listener-class>
</listener>
<listener>
<listener-class>listeners.TestSesAttrListener</listener-class>
</listener>
<servlet>
<servlet-name>ListenersTest</servlet-name>
<description></description>
<servlet-class>ListenersTest</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>ListenersTest</servlet-name>
<url-pattern>/listen</url-pattern>
</servlet-mapping>
</web-app>
Zdefiniowany w deskryptorze serwlet ListenersTest służy do testowania w/w
słuchaczy (jego kod zobaczymy za chwilę). Oprócz testowania działania wyżej
wymienionych słuchaczy zilustrujemy też ciekawą właściwość: obiekty klas
implementujących interfejs HttpSessionBindingListener uzyskują swoistą samowiedzę
o tym kiedy są ustalane jako atrybuty sesji i kiedy są - jako atrybuty -
z sesji usuwane. Takie "świadome" obiekty stają się słuchaczami własnego
losu (jako atrybutów sesji).package listeners;
import javax.servlet.http.*;
public class SwiadomyAtrybut implements HttpSessionBindingListener{
private String val;
public SwiadomyAtrybut(String val) {
this.val = val;
}
public void valueBound(HttpSessionBindingEvent p0) {
Report.add("Jestem \"świadomym\" atrybutem " +
p0.getName() + " i wiem, że własnie zostałem dodany do sesji");
}
public void valueUnbound(HttpSessionBindingEvent p0) {
Report.add("Jestem \"świadomym\" atrybutem " +
p0.getName() + " i wiem, że własnie zostałem usunięty z sesji");
}
public String toString() { return val; }
}
Obiekt klasy SwiadomyAtrybut będzie dopisywał do listy raportowej (klasa
Report) komunikaty o tym, że został ustalony jako atrybut sesji (gdy wystąpi
takie zdarzenie), jak również informację o swoim usunięciu z atrybutów sesji.<form> <p><input type="submit" name="setsesatt1" value="Normalny atrybut sesji (set)" style="background: white"> <p><input type="submit" name="remsesatt1" value="Usu˝ normalny atrybut sesji " style="background: white"> <p><input type="submit" name="setsesatt2" value="îwiadomy atrybut sesji (set)" style="background: white"> <p><input type="submit" name="remsesatt2" value="Usu˝ ťwiadomy atrybut sesji" style="background: white"> <p><input type="submit" name="chgatt" value="Zmien atrybut kontekstu" style="background: white"> </form>a jego włączenie (za pomocą include z klasy RequestDispatcher) wyświetli:
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.util.*;
import listeners.Report;
import listeners.SwiadomyAtrybut;
public class ListenersTest extends HttpServlet {
static int count = 0; // dla zmian "Liczby" - atrybutu kontekstu
SwiadomyAtrybut sa = new SwiadomyAtrybut(
"jestem atrybutem, co wie kiedy go dodają lub usuwają"
);
public void init() {
Report.add("Inicjacja serwletu");
}
public void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
resp.setContentType("text/html; charset=windows-1250");
PrintWriter out = resp.getWriter();
out.println("<center><h2>Testowanie słuchaczy</h2></center>");
req.getRequestDispatcher("form.html").include(req,resp);
HttpSession ses = req.getSession();
if (req.getParameter("setsesatt1") != null) {
Report.add("<b><i>--- wybrano 'Normalny atrybut sesji (set)'</b></i>");
ses.setAttribute("atr_ses1", "jestem zwykłym atrybutem sesji");
}
else if (req.getParameter("remsesatt1") != null) {
Report.add("<b><i>--- wybrano 'Usuń normalny atrybut sesji'</b></i>");
ses.removeAttribute("atr_ses1");
}
else if (req.getParameter("setsesatt2") != null) {
Report.add("<b><i>--- wybrano 'Świadomy atrybut sesji (set)'</b></i>");
ses.setAttribute("atr_ses2", sa);
}
else if (req.getParameter("remsesatt2") != null) {
Report.add("<b><i>--- wybrano 'Usuń świadomy atrybut sesji'</b></i>");
ses.removeAttribute("atr_ses2");
}
else if (req.getParameter("chgatt") != null) {
count++;
if (count > 1) {
Report.add("<b><i>--- wybrano 'Zmień atrybut kontekstu'</b></i>");
getServletContext().setAttribute("Liczba", new Integer(count));
}
}
out.println("<hr>");
out.println("<u>Co się działo ?</u>");
List list = Report.get();
out.println("<ol>");
for (Iterator it = list.iterator(); it.hasNext(); ) {
out.println("<li>" + it.next() + "</li>");
}
out.println("</ol>");
out.close();
}
}
Gdy serwer tworzy obiekt-serwlet tworzony jest jednocześnie obiekt SwiadomyAtrybut (bo zapisaliśmy to w definicji pola sa
klasy serwletu). Okazuje się, że to wystarcza (bez podawania definicji tego
słuchacza w deskryptorze wdrożenia) do obsługi przez HttpSessionBindingListener
(którym jest nasz SwiadomyAtrybut) przytrafiających mu się zdarzeń HttpBindingEvent.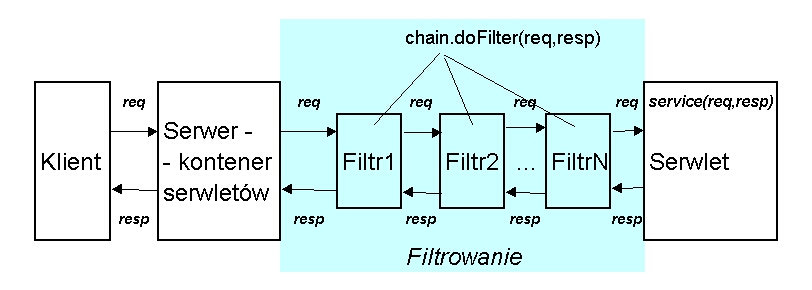
package filters;
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
import java.util.*;
public class TestFilter implements Filter{
private static int ind = 0; // indeks ogłoszenia
// szablon ogłoszenia
private String szablon =
"<table cellpadding=\"2\" cellspacing=\"2\" border=\"1\" width=\"100%\">"+
"<tbody><tr><td valign=\"Top\" bgcolor=\"#000099\">" +
"<div align=\"Center\"><font color=\"#ffffff\">@</font></div></td>"+
"</tr></tbody></table>";
// Lista ogłoszeń
private List oglosz = new ArrayList();
// Tablica kodowań dla różnych "locale"
private Properties encodings = new Properties();
public void init(FilterConfig fc) throws ServletException {
ServletContext sc = fc.getServletContext();
// Strumień dla tablicy kodowań
InputStream props = sc.getResourceAsStream("WEB-INF/encodings.properties");
try {
// załadowanie tablicy kodowań
if (props != null) encodings.load(props);
// Plik z ogłoszeniami
InputStream is = sc.getResourceAsStream("WEB-INF/ogloszenia.txt");
BufferedReader br = new BufferedReader(
new InputStreamReader(is)
);
String line;
while ((line = br.readLine()) != null) oglosz.add(line);
br.close();
} catch (Exception exc) { oglosz.add("Witamy!"); }
}
public void doFilter(ServletRequest req, ServletResponse resp,
FilterChain chain)
throws IOException,ServletException
{
// Ustalenie kolejnego ogłoszenia
String msg;
synchronized(this) {
msg = szablon.replaceFirst("@", (String) oglosz.get(ind));
if (ind < oglosz.size() - 1) ind++;
else ind = 0;
}
// Ustalenie kodowania
Locale locale = req.getLocale();
String charset = (String) encodings.get(locale);
if (charset == null) charset = "windows-1250";
resp.setContentType("text/html; charset=" + charset);
// Generacja początku strony
PrintWriter out = ((HttpServletResponse) resp).getWriter();
out.println(msg);
// Wywołanie następnego elementu FilterChain
// zwykle już bezpośrednio serwletu
chain.doFilter(req, resp);
}
public void destroy() {
}
}
Uwagi: <filter>
<filter-name>HeaderFilter</filter-name>
<filter-class>filters.TestFilter</filter-class>
</filter>
Następnie powinniśmy pwoiedzieć jakich kompoentów dotyczy filtrowanie. Możemy
specyfikować konkretne odwołania do konkretnego serwletu lub strony JSP,
grup serwletów lub stron itp. Np. jeśli chcemy, by fiktowanie dotyczyło serwletu,
który wywołujemy za pomocą odniesienia go, napiszemy: <filter-mapping>
<filter-name>HeaderFilter</filter-name>
<url-pattern>/go</url-pattern>
</filter-mapping>
Możemy dodać dowolną liczbę mapowań, np. oprócz serwletu go, również interakcja z serwletem run ma podlegać filtrowaniu: <filter-mapping>
<filter-name>HeaderFilter</filter-name>
<url-pattern>/go</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>HeaderFilter</filter-name>
<url-pattern>/run</url-pattern>
</filter-mapping>
<filter>
<filter-name>HeaderFilter</filter-name>
<filter-class>filters.TestFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>HeaderFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
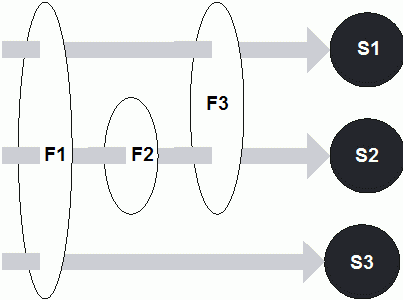
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.4"
xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee web-app_2_4.xsd">
<display-name>Adds</display-name>
<description>Dodatkowe</description>
<filter>
<filter-name>HeaderFilter</filter-name>
<filter-class>filters.TestFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>HeaderFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<listener>
<listener-class>listeners.TestContextListener</listener-class>
</listener>
<listener>
<listener-class>listeners.TestContextAttributeListener</listener-class>
</listener>
<listener>
<listener-class>listeners.TestSessionListener</listener-class>
</listener>
<listener>
<listener-class>listeners.TestSesAttrListener</listener-class>
</listener>
<servlet>
<servlet-name>CookieAndSess</servlet-name>
<description></description>
<servlet-class>CookieAndSess</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>CookieAndSess</servlet-name>
<url-pattern>/cook</url-pattern>
</servlet-mapping>
<servlet>
<servlet-name>ListenersTest</servlet-name>
<description></description>
<servlet-class>ListenersTest</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>ListenersTest</servlet-name>
<url-pattern>/listen</url-pattern>
</servlet-mapping>
</web-app>
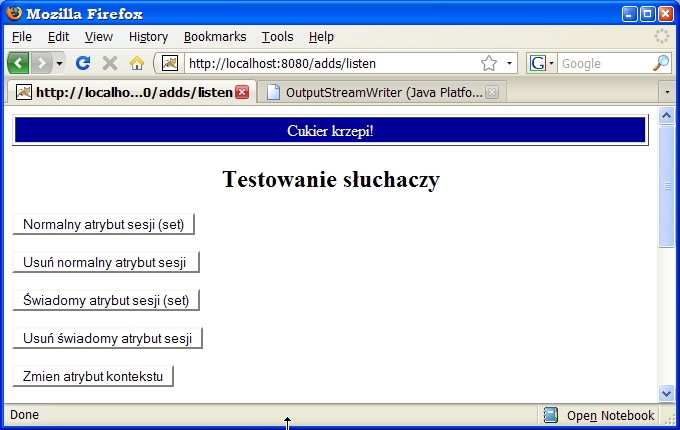
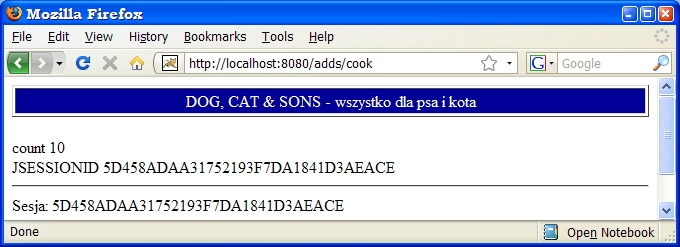
package filters;
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
public class StringResponseWrapper extends HttpServletResponseWrapper {
// Strumien do którego będą pisane odpowiedzi
private StringWriter stringWriter = null;
public StringResponseWrapper(HttpServletResponse response) {
super(response);
}
// Przedefiniowanie metody getWriter()
// każdy kto ejj użyje - otrzyma nasz strumień StringWriter
// i nic o tym nie wiedząc będzie pisał do niego
// a nie do strumienia
// związanego z oryginalnym obiektem HttpServletResponse
public PrintWriter getWriter() throws IOException {
if (stringWriter == null) stringWriter = new StringWriter();
return new PrintWriter(stringWriter);
}
// Nie jesteśmy przygotowani na obsługę strumieni binarnych
// - wykluczamy ich zastosowanie (chociaż nie musimy tego robić)
public ServletOutputStream getOutputStream() throws IOException {
throw new IllegalStateException(
"getOutputStream() not allowed for StringResponseWrapper"
);
}
// Nasza własna metoda, pozwlająca uzyskać dostęp do strumioenia
// i do jego zawartości
public StringWriter getStringWriter() {
return stringWriter;
}
}
Komentarze w kodzie szczehółowo wyjaśniają jego działanie. Zwróćmy jeszcze
tylko uwagę, że tworzymy strumień wyjściowy "w sposób leniew" - czyli tylko
wtedy, gdy naprawdę komuś będzie potrzebny (gdy użyje metody getWriter()).import javax.servlet.*;
import javax.servlet.http.*;
public class FooterFilter implements Filter{
public void init(FilterConfig p0) throws ServletException {
}
public void doFilter(ServletRequest req, ServletResponse resp,
FilterChain chain) throws IOException,ServletException {
Locale locale = req.getLocale();
StringResponseWrapper newResp = new StringResponseWrapper(
(HttpServletResponse) resp
);
chain.doFilter(req, newResp);
StringWriter sw = newResp.getStringWriter();
// Uzyskujemy treść wygenrowanej odpowiedzi
String cont = sw.toString();
// Teraz możemy zrobić cokolwiek z odpowiedzią
// tu tylko dopiszemy do niej "stopkę"
// Bierzemy strumień oryginalnej odpowiedzi
PrintWriter out = resp.getWriter();
// Przepisujemy otrzymaną odpowiedź
out.println(cont);
// Dopisujemy stopkę
DateFormat df = DateFormat.getDateTimeInstance(DateFormat.LONG,
DateFormat.MEDIUM,
locale);
out.println("<hr><i><b>" + df.format(new Date()) + "</i></b>");
out.close();
}
public void destroy() {
}
}
W tym fragmencie kodu (też objaśnionym przez komentarze) należy zwrócić uwage
na konieczność wykonania konwersji: konstruktor klasy HttpResponseWrapper,
a w konsekwencji i naszej klasy StringResponseWrapper, ma parametr typu HttpServletResponse.
Tymczasem metoda doFilter otrzymuje argument ogólniejszego typu ServletResponse.
Dlatego musieliśmy napisać: <filter>
<filter-name>HeaderFilter</filter-name>
<filter-class>filters.TestFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>HeaderFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<filter>
<filter-name>FooterFilter</filter-name>
<filter-class>filters.FooterFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>FooterFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
Po reinstalacji aplikacji wszystkie zlecenia-odpowiedzi do wszystkich jej komponentów będą filtrowane przez oba filtry: generujący nagłówek i generujący stopkę.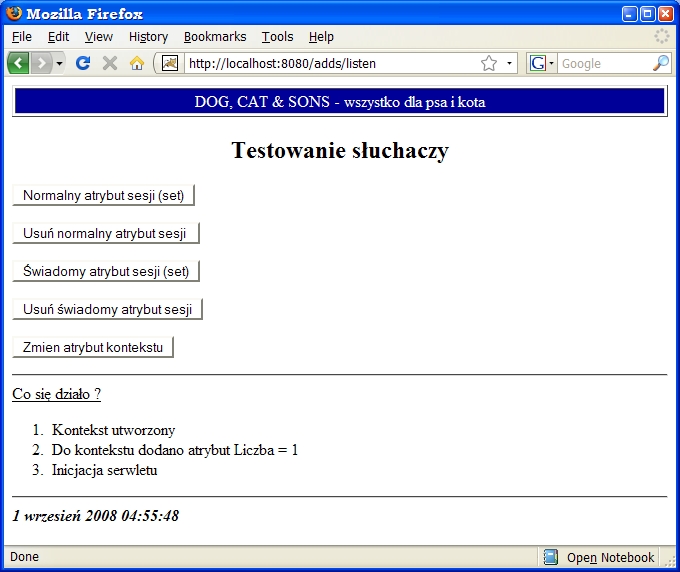
Obszar
|
Funkcjonalność
|
Prefiks
|
|---|---|---|
Core
| Operacje na zmiennych
| c |
Instrukcje sterujące
| ||
Zarządzanie URLami
| ||
Różne
| ||
XML
|
Podstawowe przetwarzanie
| x |
Sterowanie
| ||
Transformacje
| ||
I18n
|
Locale
| fmt |
Formatowanie komunikatow
| ||
Formatowanie liczb i dat
| ||
Database
|
SQL
| sql |
Functions
|
Długość kolekcji
| fn |
Manipulacje na Stringach
|
Np. gdy chcemy użyć bazowych znaczników (Core) piszemy:
<%@ taglib uri="Rozważmy prosty przykład, które pokazują stosunkowo nowe elementy JSP czyli zarówno język wyrażeń EL (wprowadzony w wersji JSP 2.0), jak i zastosowanie JSTL oraz wlasnej (niestandardowej) biblioteki znaczników.http://java.sun.com/jsp/jstl/core"
prefix="c" %>
<%--
Znacznik wpisujący podany jako atrybut msg tekst
poprzedzony jakąś (nieobowiązkową) informacją
--%>
<%@ attribute name="pre" required="false"%>
<%@ attribute name="info" required="true"%>
<h2>${pre}<br>${info}</h2>
Jak widać znacznik ten po prostu wpisuje "w strone" tekst pobrany z atrybutów.<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %> <%@ taglib uri="http://java.sun.com/jsp/jstl/functions" prefix="fn" %> <%@ taglib tagdir="/WEB-INF/tags" prefix="m" %>Dalsza część strony JSP tradycyjnie przeplata kod HTML z "dynamicznymi " znacznikami JSP (wszystko razem zapiszemy w pliku dialog.jsp).
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=windows-1250">
<title>Test</title>
</head>
<c:set var="fmsg" value="Wprowadź informację" />
<c:set var="preinfo" value="Wprowadziłeś:" />
<h2>Aplikacja testowa<br>${fmsg}</h2>
<form>
<input type="text" name="info" size="50">
<p></p>
<input type="submit" value="Submit">
<input type="reset" value="Reset">
</form>
<c:if test="${fn:length(param.info) > 0}" >
<m:msg pre="${preinfo}" info="${param.info}"/>
</c:if>
</body>
</html>
Komentarze: <servlet>
<display-name>dialog</display-name>
<servlet-name>dialog</servlet-name>
<jsp-file>/dialog.jsp</jsp-file>
</servlet>
I dalej, możemy dokonać dowolnego mapowania tej strony JSP na odwołanie do niej. <servlet-mapping>
<servlet-name>dialog</servlet-name>
<url-pattern>/first</url-pattern>
</servlet-mapping>
Ale to nie wszystko. Musimy jeszcze zapewnić odnalezienie bibliotek znaczników (jeśli ich używamy).