5. Programowanie klient-serwer z użyciem gniazd i protokołów sieciowych
5.1. Architektura klient-serwer i sieć.
Architektura klient-serwer jest technologią budowy systemów informatycznych,
polegającą na podziale systemu na współdziałające ze sobą dwie kategorie
programów lub procesów: klientów i serwerów.
Klient to program lub proces, który - oprócz wykonywania swoistych dla
niego działań - łączy się z innym programem lub procesem, zwanym serwerem
i poprzez kanały komunikacyjne zleca mu wykonanie określonych działań; w
szczególności dostarczenia jakichś danych lub wyników przetwarzania danych
Serwer jest programem lub procesem, który - na zlecenie klientów - świadczy
określone usługi - np. dostarcza im dane lub wyniki przetwarzania jakichś
danych
Pojęcie "klient-serwer" jest natury software'owej,
a nie hardware'owej.
Mechanizmy IPC (semafory, potoki, dzielone obszary pamięci) - różne implementacje.
Środowiska rozproszone: - możliwość podziału pracy pomiędzy różnymi maszynami odpowiednio do ich potencjału i efektywności,
- możliwość uzyskiwania usług serwera na odległość,
- dane mogą być prowadzone w sposób scentralizowany (na serwerze) co zapewnia spójność i bezpieczeństwo,
- mogą też być przechowywane w sposób rozproszony pomiędzy róznymi loakalizacjami
geograficznymi (różnymi serwerami i/lub klientami w różnych miejscach), co
zmniejsza ryzyko utraty danych przy awariach.
Wraz z rozpowszechnieniem środowisk rozproszonych (sieci) pojawiła się potrzeba
swoistej unifikacji mechanizmów IPC, tak by mogły być stosowane w jednolity
sposób do komunikacji klientów i serwerów działających na dowolnych komputerach
w sieci (również na jednym i tym samym komputerze).
Oczywiście, komunikacja wymaga przestrzegania pewnych reguł. Reguły te są definiowane przez protokoły.
Protokół - to swoisty język i zasady za pomocą których komunikują się programy i procesy, w szczególności serwery i klienci
Protokoły interakcji sieciowej są podzielone na warstwy, które wyznaczają
poziomy komunikacji. Dzięki temu złożony problem interakcji sieciowej jest
podzielony na podproblemy, za rozwiązywanie których odpowiadają protokoły
poszczególnych warstw.
Ogólny standard tego podziału tzw. model ISO-OSI (OSI -Open Standards Interconnect).
Model OSI składa się z siedmiu warstw:
- aplikacje, działające na dwóch komputerachw sieci (klient i serwer) wymieniają dane.
- kolejne protokoły w kolejnych warstwach dodają
nagłówki do danych otrzymywanycyh z warstwy powyżej. Dane opakowane w nagłówki
są transmitowane w tzw. Protocol
Data Units (PDUs).
- PDU są przesyłane w dół sekwencji warstw i transmitowane
fizycznie przez warstwę fizyczną, która reprezentuje fizyczne połączenie
w sieci.
- Dane otrzymane są przesyłane "w górę" warstw i "odpakowywane" z kolejnych nagłówków.
Jedną z możliwych, a przy tym obecnie często występującą realizację tego modelu przedstawia poniższy rysunek.
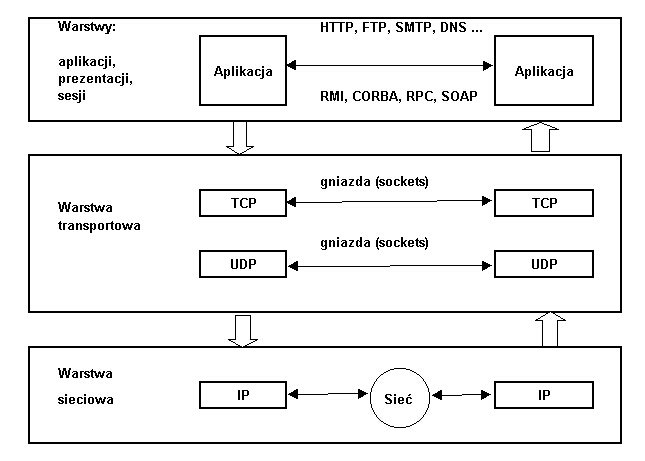
5.2. Gniazda.
Jak widać z poprzedniego rysunku komunikacja pomiędzy procesami w sieci
może odbywać się za pomocą jednego z wysokopoziomowych protokołów sieciowych
(HTTP, FTP itp.), a także bardziej zaawansowanych mechanizmów takich jak
zdalne wywołanie metod (RMI, CORBA), zdalne wywołanie procedur (RPC), czy
SOAP (pozwalający na zdalne wolanie metod i procedur - inaczej: zlecanie
usług - za pomocą przekazywania odpowiednio ustrukturyzowanych plików XML
z zapisem "zadań do wykonania").
U podstaw wymiany informacji za pomocą protokołów najwyższego poziomu leży obecnie (najczęściej) komunikacja za pomocą gniazd.
Gniazdo (socket) - to abstrakcja programistyczna, oznaczająca punkt
docelowy dwustronnej komunikacji dwóch procesów działających równolegle w
sieci
To właśnie koncepcja gniazd, wprowadzona w Uniksie w latach 70-tych, stanowi
wspomnianą wcześniej, sieciowo-zorientowaną, unifikację mechanizmu IPC.
Naturalne było
uczynienie komunikacji za pomocą gniazd w idei podobnej do dobrze znanego
programistom paradygmatu operacji wejścia-wyjścia. Zatem mamy to naturalną
sekwencję: otwarcie kanału komunikacji (gniazda), zapis lub odczyt (przesłanie
lub otrzymanie danych za pomocą gniazda), zamknięcie kanału komunikacyjnego
(zamkniecie gniazda).
Zwykle komunikacja za pomocą gniazd implementowane jest na bazie protokołu TCP lub protokołu UDP.
Protokół TCP (Transport Control Protocol) jest protokołem połączeniowym
(co znaczy, że ustanawiana jest dwustronne połączenie pomiędzy klientem i
serwerem). Zapewnia, że dane posyłane poprzez gniazda docierają w całości
i w odpowiedniej kolejności. Inaczeje możemy powiedzieć, że realizowana jest
tu strumieniowa koncepeja wymiany danych, co oznacza, że po ustanowieniu
połaczenia można przesłać dane o dowolnym rozmiarze i - jak zobaczymy - operacje
wymiany danych możemy wykonywać tutaj za pomocą dobrze nam znanych środków
strumieniowych.
Protokół UDP (User Datagrams Protocol) jest protokołem bezpołączeniowym.
Dane przesyłane są pomiędzy procesami jako datagramy (pakiety danych o określonej
maksymalnej wielkości np. 64 kB), przy czym z każdym datagramem posyłany
jest "adres" odbiorcy. Datagramy mogą więc przybywac na miejsce przeznaczenia
(do innego procesu) w dowolnje kolejności (a niektóre nawet mogą w ogóle
nie dotrzeć).
Oba protokoły (TCP i UDP) są protokołami typu "point-to-point", czyli każdorazowo
zapewniającymi komunikację tylko pomiędzy dwoma procesami (w szczególności
na dwóch różnych maszynach w sieci).
Istnieje również możliwość użycia tzw. multicastingu. Ten rodzaj protokołów
oznacza dystrybucje informacji z serwera od razu do wielu klientów. Oparty
jest on na protokole UDP.
Identyfikacji maszyn biorących udział
w komunikacji (tzw. hostów) służy protokól IP (Internet Protocol). Adresy
IP mają ogólnie formę 32-bitowych (lub 128-bitowych w wersji IPv6) liczb i mogą być zapisywane jako sekwencja
czterech (ośmiu) liczb rozdzielonych kropkami (np. 192.33.71.12) lub - w formie "strawniejszej",
wykorzystującej DNS (Domain Name Service) jako: nazwa_hosta.nazwa_domeny
(np. boulder.ibm.com).
Identyfikacja hosta jest jednak nie wystarczająca dla komunikacji miedzy
procesami: na danym komputerze może się przecież wykonywać równolegle wiele procesów.
Termin port używany jest rownież w innych znaczeniach, dotyczących fizycznego
łączenia urządzeń np. port szeregowy czy USB
Po to, by dane dotarły do określonego
procesu protokoły TCP i UDP posługują się tzw. portami.
Porty są identyfikowane przez 16-bitowe liczby - numery portów. Numery te
są używane przez TCP lub UDP do przesyłanie danych do odpowiedniego procesu.
W prokołach połączeniowych (takich jak TCP) proces-serwer przydziela sobie
port o określoneym numerze i poprzez ten właśnie port procesy klienckie mogą
ustanawiać połączenia z serwerem.
W protokołach opartych na datagramach, pakiety datagramów zawierają numer
portu dzięki któremy dane kierowane są do właściwego procesu (aplikacji).
Teraz zajmiemy się tylko najprostszym TCP.
Inne:
- multicasting
(w Javie - klasa MulticastDatagramSocket)
- bezpieczną transmisja danych opartą na protokole SSL/TSL (Secure Socket
Layer/Transport Secure Layer).
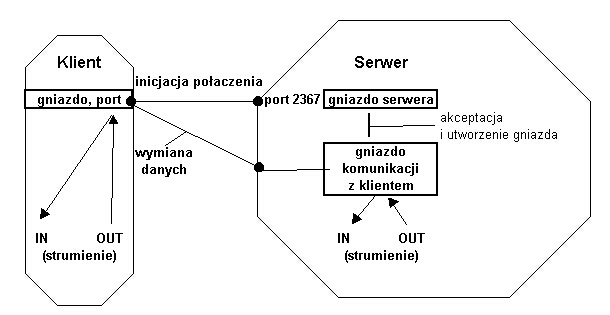
Typowa interakcja pomiędzy klientem i serwerem opiera się na następującym modelu.
- Serwer tworzy gniazdo związane z określonym portem i na tym kanale komunikacyjnym czeka na prośbę połączenia od klienta.
- Inicjatywa połączenia wychodzi od klienta; klient musi znać host serwera
oraz numer portu otwartego do przyjmowania połączeń i podaje tę informację
tworząc "u siebie" gniazdo związane z tak określonym adresem
- Serwer akceptuje połaczenie od klienta i - aby pozostać dostępnym dla
innych klientów na "kanale połączeniowym" - tworzy inne gniazdo do komunikacji
z danym klientem;
- Z punktu widzenia klienta jest to (zazwyczaj) to samo gniazdo na którym zainicjowano
połączenie; strumienie wejściowy i wyjściowy związane z tym gniazdem służą
do komunikacji pomiędzy klientem i serwerem zgodnie z protokołem serwera.
Ilustruje to poniższy rysunek.
Jest to oczywiście ogólny model. Niektóre protokoły mogą wprowadzać pewne odstępstwa
od niego. Przykładem jest protokól FTP, gdzie do komunikacji z serwerem
wykorzystywane są dwa gniazda: do posyłania poleceń i do posyłania/odczytywania
danych.
Zatem posługujemy się dwoma rodzajami gniazd:
- gniazdami serwerowymi, w Javie reprezentowanymi przez klasę ServerSocket, używanymi przy programowaniu serwerów,
- gniazdami klienckimi, w Javie reprezentowanymi przez klasę Socket,
używanymi w programowaniu klientów, a w serwerach do komunikacji z klientem
po zaakceptowaniu połączenia od niego.
5.3. Klienci. Protokoły i porty
W Javie oprogramowanie klienta, komunikującego sie z serwerem - w większości przypadków - jest niezwykle proste i polega na:
- Utworzeniu gniazda - obiektu klasy Socket, dającego połączenie z serwerem.
- Uzyskaniu od tego obiektu strumieni wyjściowego i wejściowego, związanych z gniazdem.
- Posyłanie zleceń dla serwera poprzez zapis do strumienia wyjściowego gniazda.
- Odczytywanie odpowiedzi serwera poprzez odczyt ze strumienia wejściowego.
- Zamknięcie strumieni.
- Zamknięcie gniazda
Najprostszy schemat komunikacji klienta z serwerem przez gniazda
try {
// Utworzenie gniazda
String serverHost = ... ; // adres IP serwera ("cyfrowo" lub z użyciem DNS)
int serverPort = ... ; // numer portu na którym nasłuchuje serwer
Socket socket = new Socket(serverHost, serverPort)
// Uzyskanie strumieni do komunikacji
OutputStream sockOut = socket.getOutputStream();
InputStream sockIn = socket.getInputStream();
// Komunikacja (zależna od protokołu)
// Wysłanie zlecenia do serwera
sockOut.write(...);
...
// Odczytanie odpowiedzi serwera
sockIn.read(...);
...
// Po zakończeniu komunikacji - zamkniecie strumieni i gniazda
sockOut.close();
sockIn.close();
socket.close();
} catch (UnknownHostException exc) {
// nieznany host
} catch (SocketException exc) {
// wyjątki związane z komunikacją przez gniazda
} catch (IOException exc) {
// inne wyjątki we/wy
}
Uwaga: zazwyczaj strumienie związane z gniazdem będziemy opakowywać, zapewniając
określone rodzaje przetwarzania (np. buforowanie, kodowanie-dekodowanie,
odczyt/zapis danych binarnych itp.).
W komunikacji pomiędzy klientem i serwerem kluczową sprawą jest znajomość
protokołu (czyli rodzajów i formatów zleceń, które można posłać do serwera
oraz treści i formatów odpowiedzi, które serwer przyszyła w reakcji na konkretne
zlecenia).
Istnieją pewne standardowe protokoły, dzięki którym uzyskujemy dostęp
do różnorodnych usług w Internecie. Do najbardziej znanych (a czasem i użytecznych)
należą protokoły:
- HTTP (Hypertext Transfer Protocol) służący m.in. do uzyskiwania dostępu
do stron WWW oraz przesyłania fromularzy (jego wersja HTTPS, oparta na protokole
TSL/ SSL - Transport Security Layer/Secure Sockets Layer - pozwala na bezpieczną
transmisję danych),
-
FTP (File Transfer Protocol) służący do pobierania/zapisywania plików (i jego bezpieczna wersja oparta na TSL/SSL - FTPS)
-
SMTP (Simple Mail Transfer Protocol) służący do przesyłania poczty elektronicznej (ESMPT - SMPT z rozszerzeniami).
- POP3 (Post Office Protocol) służący do pobierania poczty z serwera
- IMAP (Internet Message Access Protocol) j.w., z dodatkowymi możliwościami.
- TELNET - umożliwiający zdalną prace na komputerze-hoście
- TIME - proste uzyskiwanie aktualnego czasu od serwerów czasu
- DAYTIME - proste uzyskiwanie daty i czasu
- NTP (Network Time Protocol) - zaawansowane możliwości uzyskiwania dokładnego czasu
- NNTP (Network News Transfer Protocol) - przesyłanie, dystrybucja i odbiór wiadomości z tzw. newsgroups.
- IRC - Internet Relay Chat - znane wszystkim internetowe "czaty",
- ECHO - "odbijający" dane posyłane przez klienta (służy głównie do celów testowania klientów)
- DICT - wyszukiwanie definicji w bazach słownikowych.
Protokoły te (a zatem format zleceń klienta i odpowiedzi serwera, kolejność
wymiany informacji itp.) są szczegółowo opisane w dokumentach RFC (Request
For Comments). Dokumenty RFC opisują technologiczne i organizacyjne aspekty
Internetu. Od 1969 roku opublikowano prawie 4000 dokumentów RFC. Wiele z
nich uzyskało status standardu (m.in. prawie wszystkie opisujące w/w protokoly).
Standartyzacją protokołów internetowych zajmują się następujące organizacje:
IETF - The Internet Engineering Task Force - http://www.ietf.org/home.html
IESG - The Internet Engineering Steering Group
IANA - Internet Assigned Numbers Authority (http://www.iana.org/), która
m.in. ustala różnego rodzaju parametry protokołów, np. numery portów, czy
nazwy zbiorów znaków.
Przyjęte jako standardy dokumenty RFC (Official Internet Protocol Standards),
w szczególności opisujące protokoły, można znaleźć na stronie: http://www.rfc-editor.org/rfc.html.
Uzyskamy tam również dostęp do bazy danych wszystkich dokumentów RFC.
Tworząc program kliencki, który ma komunikować się z serwerem, musimy (oczywiście) wiedzieć na jakim hoście
działa serwer i przez jaki port możemy się z nim skontaktować.
Z serwerami udostępniającymi opisane wcześniej protokoły-usługi (oprócz serwerów
DICT) łączymy się przez tzw. dobrze-znane-porty. "Dobrze-znane-porty" mają
zarezerwowane numery od 0 do 1023 (tych numerów nie powinniśmy przydzielać swoim
serwerom). Porty o numerach 1024-49151 są natomiast tzw. portami zarejestrowanymi.
Tych numerów możemy używać, ale należy liczyć się z tym, że wybrany przez
nas numer może być "zarejestrowany" - czyli jego użycie opisane publicznie
jako skojarzone z jakimś protokołem. Przykładem jest protokól DICT, któremu
przypisano port 2628.
Pozostały zakres numerów portów 49152-65535 określa tzw. porty dynamiczne lub prywatne. Możemy ich używac.
Każdy ze standardowych protokołów (a ściślej każdy z serwerów realizujących
dany protokół) ma ściśle określony port kontaktowy, za pomocą którgo klient
nawiązuje połączenie. Numery portów określa standard IANA - można je znaleźć
na stronie: http://www.iana.org/assignments/port-numbers.
W poniższej tabeli pokazano niektóre standardowe numery portów.
| Numer portu
| Protokół
|
|---|
| 7 | ECHO |
| 20 | FTP -- Dane |
| 21 | FTP -- Polecenia
Uwaga: protokól FTP posluguje się dwoma portami (a w konsekwencji dwoma
gniazdami): jednym dla przekazywania poleceń, drugim - dla transferu plików).
W zależności od trybu p[rort danych może mieć numer 20, albo inny.
|
| 22 | SSH Remote Login Protocol |
| 23 | Telnet |
| 25 | Simple Mail Transfer Protocol (SMTP) |
| 37 | Time |
| 70 | Gopher ("przodek" HTTP)
Uwaga: jest jeszcze trochę działających serwerów Gopher m.in. w Kanadyjskim Urzędzie Statystycznym
|
| 80 | HTTP |
| 110 | POP3 |
| 119 | Newsgroup (NNTP) |
123
|
Network Time Protocol (NTP)
|
| 143 | Internet Mail Access Protocol (IMAP) |
| 194 | Internet Relay Chat (IRC) |
| 443 | HTTPS (HTTP w oparciu o TSL/SSL) |
989
|
FTPS (w oparciu o TSL/SSL) - dane
|
990
|
FTPS (w oparciu o TSL/SSL) - polecenia
|
992
|
Telnets (Telnet w oparciu o TSL/SSL)
|
993
|
IMAPS (IMAP4 w oparciu o TSL/SSL)
|
994
|
IRCS (IRC w oparciu o TSL/SSL)
|
995
|
POP3S (POP3 w oparciu o TSL/SSL)
|
| 2628 | DICT |
Zanim przeanalizujemy nieco bardziej rozbudowane przykłady programów
klienckich warto przyjrzeć najprostszym ilustracjom, i na ich przykładach
poznać pewne cechy gniazd. Zaczniemy od protokołu DAYTIME, zgodnie z którym
- zaraz po połączeniu - serwer przesyła klientowi aktualną date i czas, po
czym zamyka połączenie. Format odpowiedzi nie jest przez RFC określony, jednak
każdy serwer dostarcza informacji o składni komunikatu, zawierającego datę
i czas.
W najprostszej postaci program odczytujący datę i czas z serwera czasu może wyglądać tak.
import java.net.*;
import java.io.*;
class DateTime1 {
public static void main(String[] args) {
String host = null;
int port = 13;
try {
host = args[0]; // host - jako argument wywołania
// Utworzenie gniazda
Socket socket = new Socket(host, port);
// Pobranie strumienia wejściowego gniazda
// Nakładamy dekodowanie i buforowanie
BufferedReader br = new BufferedReader(
new InputStreamReader(
socket.getInputStream()
)
);
// Odczyt odpowiedzi serwera (data i czas)
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
// Zamknięcie strumienia i gniazda
br.close();
socket.close();
} catch (UnknownHostException exc) {
System.out.println("Nieznany host: " + host);
} catch (Exception exc) {
exc.printStackTrace();
}
}
}
Po uruchomieniu w wierszu poleceń np. z argumentem time.nist.gov uzyskamy odpowiedź w następujacej postaci:
52943 03-10-31 22:06:50 00 0 0 223.2 UTC(NIST) *
Uwaga: wyjaśnienie szczegółów składni tej odpowiedzi można znaleźć na stronie www.time.nist.gov.
8.4. Adresowanie i wyjątki przy próbie połączenia z serwerem
Przy tworzeniu gniazda adresy hostów można podawać w postaci tekstowej (w formie DNS lub w formie "liczbowego" adresu IP).
Np.
Socket socket = new Socket("time.nist.gov", 13);
lub
Socket socket = new Socket("192.43.244.18", 13);
Te formy konstruktorów klasy Socket zapewniają nie tylko utworzenie gniazda, ale również próbę połączenia z serwerem.
Podany serwer może nie istnieć, może istnieć ale nie zgodzić się na połączenie,
może się też zdarzyć że przekroczony zostanie maksymalny czas oczekiwania na uzyskanie
połączenia. Wszystkie te sytuacje są sygnalizowane jako odpowiednie wyjątki.
Pokazuje to poniższy przykład, w którym staramy się połączyć z różnymi potencjalnymi
serwerami ECHO (serwery takie przyjmują jako zlecenie dowolny tekst, a ich
funkcją jest zwrócenie tego samego tekstu - były kiedyś powszechnie wykorzystywane
do testowania, teraz jednak, ze względów bezpieczeństwa, porty są blokowane
i raczej trudno jest znaleźć jakiś działający echo-serwer).
import java.io.*;
import java.net.*;
public class EchoClient {
final static int ECHO_PORT = 7;
private Socket sck;
private PrintWriter out;
private BufferedReader in;
public EchoClient() {}
public void connect(String host)
throws UnknownHostException, IOException {
sck = new Socket(host, ECHO_PORT);
in = new BufferedReader (
new InputStreamReader(sck.getInputStream()));
out = new PrintWriter (
new OutputStreamWriter(sck.getOutputStream()), true);
System.out.println("Połączony z hostem:" + sck.getInetAddress() );
}
public void echoMsg(String msg) throws IOException {
out.println(msg);
String response = in.readLine();
System.out.println("Klient: " + msg);
System.out.println("Serwer: " + response);
}
public void disconnect() throws IOException {
in.close();
out.close();
sck.close();
}
public static void main(String[] args) {
String[] hosts = { "aeneas.mit.edu",
"cs.toronto.edu",
"cs.utah.edu",
"web.mit.edu",
"boulder.ibm.com",
"somethin"
};
int i = 0;
EchoClient ec = new EchoClient();
for (; i<hosts.length; i++) {
try {
ec.connect(hosts[i]);
ec.echoMsg("Dzień dobry!");
ec.disconnect();
} catch(UnknownHostException exc) {
System.out.println("Nieznany host: " + hosts[i]);
} catch(IOException exc) {
System.out.println(hosts[i] + " - " + exc);
}
}
}
}
Program wyprowadzi następującą informację:
aeneas.mit.edu - java.net.ConnectException: Connection refused: connect
cs.toronto.edu - java.net.ConnectException: Connection refused: connect
cs.utah.edu - java.net.ConnectException: Connection timed out: connect
web.mit.edu - java.net.ConnectException: Connection timed out: connect
boulder.ibm.com - java.net.ConnectException: Connection timed out: connect
Nieznany host: somethin
Zauważmy:
- wyjątki powstające przy braku możliwości połączenia są klasy ConnectException (i jest to podklasa IOException),
- wadliwy (nieistniejący) host zgłaszany jest w formie wyjątku UnknownHostException,
Istnieje jeszcze inny sposób tworzenia gniazd i użycia adresów internetowych.
Możemy w tym celu wykorzystać klasy InetAddress i InetSocketAddress.
Obiekty klasy InetAddress reprezentują adresy IP (podklasa Inet4Address w
wersji 4, a podklasa Inet6Adrres w wersji 6 protokołu IP) i zapewniają translację
adresów z postaci tekstowej do binarnej i odwrotnie. Adresy IP - obiekty
klasy uzyskujemy stosując statyczne metody klasy m.in.
- InetAddres InetAddress.getByName(nazwa_hosta) - zwraca adres IP podanego hosta,
- InetAddress[] InetAddress.getAllByName(nazwa_hosta) - zwraca tablicę
adresów IP podanego hosta (nazwa hosta np. java.sun.com może być skojarzona
z kilkoma adresami IP, używanymi alternatywnie dla zmniejszania obciążenia
serwerów).
Uwagi:
- podając nazwę hosta w postaci DNS (np. java.sun.com) uzyskujemy rozwiązanie
referencji przez serwisy DNS (Domain Name Service) czy NIS (Network Information
Service); wywołanie jest blokujące i ew. - dla nieistniejącego hosta może
powstać wyjątek UnknownHostException
- podając nazwę hosta w tekstowej postaci IP (np. "192.33.87.12") uzyskujemy tylko formalne sprawdzenie poprawności adresu,
- podając null uzyskamy adres interfejsu loopback.
Referencje do obiektu klasy InetAddress możemy podać przy tworzeniu gniazda np.
String host = "time.nist.gov";
int port = 13;
try {
// Utworzenie adresu
InetAddress inetadr = InetAddress.getByName(host);
// Utworzenie gniazda
Socket socket = new Socket(inetadr, port);
....
}
Oprócz bardziej zaawansowanych działań na adresach sieciowych, klasa InetAdress
jest wykorzystywana przy tworzeniu "adresów gniazd" (adres IP + port), które
są obiektami klasy InetSocketAddress. Te z kolei mogą być zastosowane do
odroczenia (odseparowania) łączenia z serwerem od aktu utworzenia gniazda.
Możemy mianowicie najpierw utworzyć "niezwiązane" gniazdo:
Socket socket = new Socket();
odpowiednie adresy:
InetAdress inetadr = InetAddress.getByName(host);
InetSocketAddress conadr = new InetSocketAddress(inetadr, port);
po czym w odpowiednim, wybranym momencie połączyć się z serwerem:
socket.connect(conadr);
Dokładniej obrazuje to poniższy fragment programu:
public static void main(String[] args) {
String host = "time.nist.gov";
int port = 13;
Socket socket = new Socket(); // utworzenie niezwiązanego gniazda
try {
// Utworzenie adresów
InetAddress inetadr = InetAddress.getByName(host);
InetSocketAddress conadr = new InetSocketAddress(inetadr, port);
// Połaczenie z serwerem
socket.connect(conadr);
// Pobranie strumienia wejściowego gniazda
// Nakładamy buforowanie
BufferedReader br = new BufferedReader(
new InputStreamReader(
socket.getInputStream()
)
);
// Odczyt odpowiedzi serwera (data i czas)
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
// Zamknięcie strumienia i gniazda
br.close();
socket.close();
} catch (UnknownHostException exc) {
System.out.println("Nieznany host: " + host);
} catch (Exception exc) {
exc.printStackTrace();
}
}
Ten sposób programowania może sprzyjać lepszemu izolowaniu fragmentów kodu,
okaże się także przydatny wtedy, gdy chcemy precyzyjnie określić maksymalny
czas oczekiwania na połączenie.
5.5. Limity czasu łączenia i odczytu
Czasami przydatne jest określenie maksymalnego czasu oczekiwania na połączenie
z serwerem jak również masymalnego czasu oczekiwania na odczyt kolejnych
danych z serwera. Na przykład - nie chcemy uzyskać informacji o czasie od serwera
czasu po upływie kilku sekund - chcemy mieć raczej dokładny, aktualny pomiar.
Limit czasu na połączenie (w milisekundach) specyfikujemy jako drugi argument
przeciążonej metody connect. Gdybyśmy np. w poprzednim programie napisali:
socket.connect(conadr, 100);
to nie uzyskanie połączenia w ciągu 100 milisekund będzie skutkowało powstaniem wyjątku SocketTimeoutException np.
java.net.SocketTimeoutException: connect timed out
Innym limitem czasowym jest limit odczytu. Możemy uzyskać połączenie, ale
w komunikacji z serwerem (w trakcie czytania odpowiedzi serwera) mogą wystąpić
jakieś opóźnienia, których nie chcemy zaakceptować. Limity czasu na odczyt
specyfikujemy w milisekunadach za pomocą metody setSoTimeout(...)
z klasy Socket. Ten limit określa maksymalny czas blokowania operacji czytania
strumienia wejściowego gniazda. Po przekroczeniu tego czasu blokowanie na
wejściu jest przerywane i powstaje wyjątek SocketTimedOutException. Gniazdo
i jego strumień wejściowy mogą być ponownie użyte.
Ustalenie limitu musi poprzedzać wprowadzanie jakiejkolwiek blokującego czytania strumienia gniazda.
Przykładowy program pokazuje, że po uzyskaniu połaczenia z serwerem czasu
odpowiedź (aktualny czas) uzyskujemy nie dość szybko (jak sobie tego życzymy) i powstaje
wyjątek SocketTimeoutException.
try {
// Utworzenie adresów
InetAddress inetadr = InetAddress.getByName(host);
InetSocketAddress conadr = new InetSocketAddress(inetadr, port);
// Połaczenie z serwerem
// Określenie maksymalnego czasu oczekiwania na połączenie
socket.connect(conadr, 200);
// Pobranie strumienia wejściowego gniazda
// Nakładamy buforowanie
BufferedReader br = new BufferedReader(
new InputStreamReader(
socket.getInputStream()
)
);
// Okreslenie maksymalnego czasu oczekiwania na odczyt danych z serwera
socket.setSoTimeout(50);
// Odczyt odpowiedzi serwera (data i czas)
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
// Zamknięcie strumienia i gniazda
br.close();
socket.close();
} catch (UnknownHostException exc) {
System.out.println("Nieznany host: " + host);
} catch (Exception exc) {
exc.printStackTrace();
}
}
java.net.SocketTimeoutException: Read timed out
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.read(SocketInputStream.java:129)
at sun.nio.cs.StreamDecoder$CharsetSD.readBytes(StreamDecoder.java:408)
at sun.nio.cs.StreamDecoder$CharsetSD.implRead(StreamDecoder.java:450)
at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:182)
at java.io.InputStreamReader.read(InputStreamReader.java:167)
at java.io.BufferedReader.fill(BufferedReader.java:136)
at java.io.BufferedReader.readLine(BufferedReader.java:299)
at java.io.BufferedReader.readLine(BufferedReader.java:362)
at DateTime2.main(DateTime2.java:36)
5.6. Inne parametry gniazd kliencich.
Klasa Socket dostarcza wielu metod uzyskiwania informacji o stanie i opcjach gniazda.
W syntetyczny sposób możemy poznać je za pomocą poniższego programiku, który
refleksyjnie wywołuje publiczne metody get...() i is...() z klasy Socket.
import java.net.*;
import java.io.*;
import java.lang.reflect.*;
class DateTime2 {
public static void main(String[] args) {
String host = "time.nist.gov";
int port = 13;
Socket socket = new Socket();
try {
// Utworzenie adresów
InetAddress inetadr = InetAddress.getByName(host);
InetSocketAddress conadr = new InetSocketAddress(inetadr, port);
// Połaczenie z serwerem
// Określenie maksymalnego czasu oczekiwania na połączenie
socket.connect(conadr, 200);
// Pobranie strumienia wejściowego gniazda
// Nakładamy buforowanie
BufferedReader br = new BufferedReader(
new InputStreamReader(
socket.getInputStream()
)
);
// Okreslenie maksymalnego czasu oczekiwania na odczyt danych z serwera
socket.setSoTimeout(200);
// Czego możemy się dowiedzieć o stanie gniazda?
report(socket);
// Odczyt odpowiedzi serwera (data i czas)
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
// Zamknięcie strumienia i gniazda
br.close();
socket.close();
} catch (UnknownHostException exc) {
System.out.println("Nieznany host: " + host);
} catch (Exception exc) {
exc.printStackTrace();
}
}
// Dynamiczne wołanie metod z klasy Socket
static void report(Socket s) throws Exception {
Method[] methods = (java.net.Socket.class).getMethods();
Object[] args = {};
for (int i=0; i<methods.length; i++) {
String name = methods[i].getName();
if ((name.startsWith("get") || name.startsWith("is")) &&
!name.equals("getChannel") &&
!name.equals("getInputStream") &&
!name.equals("getOutputStream")) {
System.out.println(name + "() = " +
methods[i].invoke(s, args));
}
}
}
}
Program wyprowadzi:
getPort() = 13
isClosed() = false
getInetAddress() = time.nist.gov/192.43.244.18
getKeepAlive() = false
getLocalAddress() = /61.120.87.131
getLocalPort() = 1178
getLocalSocketAddress() = /61.120.87.131:1178
getOOBInline() = false
getReceiveBufferSize() = 8192
getRemoteSocketAddress() = time.nist.gov/192.43.244.18:13
getReuseAddress() = false
getSendBufferSize() = 8192
getSoLinger() = -1
getSoTimeout() = 200
getTcpNoDelay() = false
getTrafficClass() = 0
isBound() = true
isConnected() = true
isInputShutdown() = false
isOutputShutdown() = false
getClass() = class java.net.Socket
52944 03-11-01 00:36:14 00 0 0 913.5 UTC(NIST) *
Proszę sprawdzić w dokumentacji znaczenie poszczególnych opcji.
5.7. Klient SMTP
Protokół - to jest ważne !!!
Klient posyła zlecenia w określonej formie, serwer odpowiada wierszami danych,
w których na początku znajdują się numeryczne kody, określające wynik przetworzenia
zlecenia, a po nich następują werbalne (różne dla różnych serwerów) informacje
(np. informacja o serwerze, słówko "Ok", że wszystko w porządku, lub napis
typu "go ahead"). Oczywiście, napisy mogą być w różnych językach; w przeciwieństwie
do numetycznych kodów nie są one określone przez protokół SMTP i każdy serwer
może opisywac wyniki swego działania w dowolny sposób.
Ważna jest również kolejność zleceń i odpowiedzi oraz to, by klient identyfikował
wyniki zleceń i odpowiednio do tego reagował (np. nie ma sensu posyłania
poczty, jeżeli serwer zwraca wynik, świadczący o tym, że transakcja nie może
dojść do skutku).
klient: połączenie przez port 25,
serwer: kod potwierdzenia uzyskania połączenia 220,
klient: inicjacja komunikacji HELO lub EHLO (ESMPTP) + identyfikacja domeny,
serwer: OK? - 250, nie - kody błędów (np. brak autoryzacji). Odp: wiele wierszy (nie wiadomo ile).
klient: inicjacja transakci - MAIL, RCPT (odbiorcy)
serwer: OK? - 250
klient: posyłanie danych - polecenie DATA
serwer: 354 (go ahead),
klient: list (koniec listu: jedna kropka w wierszu, sic!)
serwer: odebrałem? - 250
i dalej następne zlecenia (inne transakcje pocztowe itp.)
Zamknięcie kanału przez klienta.
Przykładowy program wysyła listy, których zawartosć pobierana jest z plików.
Przeslanie zleceń do serwera - metoda doRequest(String
zlecenie, int checkCode). Zapisuje ona zlecenie do strumienia wyjściowego
gniazda łączącego klienta z serwerem SMTP, po czym wywołuje
metodę readResponse(int checkCode), która odczytuje odpowiedź serwera. Przekazywany jako argument tej metody
checkCode jest spodziewanym (i wymaganym) kodem wyniku. Przy jego niezgodności
z kodem odczytywanym ze strumienia wejściowego gniazda (czyli przekazanym
przez serwer) zgłaszamy wyjątek IOException z komunikatem "Niespodziewany
kod wyniku".
W obu metodach - doRequest i readResponse - wypisuejmy informację na konsole,
uzyskując w ten sposób prezentację komunikacji pomiędzy klientem i serwerem.
import java.io.*;
import java.net.*;
public class EmailClient {
Socket smtpSocket = null;
PrintWriter sockOut = null;
InputStream sockIn = null;
public void connect(String server, String myDomain) {
try {
smtpSocket = new Socket(server, 25);
sockOut = new PrintWriter(
new OutputStreamWriter(smtpSocket.getOutputStream(), "UTF-8"),
true);
sockIn = smtpSocket.getInputStream();
// Czy połączenie zostało nawiązane?
// Musi być kod 220 - wtedy Ok
// Odczytując odpowiedż serwera,
// sprawdzamy w metodzie readResponse kod 220
readResponse(220);
// Przedstawiamy się serwerowi
// Jeśli nas zaakceptuje - poda kod 250
doRequest("HELO " + myDomain, 250);
} catch (UnknownHostException e) {
System.err.println("Nieznany host: " + server);
cleanExit(1);
} catch (IOException exc) {
System.err.println(exc);
cleanExit(2);
}
}
// Posyłanie maila
public void send(String from, String to, String fname) {
try {
// Inicjacja transakcji
// Kod 250 - jesli OK
doRequest("MAIL FROM:<" + from + ">", 250);
// Określenie adresata
// Kod 250 - jesli OK
doRequest("RCPT TO:<" + to + ">", 250);
// Posyłanie danych listu
// Odpowiedź serwera - 354 = jestem gotowy na przyjęcie danych
doRequest("DATA", 354);
// Teraz będziemy zapisywać treść listu
// bezpośrednio do strumienia wyjściowego gniazda
// Najpierw jakieś nagłówki
sockOut.println("From: " + from);
sockOut.println("To: " + to);
// Czytanie treści listu z pliku
// Ponieważ samotna kropka w wierszu kończy dane listu
// to samotną kropkę w treści zamieniamy na dwie kropki
BufferedReader br = new BufferedReader(
new FileReader(fname));
String line;
while ((line = br.readLine()) != null) {
if (line.equals(".")) line += ".";
sockOut.println(line);
}
// Sekwencja CRLF.CRLF oznacza koniec treści listu
// Drugie CRLF dodane w metodzie doRequest przez println
doRequest("\r\n.", 250);
} catch (IOException e) {
System.err.println(e);
cleanExit(2);
}
}
// Zamknięcie połączenia
public void closeConnection() {
try {
doRequest("QUIT", 221);
} catch (Exception exc) {
System.err.println(exc);
}
cleanExit(0);
}
private void doRequest(String req, int checkCode)
throws IOException {
sockOut.println(req);
System.out.println("Klient: " + req);
readResponse(checkCode);
}
// Uwaga: nie powinniśmy tu stosować buforowania i metody
// readLine(), ponieważ nie wiadomo ile wierszy zwrówci serwer
// a wywołanie readLine jest blokujące
// Zakłądamy: że każda odpowiedź zmieści się w 10000 bajtów
private void readResponse(int checkCode) throws IOException {
byte[] readBytes = new byte[10000];
int num = sockIn.read(readBytes);
String resp = new String(readBytes, 0, num);
System.out.println("Serwer: " + resp);
if (!resp.startsWith(String.valueOf(checkCode)))
throw new IOException("Niespodziewany kod wyniku od serwera");
}
private void cleanExit(int code) {
try {
sockIn.close();
sockOut.close();
smtpSocket.close();
}
catch (Exception exc) {}
System.exit(code);
}
public static void main(String[] args) {
String server = "mail.somemailer.net";
String myDomain = "62.125.12.111";
String from = "[email protected]";
String to = "you@anywhere";
EmailClient email = new EmailClient();
email.connect(server, myDomain);
email.send(from, to, "list1");
email.send(from, to, "list2");
email.closeConnection();
}
}
Przykładowy wynik działania programu:
Serwer: 220 mail.somemailer.net ESMTP
Klient: HELO 62.125.12.111
Serwer: 250 mail3.somemailer.net
Klient: MAIL FROM:<
[email protected]>
Serwer: 250 Ok
Klient: RCPT TO:<someone@anywhere>
Serwer: 250 Ok
Klient: DATA
Serwer: 354 End data with <CR><LF>.<CR><LF>
Klient:
.
Serwer: 250 Ok: queued as 28F372E815A
Klient: MAIL FROM:<
[email protected]>
Serwer: 250 Ok
Klient: RCPT TO:<someone@anywhere>
Serwer: 250 Ok
Klient: DATA
Serwer: 354 End data with <CR><LF>.<CR><LF>
Klient:
.
Serwer: 250 Ok: queued as 8FA212E81EC
Klient: QUIT
Serwer: 221 Bye
Ten przykład oprogramowania klienta ilustruje dwie ważne kwestie:
-
potrzebę zgodnego z protokołem, starannego ustalenia kolejności przesyłania zleceń i odczytywania odpowiedzi,
-
potrzebę uważnej analizy możliwych (często elastycznych) formatów odpowiedzi
serwera: tutaj musieliśmy się liczyć z wielowierszowymi odpowiedziami serwera,
przy czym liczba wierszy nie jest ustalona - wobec tego przy czytaniu odpowiedzi
serwera nie należało stosować metody readLine (która - oczywiście - jest
blokująca), a zamiast tego trzeba było czytać ze strumienia bajty.
Szczegółowy opis protokołu SMTP zawiera RFC0821, a jego rozszerzeń (ESMTP) - RFC1869.
Naturalnie, omówiony przykład nie jest ani uniwersalny ani nazbyt
użyteczny. Prawdziwe klienckie programy pocztowe mogą być bardzo rozbudowane
i dostarczać wielu możliwości. W środowisku Javy możemy wykorzystać do ich
budowy (jak również do budowy serwerów pocztowych) Java Mail API.
Zestaw klas tego pakietu umożliwia m.in. posługiwanie się protokolami SMTP,
POP3, IMAP, prowadzenie folderów wiadomości, łatwą kompozycję wiadomości
(m.in. dołączanie do listów różnego rodzaju plików jako załączników), a wszystko to bez eksponowania
szczegółów dotyczących niskopoziomowej komunikacji poprzez gniazda.
5.8. Klient DICT
Ciekawym, choć mało popularnym protokołem jest DICT.
Jest on opisany w RFC2229.
Serwery DICT prowadzą bazy danych definicji różnych terminów i dostarczają - na zlecenie klientów - odpowiednich informacji.
Nie będziemy oczywiście szczegółowo omawiać tego protokołu. Dla potrzeb demonstracji wystarczy wiedzieć, że:
-
polecenie "DEFINE * słowo" powoduje, iż serwer przegląda wszystkie prowadzone
przez niego bazy danych i przesyła klientowi wszystkie odnalezione w nich
definicje słowa.
-
koniec ciągu definicji oznaczany jest kodem 250 w nowym wierszu,
-
jeśli brak definicji - zwracany jest wiersz zawierający na początku kod 552.
Przykładowy program pokazuje, że tym razem możemy spokojnie posługiwac się
buforowanym czytaniem i metodą readLine() (serwer zwraca wiersze, a my przy
czytaniu będziemy czatowac na odpowiednie kody). Ponadto - uczynimy nasz
program nieco bardziej przyjaznym dostarczając GUI (to dobra idea i krok
naprzód - generalnie programy tego typu powinny posiadać odpowiednie wygodne
GUI).
Program przedstawiono na poniższym wydruku.
import java.io.*;
import java.net.*;
import javax.swing.*;
import java.awt.*;
import java.awt.event.*;
import java.util.*;
public class DictClient extends JFrame
{
public final static int port = 2628;
private String server;
private Socket clientSocket;
private PrintWriter out;
private BufferedReader in;
private String database = "*"; // info ze wszystkich baz
JTextArea ta = new JTextArea(20, 40);
Container cp = getContentPane();
public DictClient (String server, int timeout) {
try {
clientSocket = new Socket (server, port);
in = new BufferedReader (
new InputStreamReader(clientSocket.getInputStream(), "UTF8"));
out = new PrintWriter (
new OutputStreamWriter(clientSocket.getOutputStream(), "UTF8"),
true);
String resp = in.readLine(); // połączenie nawiązane - info o tym
System.out.println(resp);
if (!resp.startsWith("220")) {
cleanExit(1); // jeżeli dostęp niemożliwy
}
// Ustalenie maksymalnego czasu blokowania
// na operacji czytania ze strumienia gniazda
clientSocket.setSoTimeout(timeout);
} catch(UnknownHostException exc) {
System.err.println("Uknown host " + server);
System.exit(2);
} catch(Exception exc) {
exc.printStackTrace();
System.exit(3);
}
// wszystko poszło dobrze - tworzymy i pokazujemy okno wyszukiwania
Font f = new Font("Dialog", Font.BOLD, 14);
ta.setFont(f);
cp.add(new JScrollPane(ta));
final JTextField tf = new JTextField();
tf.setFont(f);
tf.setBorder(BorderFactory.createLineBorder(Color.blue, 2));
cp.add(tf, "South");
tf.addActionListener( new ActionListener() {
public void actionPerformed(ActionEvent e) {
doSearch(tf.getText());
}
});
addWindowListener( new WindowAdapter() {
public void windowClosing(WindowEvent e) {
dispose();
cleanExit(0);
}
});
pack();
show();
// Ustalenie fokusu na polu wprowadzania szukanych słów
SwingUtilities.invokeLater( new Runnable() {
public void run() {
tf.requestFocus();
}
});
}
// Wyszukiwanie
public void doSearch(String word) {
try {
String resp = "",
defin = "Uzyskano następujące definicje:\n";
// Zlecenie dla serwera
out.println("DEFINE " + database + " " + word);
// Czytamy odpowiedź
// Kod 250 na początku wiersza oznacza koniec definicji
while (resp != null && !resp.startsWith("250")) {
resp = in.readLine();
defin += resp + "\n";
if (resp.startsWith("552")) break; // słowo nie znalezione
}
ta.setText(defin);
} catch(SocketTimeoutException exc) {
ta.setText("Za długie oczekiwanie na odpowiedź");
} catch(Exception exc) {
exc.printStackTrace();
}
}
private void cleanExit(int code) {
try {
out.close();
in.close();
clientSocket.close();
} catch(Exception exc) {}
System.exit(code);
}
public static void main(String[] args) {
int timeout = 0;
String server = "dict.org";
try {
timeout = Integer.parseInt(args[0]);
server = args[1];
} catch(NumberFormatException exc) {
server = args[0];
} catch(ArrayIndexOutOfBoundsException exc) {}
new DictClient(server, timeout);
}
}
Uruchamiając program podajemy adres hosta serwera oraz maksymalne oczekiwanie
na odpowiedź (wykorzystamy je później w metodzie setSoTimeout(...)). Adresy
różnych serwerów słownikowych można znaleźć na stronie www.dict.org. Jesli
nie podamy adresu - domyślnie zostanie przyjęty podstawowy (choć nie największy
i nie najbardziej wszechstronny) serwer dict.org.
Połączenie z nim wyprowadzi na konsolę:
220 pan.alephnull.com dictd 1.8.0/rf on Linux 2.4.18-14 <auth.mime> <1094327.262
[email protected]>
i od tego momentu będziemy mogli w oknie, w polu tekstowym u dolu wprowadzać
szukane słowa i poprzez wciśnięcie ENTER uzyskiwać ich definicje (co pokazują
rysunki)

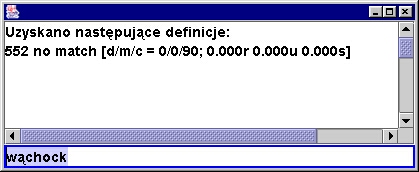
Programik ten ma jedną istotną wadę. Zlecenia obsługiwane są synchronicznie.
Nie możemy np. pisać w edytorze (wielopolu tekstowym w górnej części okna)
i jednocześnie przeszukiwać baz danych serwerów słownikowych. Zapewne moglibyśmy
sobie z tym poradzić wyodrębniając w programie wątek komunikacji z serwerem.
Zaraz to zrobimy, ale chcielibyśmy również, aby wątek ten na bieżąco informował
nas o tym co robi i ile czasu mu to zajmuje. Przy normalnym, blokującym wejściu/wyjściu
taka precyzyjna, na bieżąco podawana informacja nie jest dostępna. Jeżeli
wątek czeka na odczyt danych (jest zablokowany na operacji czytania), to
nie może równocześnie przekazywać informacji np. o upływającym czasie oczekiwania.
Powinniśmy zatem zastosowac mechanizmy NIO - mianowicie kanały gniazd klienckich i nieblokujące wejście/wyjście.
5.9. Kanały gniazd klienckich i nieblokujące wejście/wyjście
Mechanizmy
NIO (nowego wejścia-wyjścia) w Javie są nam już znane. Przed dalszą lekturą niewątpliwie warto odświeżyć
sobie te informacje.
W odróżnieniu od kanałów plikowych kanały gniazd umożliwiają nieblokujące (asynchroniczne) wejście-wyjście.
Przy czytaniu z takiego kanału za pomoca metody read(...), wątek nie jest
blokowany, gdy brak danych. Metoda read(...) natychmiast zwraca wynik - liczbę
przeczytanych bajtów (jeśli nie ma jeszcze danych - to 0). Możemy zatem w
pętli odpytywać kanał czy dane już nadeszły, a jeśli nie - wykonywać inne
zadania. Za chwilę zobaczymy to na przykładzie zmodyfikowanego klienta DICT.
Inną, odróżniającą i ważną cechą kanałów gniazd jest to, iż możliwe jest ich multipleksowanie czyli obsługiwanie przez jeden wątek wielu kanałów. Klasy kanałów gniazd (SocketChannel i ServerSocketChannel) pochodzą bowiem od klasy SelectableChannel, która pozwala na rejestrowanie kanałów do użycia z selektorami
. Te zaś obsługują selekcję kanału (zdarzenia połączenia, czytania, pisania
...), dzięki czemu możemy fragmenty programów odpowiedzialne np. za odczytywanie
danych z kanalów pisać w konwencji call-back.
Właściwość tę mają zarówno kanały gniazd klienckich jak i gniazd serwerowych,
niewątpliwie jednak prawdziwie przydatna jest ona przy programowaniu serwerów,
które przecież powinny obsługiwac równolegle wielu klientów. Programy klienckie
zwykle korzystają z jednego kanału komunikacyjnego, w związku z tym mechanizm
selektorów omówiony zostanie w dalszych punktach przy okazji programowania serwerów,
teraz natomisat zajmiemy się nieblokującym wejściem-wyjściem dla kanałów
klienckich.
Kanały gniazd klienckich tworzymy za pomocą statycznej metody open() klasy
SocketChannel.
Po stworzeniu kanału w ten sposób kanał jeszcze nie jest
połączony (poprzez gniazdo) z serwerem.
Połączenie uzyskujemy używając metody
connect z argumentem typu SocketAddress (zwykle będzie to znana nam już
klasa InetSocketAddress, której obiekty specyfikują adresy gniazd, czyli
adres hosta + numer portu).
Uwaga: w obecnej postaci kanały gniazd nie są wystarczającą abstrakcją
dla obsługi połączeń. Ustalanie opcji gniazd oraz ich zamykanie odbywa się
nadal za pomocą klasy Socket (dostęp do obiektu-gniazda, związanego z danym
kanałem uzyskujemy za pomocą metody socket() z klasy SocketChannel).
Kanały gniazd możemy skonfigurować w dwóch trybach: blokującym lub nieblokującym.
Służy do tego metoda configureBlocking(true | false).
W trybie biokującym każda operacja I/O
blokuje wątek, dopóki nie zostanie zakończona.
W trybie nieblokującym operacja
nie blokuje wątku (jej wywołanie wraca natychmiast) i może przekazać mniej
bajtów danych niż było wymagane lub nawet wcale.
Dla nieblokujących kanałów metoda connect() nie blokuje wątku, wynik jest
zwracany natychmiast i wskazuje na to czy połączenie zostało nawiązane (true),
lub, że jest w trakcie nawiązywania (false).
Zwykle połączenie nie może być
nawiązane natychmiast (ew. wyjątkiem są połączenia z lokalnym hostem), zatem
potrzebny jest mechanizm uzyskania informacji o tym czy i kiedy połączenie
zostało nawiązane. Służy temu metoda finishConnect(), której wywołanie zwraca
true, jesli proces łączenbia został zakończony a false w przeciwnym razie.
Schemat nawiązania połączenia poprzez kanał w trybie nieblokującym przedstawiono poniżej.
SocketChannel channel;
String server = ...; // adres hosta serwera
int port = ...; // numer portu
....
try {
channel = SocketChannel.open();
channel.configureBlocking(false);
channel.connect(new InetSocketAddress(server, port));
System.out.print("Łącze się ...");
while (!channel.finishConnect()) {
// ew. pokazywanie czasu łączenia (np. pasek postępu)
// lub wykonywanie jakichś innych (krótkotrwałych) działań
}
} catch(UnknownHostException exc) {
System.err.println("Uknown host " + server);
// ...
} catch(Exception exc) {
exc.printStackTrace();
// ...
}
System.out.println("\nPołaczony");
Skrócową formą utworzenia kanału i połączenia jest wywołanie metody:
SocketChannel SocketChannel.open(InetSocketAddress)
To odwołanie jest blokujące (bowiem kanały są domyślnie tworzone w trybie
blokującym), ale tryb ten możemy w dowolnym momencie zmienić na nieblokujący
za pomocą metody configureBlocking(...) i od tego momenty wszetkie operacje
we/wy na kanale będą nieblokujące.
Po stworzeniu kanału możemy do niego pisać (przekazywać zlecenia do serwera)
lub z niego czytać (odczytywać dane przekazane przez serwer). W sumie jest
to wygodne, bowiem zamiast dwóch strumieni związanych z gniazdem mamy jeden
kanał. Przy tym jednak musimy posługiwac się buforami NIO. Przypomnijmy, że:
- czytamy dane z kanału do bufora bajtowego (ByteBuffer) za pomocą metod
read(...), zapisujemy dane do kanału z bufora bajtowego (ByteBuffer) za pomocą
metody write(...); możemy przy tym korzystać z tzw. czytania rozprowadzającego
po wielu buforach (scattering read) i gromadzącego pisania z wielu buforów
(gathering write),
- bufory bajtowe muszą być alokowane za pomocą metod allocate(...), allocateDirect(...),
albo muszą opakowywać istniejące w postaci tablic typu byte[] struktury danych.
- praca z buforami bajtowymi jest specyficzna, wymaga bowiem manipulacji
parametrami (pozycjami) bufora; np. po wczytaniu danych do bufora musimy
go przestawić zapomocą metody flip(), po to by móc z tych dancyh korzystać,
- przekazywanie danych znakowych (tekstów) za pośrednictwem kanałów wymaga
ich kodowania/dekodowania (użycie klas Charset i CharBuffer).
Schemat nieblokującego czytania.
Możliwy schemat nieblokującego czytania
z kanału gniazda
SocketChannel channel;
// Utworzenie i połączenie kanału
// ...
// Ustalenie trybu nieblokującego
channel.configureBlocking(false);
// ...
// Alokowanie bufora bajtowego
// allocateDirect pozwala na wykorzystanie mechanizmów sprzętowych
// do przyspieszenia operacji we/wy
// Uwaga: taki bufor powinien być alokowany jednokrotnie
// i wielokrotnie wykorzystywany w operacjach we/wy
ByteBuffer inBuf = ByteBuffer.allocateDirect(rozmiar_bufora);
// pętla czytania
while (true) {
inBuf.clear(); // opróżnienie bufora
int readBytes = channel.read(inBuf); // czytanie nieblokujące
// natychmiast zwraca liczbę
// przeczytanych bajtów
if (readBytes == 0) { // jeszcze nie ma danych
// jakieś (krótkotrwałe) działania np. info o upływającym czasie
continue;
}
else if (readBytes == -1) { // kanał zamknięty po stronie serwera
// dalsze czytanie niemożlwe
// ...
break;
}
else { // dane dostępne w buforze
inBuf.flip(); // przestawienie bufora
// pobranie danych z bufora
// ew. decyzje o tym czy mamay komplet danych - wtedy break
// czy też mamy jeszcze coś do odebrania z serwera - kontynuacja
}
}
Uwaga: na schemacie nie pokazano koniecznej obsługi wyjątków; generalnei
dotyczy ona połączenia i konfiguracji kanału a także operacji read.
Nowa wersja klienta DICT.
Program będzie składać się z dwóch klas:
- klasa DictGui utworzy kanał, skonfiguruje go w trybie nieblokującym
i połączy go z serwerem słownikowym; definiuje ona również interfej graficzny, w którym mamy do dyspozycji
edytor tekstu oraz pole tekstowe, do którego możemy wpisać szukany termin;
po wciśnięciu ENTER na polu tekstowym uruchomioiny zostanie wątek wyszukiwania
słownikowego (klasa ReadDef), a informacje o postępach szukania będą uwidaczniane
w informacyjnej etykiecie interfejsu graficznego; po skompletowaniu wyników
przyciskiem "Wklej definicje" będziemy mogli wkleić wyniki otrzymane od serwera
słownikowego do edytora w miejscu kursora; klasa ta również (jeszcze przed
utworzeniem GUI) utworzy kanał, skonfiguruje go w trybie nieblokującym i połączy go z serwerem słownikowym;
- klasa ReadDef zapisuje do kanału zlecenie dla serwera (podaj definicję
słowa przekazanego jako argument kosntruktora) i w sposób nieblokujący czyta
odpowiedź serwera, pokazując w GUI ile czasu serwerowi zajęło szukanie i
ile porcji danych trzeba było odczytać z kanału.
Kod programu pokazano na poniższym wydruku:
import java.io.*;
import java.net.*;
import javax.swing.*;
import java.awt.*;
import java.awt.event.*;
import java.util.*;
import java.nio.*;
import java.nio.channels.*;
import java.nio.charset.*;
import java.util.regex.*;
class DictGui extends JFrame implements ActionListener {
public final static int port = 2628;
private String server;
private SocketChannel channel;
private JTextArea ta = new JTextArea(20, 20);
private JTextField tf = new JTextField(20);
private JLabel infoLab = new JLabel("Nie było szukania");
private JButton paste = new JButton("Wklej definicję");
private Container cp = getContentPane();
private ReadDef rd;
public DictGui(String server) {
this.server = server;
// Otwarcie i połączenie kanału
// metoda connect - zdefiniowana u końca klasy
try {
channel = SocketChannel.open();
channel.configureBlocking(false);
connect();
} catch(UnknownHostException exc) {
System.err.println("Uknown host " + server);
System.exit(1);
} catch(IOException exc) {
exc.printStackTrace();
System.exit(2);
}
// Konfiguracja GUI
Font f = new Font("Dialog", Font.BOLD, 14);
ta.setFont(f);
tf.setFont(f);
tf.setBorder(BorderFactory.createLineBorder(Color.orange, 1));
infoLab.setPreferredSize(new Dimension(200,30));
JPanel p = new JPanel();
p.setBorder(BorderFactory.createLineBorder(Color.red, 2));
p.add(tf);
p.add(infoLab);
p.add(paste);
cp.add(new JScrollPane(ta));
cp.add(p, "South");
tf.addActionListener(this);
paste.addActionListener(this);
// Przy zamykaniu aplikacji
// zamykamy kanał i gniazdo
addWindowListener( new WindowAdapter() {
public void windowClosing(WindowEvent e) {
dispose();
try {
channel.close();
channel.socket().close();
} catch(Exception exc) {}
System.exit(0);
}
});
pack();
show();
}
// Obsługa akcji
public void actionPerformed(ActionEvent e) {
// Kliknięcie w przycisk "Wklej definicję"
// definicję przechowuje dla nas obiekr klasy ReadDef
if (e.getSource() == paste && rd != null) {
ta.insert(rd.getResult(), ta.getCaretPosition());
}
else { // ENTER na polu tekstowym tf - start wątku komuniakcji z serwerem
if (!channel.isConnected()) try {
connect();
} catch(Exception exc) {
exc.printStackTrace();
return;
}
rd = new ReadDef(this, channel, tf.getText());
rd.start();
}
}
// Łączenie kanału z serwerem
private void connect() throws UnknownHostException, IOException {
if (!channel.isOpen()) channel = SocketChannel.open();
channel.connect(new InetSocketAddress(server, port));
System.out.print("Łącze się ...");
while (!channel.finishConnect()) {
try { Thread.sleep(200); } catch(Exception exc) { return; }
System.out.print(".");
}
System.out.println("\nPołączony.");
}
// Metoda wykorzystywana przez ReadDef
// do pokazywania postepów komuniakcji z serwerem
public void setInfo(String s) {
infoLab.setText(s);
}
}
class ReadDef extends Thread {
private static Charset charset = Charset.forName("ISO-8859-2");
private static ByteBuffer inBuf = ByteBuffer.allocateDirect(1024);
private static Matcher matchCode =
Pattern.compile("(\n250 ok)|(552 no match)").matcher("");
private SocketChannel channel;
private DictGui gui;
private String word;
public ReadDef(DictGui gui, SocketChannel ch, String wordToSearch) {
this.gui = gui;
channel = ch;
word = wordToSearch;
}
private StringBuffer result;
public void run() {
result = new StringBuffer("Wyniki wyszukiwania:\n");
int count = 0, rcount = 0;
try {
CharBuffer cbuf = CharBuffer.wrap("DEFINE * " + word + "\n");
ByteBuffer outBuf = charset.encode(cbuf);
channel.write(outBuf);
while (true) {
inBuf.clear();
int readBytes = channel.read(inBuf);
if (readBytes == 0) {
gui.setInfo("Czekam ... " + ++count);
Thread.sleep(200);
continue;
}
else if (readBytes == -1) {
gui.setInfo("Kanał zamknięty");
channel.close();
break;
}
else {
inBuf.flip();
cbuf = charset.decode(inBuf);
result.append(cbuf);
matchCode.reset(cbuf);
if (matchCode.find()) break;
else gui.setInfo("Czytam ... " + ++rcount);
}
}
} catch(Exception exc) {
exc.printStackTrace();
return;
}
gui.setInfo("Czekałem: " + count + " / Czytałem: " + rcount + ". Gotowe.");
}
public String getResult() {
if (result == null) return "Brak wyników wyszukiwania";
return result.toString();
}
}
class Main {
public static void main(String[] args) {
String server = "dict.org";
new DictGui(server);
}
}
Komentarze:
- przed utworzeniem i wystartowaniem wątku ReadDef sprawdzane jest czy
kanał nadal jest połączony (isConnected()); jeśli nie to następuje próba
ponownego połączenia;
- przy łączeniu w metodzie connect() sprawdzamy czy kanał jest otwarty,
jeśli nie to otwieramy go ponownie; kanał może być automatycznie zamknięty
na skutek utraty połączenia z serwerem.
- interakcja pomiędzy klasami DictGUI i ReadDef odbywa się za pomocą
metod: setInfo(...) i getResult(...); metoda klasy DictGUI setInfo(), wywoływana
z klasy ReadDef jest wielowątkowo bezpieczna, gdyż praktycznie wywołuje tylko
wielowątkowo bezpieczną metodę setlText(...) z klasy JLabel;
- przy czytaniu/zapisywaniu tekstów z/do kanału stosujemy dekodowanie/kodowanie za pomocą klas Charset (teksty mamy w CharBuffer),
- kody zwracane przez serwer wyszukujemy za pomocą wyrażeń regularnych;
wzorzec zastosowany do wyszukiwania nie jest najbardziej uniwersalny, ale
wystarczający dla celów ilustracji,
- użyte w programie rozwiązanie polegające na uruchamianiu nowego wątku
ReadDef dla każdego wyszukiwania nie jest najlepsze; ogólnie powinien działać
jeden wątek ReadDef synchronizowany i koordynowany z DictGUI za pomocą mechanizmu
wait-notify; tego rozwiązania nie pokazuję, aby nie zaciemniać obrazu, który
ma jedynie ilustrować nieblokujące wejście-wyjście i użycie kanałów gniazd
klienckich.
Sposób działania programu ilustruje rysunek.
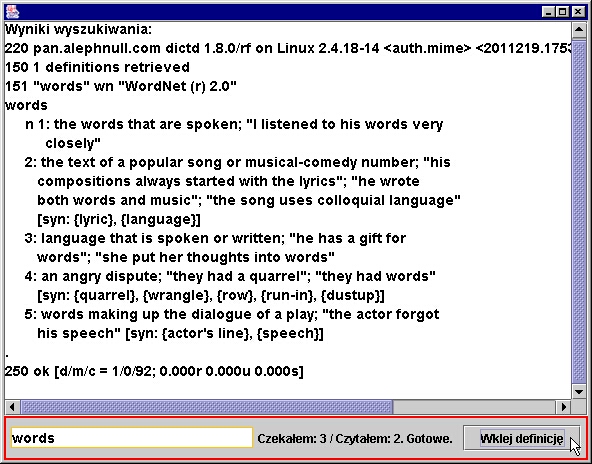
Widzimy tu (w obszarze etykiety informacyjnej), że nasz klient czekał ok.
600 ms (3 *200) na uzyskanie pierwszej odpowiedzi serwera na zapytanie o definicję słowa "words
, a odpowiedź przeczytał w dwóch porcjach danych (pierwsza 1024B, druga co najwyżej 1024 bajty).
5.10. Serwery
Serwery dostarczają - na zlecenie klientów - określonych usług (m.in. informacji).
Typowe działanie serwera polega na:
- Utworzeniu gniazda serwera (klasa ServerSocket)
- Związaniu go z określonym adresem (adres hosta, na którym działa serwer + adres portu)
- Oczekiwaniu na połączenie od klienta "na tym" gnieździe
- Po zaakceptowaniu połączenia od klienta - utworzeniu ganiazda wymiany
informacji z połączonym klientem (klasa Socket) i obsłudze zleceń tego klienta
posyłanych poprzez strumień związany z tym gniazdem.
- Kontynuacji "nasłuchu" połączeń od innych klientów na gnieżdzie serwera.
Poniższy schemat ilustruje oprogramowanie serwera.
String host = ...; // nazwa hosta
int port = ...; // numer portu
InetSocketAddress isa = new InetSocketAddress(host, port);
// Utworzenie gniazda serwera
ServerSocket serverSock = new ServerSocket();
// Związanie gniazda serwera z adresem hosta i portu
serverSock.bind(isa);
// W pętli następuje akceptacja połączeń kolejnych klientów
// i obsługa ich zleceń
boolean serverIsRunning = true; // przy zamykaniu serwera
// ustalane na false (np. przez inny wątek)
while (serverIsRunning) {
// akceptacja połączenia
// i utworzenie gniazda komunikacji z połączonym klientem
Socket connection = serverSock.accept();
// obsługa zleceń klienta
// za pośrednictwem strumieni we/wy związanych z gniazdem connection
// ...
// po zakończeniu interakcji z klientem
// - zamknięcie strumieni i gniazda
// ...
connection.close()
}
// zamknięcie gniazda serwera
serverSock.close();
Przy tworzenie adresu gniazda (InetSocketAddress) podajemy host serwera oraz
port poprzez który serwer będzie dostępny dla klientów.
W naszych eksperymentach domowych jako host możemy podać "localhost" (lub adres "127.0.0.1").
Specyfikując numer portu, należy pamiętać o tym, że pierwsze 1024 porty są
zarezerwowane (wspominane wcześniej "dobrze-znane-porty"). Możemy oczywiście
pisać serwer FTP czy HTTP, ale użycie właściwych dla nich numerów portów
wymaga uprawnień administrtora systemu (przy braku takich uprawnień, używamy
dostępnych numerów portów, czasem konwencjonalnych np. dla serwera HTTP -
8080).
Metoda bind(...) wiąże gniazdo serwera z podanym adresem. Możemy podać również
- jako jej drugi argument - maksymalną liczbę klientów oczekujących na połączenie
(domyślnie jest to liczba 50). Wtedy przy wydłużeniu kolejki oczekujących
klientów poza podaną liczbę, kolejni próbujący łączyć sie z serwerem klienci
będą uzyskiwać odmowę połączenia (wyjątek "Connection refused").
Metoda accept() jest blokująca i wstrzymuje wykonanie wątku do chwili
zgłoszenia chęci połączenia ze strony klienta (klient łączy się z serwerem,
podając - czy to w konstruktorze klasy Socket, czy w metodzie connect() host
serwera i numer portu, który przydzielił sobie serwer). Gdy połączenie jest
akceptowane, metoda accept() zwraca gniazdo (obiekt klasy Socket), poprzez
które będzie odbywać się interakcja klienta z serwerem.
Metoda accept() zmoże sygnalizować m.in. wyjątek SocketTimeoutException, który
powstaje, gdy przekroczony zostanie limit czasowy na uzyskanie połączenia.
Dla gniazda serwera możemy ustalić ten limit za pomocą metody setSoTimeout().
Od gniazda, zwróconego przez metodę accept() można uzyskać strumienie wejściowy
i wyjściowy i za ich pomocą "rozmawiać" z klientem.
Pisząc własny serwer należy przemyśleć i ustalić protokół komunikacji. Oczywiście,
możemy skorzystać z gotowych protokołów (np. HTTP czy FTP). Takie serwery
są jednak już gotowe - celowość pisania własnych serwerów HTTP czy FTP jest
uzasadniona tylko w przypadkach jakiegoś testowania czy też specjalnego dostosowywania
tych protokołów. Najczęściej zatem będziemy tworzyć całkiem nowy, własny protokół.
Zilustruje to przykład serwera - książki telefonicznej. Serwer ma dostęp
do "bazy" numerów telefonów. Dla prostoty wykorzystamy mapę, w której osobom-kluczom
będą przypisane numery telefonów - wartości, a dostęp do niej zrealizujemy
poprzez klasę PhoneDirectory.
import java.util.*;
import java.io.*;
public class PhoneDirectory {
private Map pbMap = new HashMap();
public PhoneDirectory(String fileName) {
// Inicjalna zawartość książki telefonicznej
// jest wczytywana z pliku o formacie
// imię numer_telefonu
try {
BufferedReader br = new BufferedReader(
new FileReader(fileName));
String line;
while ((line = br.readLine()) != null) {
String[] info = line.split(" +", 2);
pbMap.put(info[0], info[1]);
}
} catch (Exception exc) {
exc.printStackTrace();
System.exit(1);
}
}
// Zwraca numer telefonu dla podanej osoby
public String getPhoneNumber(String name) {
return (String) pbMap.get(name);
}
// Dodaje nową osobę do książki
// Wynik:
// - true - dodana
// - false - nie (przy próbie dodania osoby zapisanej już w książce)
public boolean addPhoneNumber(String name, String num) {
if (pbMap.containsKey(name)) return false;
pbMap.put(name, num);
return true;
}
// Zastępuje numer podanej osoby nowym
// Wynik:
// - true (numer zastąpiony)
// - false (nie - próba podania nowegu numeru nieistniejącej osoby)
public boolean replacePhoneNumber(String name, String num) {
if (!pbMap.containsKey(name)) return false;
pbMap.put(name, num);
return true;
}
}
Serwer obsługuje zlecenia klientów:
- get imię (podaj numer telefonu dla wskazanej osoby),
- add imię numer (dopisz do książki osobę i jej numer telefoniczny),
- replace imię numer (zastąp w książece numer telefony pdoanej osoby nowym numerem).
- bye ( zakończenie komunikacji)
Na każde zlecenie klienta serwer odpowiada posyłając (jako jeden wiersz)
kod numeryczny wyniku przetworzenia zlecenia oraz opis tego wyniku. Przy
zleceniu get posyłany jest w odpowiedzi dodatkowy, kolejny wiersz zawierający
numer telefonu.
Ustalimy następujące kody:
0 - zlecenie wykonane (Ok)
1 - błędna składnia zlecenia lub nieznane zlecenie (Invalid request)
2 - nie znaleziono numeru dla podanej osoby, dotyczy tylko zlecenia get (Not found)
3 - błąd w zleceniu add - próba dodania osoby-numeru, która już istnieje w książce
4 - błąd w zleceniu replace - próba podania nowego numeru dla nie istniejącej osoby
Program serwera podano na wydruku.
import java.net.*;
import java.io.*;
import java.util.regex.*;
public class PhoneBookServer1 {
private PhoneDirectory pd = null; // mapa osoby-numery tel.
private ServerSocket ss = null;
private BufferedReader in = null; // strumienie gniazda
private PrintWriter out = null; // komunikacji z klientem
public PhoneBookServer1(PhoneDirectory pd, ServerSocket ss) {
this.pd = pd;
this.ss = ss;
System.out.println("Server started");
System.out.println("at port: " + ss.getLocalPort());
System.out.println("bind address: " + ss.getInetAddress());
serviceConnections(); // nasłuchiwanie połączeń
}
// Metoda nasłuchuje połączeń od klientów
// po zaakceptowaniu połączenia - tworzy gniazdo komunikacyjne
// i przekazuje obsługę zleceń metdodzie serviceRequest
private void serviceConnections() {
boolean serverRunning = true; // serwer działa ciągle
while (serverRunning) {
try {
Socket conn = ss.accept(); // nasłuch i akceptaccja połączeń
System.out.println("Connection established");
serviceRequests(conn); // obsługa zleceń dla tego połączenia
} catch (Exception exc) {
exc.printStackTrace();
}
} // zamknięcie gniazda serwera
try { ss.close(); } catch (Exception exc) {}
}
// wzorzec do rozbioru zlecenia (maks. trzy "słowa" rozdzielone spacjami)
private static Pattern reqPatt = Pattern.compile(" +", 3);
// Słowne komunikaty serwera
// odpowidające im indeksy tablicy - kody wyniku
private static String msg[] = { "Ok", "Invalid request", "Not found",
"Couldn't add - entry already exists",
"Couldn't replace non-existing entry",
};
// Obsługa zleceń od klienta
private void serviceRequests(Socket connection)
throws IOException {
try {
in = new BufferedReader( // utworzenie strumieni
new InputStreamReader(
connection.getInputStream()));
out = new PrintWriter(
connection.getOutputStream(), true);
// Odczytywanie zleceń (line zawiera kolejne zlecenie)
for (String line; (line = in.readLine()) != null; ) {
String resp; // odpowiedź
String[] req = reqPatt.split(line, 3); // rozbiór zlecenia
String cmd = req[0]; // pierwsze słowo - polecenie
if (cmd.equals("bye")) { // zlecenie "bye" - koniec komunikacji
writeResp(0, null);
break;
}
else if (cmd.equals("get")) { // "get" - klient chce dostać nr tel.
if (req.length != 2) writeResp(1, null);
else {
String phNum = (String) pd.getPhoneNumber(req[1]); // pobranie
if (phNum == null) writeResp(2, null); // numeru tel.
else writeResp(0, phNum); // i zapis
}
}
else if (cmd.equals("add")) { // "add" - klient chce dodać numer
if (req.length != 3) writeResp(1, null);
else {
boolean added = pd.addPhoneNumber(req[1], req[2]); // dodany?
if (added) writeResp(0, null); // tak - ok
else writeResp(3, null); // nie
}
}
else if (cmd.equals("replace")) { // klient chce zmienić nr tel.
if (req.length != 3) writeResp(1, null);
else {
boolean replaced = pd.replacePhoneNumber(req[1], req[2]);
if (replaced) writeResp(0, null);
else writeResp(4, null);
}
}
else writeResp(1, null); // nieznane zlecenie
}
} catch (Exception exc) {
exc.printStackTrace();
} finally {
try { // zamknięcie strumieni
in.close(); // i gniazda
out.close();
connection.close();
connection = null;
} catch (Exception exc) { }
}
}
// Przekazanie odpowiedzi klientowi poprzez zapis do strumienia
// gniazda komuniakcyjnego
private void writeResp(int rc, String addMsg)
throws IOException {
out.println(rc + " " + msg[rc]);
if (addMsg != null) out.println(addMsg);
}
public static void main(String[] args) {
PhoneDirectory pd = null;
ServerSocket ss = null;
try {
String phdFileName = args[0];
String host = args[1];
int port = Integer.parseInt(args[2]);
pd = new PhoneDirectory(phdFileName); // utworzenie mapy numerów z pliku
InetSocketAddress isa = new InetSocketAddress(host, port);
ss = new ServerSocket(); // Utworzenie gniazda serwera
ss.bind(isa); // i związanie go z adresem
} catch(Exception exc) {
exc.printStackTrace();
System.exit(1);
}
new PhoneBookServer1(pd, ss);
}
}
Przykładowy klient, który wykonuje szereg testujących operacji może wyglądać tak jak na poniższym wydruku.
import java.net.*;
import java.io.*;
public class PhoneBookClient {
private Socket sock = null;
private PrintWriter out = null;
private BufferedReader in = null;
public PhoneBookClient(String host, int port) {
try {
sock = new Socket(host, port);
out = new PrintWriter(sock.getOutputStream(), true);
in = new BufferedReader(
new InputStreamReader(
sock.getInputStream()));
makeRequest("get Asia");
makeRequest("get Alicja");
makeRequest("add Adam 77777");
makeRequest("add Adam");
makeRequest("get Adam");
makeRequest("add Adam 333333");
makeRequest("replace Adam 333333");
makeRequest("replace Alicja 202020");
makeRequest("get Adam");
makeRequest("add");
makeRequest("");
makeRequest("bye");
in.close();
out.close();
sock.close();
} catch (UnknownHostException e) {
System.err.println("Nieznany host: "+host);
System.exit(2);
} catch (IOException e) {
System.err.println("I/O err dla");
System.exit(3);
} catch (Exception exc) {
exc.printStackTrace();
System.exit(4);
}
}
private boolean makeRequest(String req) throws IOException {
System.out.println("Request: " + req);
out.println(req);
String resp = in.readLine();
System.out.println(resp);
boolean ok = resp.startsWith("0");
if (req.startsWith("get") && ok)
System.out.println(in.readLine());
return ok;
}
public static void main(String[] args) {
new PhoneBookClient(args[0], Integer.parseInt(args[1]));
}
}
Po kompilacji programów, uruchamiamy serwer w sesji znakowej poleceniem i otrzymujemy potwierdzenie uruchomienia serwera:
>java PhoneBookServer1 Book.txt localhost 2300
Server started
at port: 2300
bind address: localhost/127.0.0.1
Wybraliśmy tu port 2300 i wszyscy klienci łączący się z tym serwerem będą musieli korzystać z tego portu.
Klienta uruchamiamy w innej sesji znakowej (jako odrębny proces):
>java PhoneBookClient localhost 2300
Po uruchomieniu, klient podejmie próbę połączenia z serwerem, nasłuchująca
metoda accept() serwera przyjmie połączenie, a nasz program serwera wypisze
inforrmację o ustanowieniu połączenia:
Connection established
Od tego momentu zacznie się interakcja klienta i serwera. Klient będzie posyłał
kolejne polecenia (zapisanie w programie przykaądowym), a serwer je realizował
i odpowiadał klientowi podając wynik przetworzenia zlecenia oraz (ew.) dodatkową
informację (numery telefonów). W programie klienta zapewniono wypisywanie
na konsoli kolejnych kroków tej komunikacji. Wygląda to tak.
Request: get Asia
0 Ok
171717
Request: get Alicja
2 Not found
Request: add Adam 77777
0 Ok
Request: add Adam
1 Invalid request
Request: get Adam
0 Ok
77777
Request: add Adam 333333
3 Couldn't add - entry already exists
Request: replace Adam 333333
0 Ok
Request: replace Alicja 202020
4 Couldn't replace non-existing entry
Request: get Adam
0 Ok
333333
Request: add
1 Invalid request
Request:
1 Invalid request
Request: bye
0 Ok
Opisywany serwer "telefoniczny" ma jedną bardzo istotną wadę: nie jest przygotowany
do tego by równolegle obsługiwać wielu klientów.
Ilustruje to fragmencik programu, tworzący trzech klientów naszej książki
telefonicznej (działających jako wątki). Każdy z klientów kilkakrotnie pyta
o numer telefonu wlaściwiej dla niego osoby, nie zawłaszczając przy tym całkowicie procesora
(użycie Thread.sleep).
import java.net.*;
import java.io.*;
public class PhoneBookClients extends Thread {
private Socket sock = null;
private PrintWriter out = null;
private BufferedReader in = null;
private String nameToSearch;
public PhoneBookClients(String host, int port, String name ) {
try {
sock = new Socket(host, port);
out = new PrintWriter(sock.getOutputStream(), true);
in = new BufferedReader(
new InputStreamReader(
sock.getInputStream()));
nameToSearch = name;
} catch (Exception exc) {
exc.printStackTrace();
System.exit(4);
}
start();
}
public void run() {
try {
for (int i=1; i <= 5; i++) {
find(nameToSearch);
Thread.sleep(500);
}
out.println("bye");
} catch (Exception exc) {
exc.printStackTrace();
}
}
private void find(String name) throws IOException {
out.println("get " + name);
String resp = in.readLine();
boolean ok = resp.startsWith("0");
String tel = ok ? in.readLine() : " - not found";
System.out.println(name + " - tel. " + tel);
}
public static void main(String[] args) {
String host = args[0];
int port = Integer.parseInt(args[1]);
String[] names = { "Asia", "Adam", "Jacek" };
for (int i=0; i<names.length; i++)
new PhoneBookClients(host, port, names[i]);
}
}
Zatem każdy klient jest wywłaszczany i wtedy o nuner telefonu ma szansę zapytać inny klient.
Nic takiego się jednak nie dzieje, bowiem nasz serwer nie potrafi równolegle
obsługiwać wielu klientów i musi zawsze zakończyć rozpoczetą komunikację.
W efekcie klienci obsługiwani są po kolei (a nie rownolegle) co obrazuje
wynik działania programu.
>java PhoneBookClients localhost 2300
Asia - tel. 171717
Asia - tel. 171717
Asia - tel. 171717
Asia - tel. 171717
Asia - tel. 171717
Adam - tel. 333333
Adam - tel. 333333
Adam - tel. 333333
Adam - tel. 333333
Adam - tel. 333333
Jacek - tel. 111111
Jacek - tel. 111111
Jacek - tel. 111111
Jacek - tel. 111111
Jacek - tel. 111111
Serwery działające w ten sposób noszą nazwę serwerów sekwencyjnych.
Ich użyteczność jest ograniczona: zwykle wymaga się bowiem by serwer obsługiwał równolegle wielu klientów.
5.11. Serwery wielowątkowe
Klasycznym rozwiązaniem wspomnianego przed chwilą problemu jest zastosowanie współbieżności w programowaniu serwerów.
Jednym z możliwych podejść jest:
- utworzenie gniazda serwera (ServerSocket) i związanie go z adresem (bind),
- po czym uruchomienie wielu wątków serwera, każdy z których będzie rownolegle
nasłuchiwał i akceptował połączenia na tym gnieździe i obsługiwał akceptowane
połączenia.
Przyjrzyjmy się temu rozwiązaniu w praktyce na przykładzie zmodyfikowanego
serwera "ksiązki telefonicznej", który teraz uczynimy wielowątkowym.
import java.net.*;
import java.io.*;
import java.util.regex.*;
public class PhoneBookServerMT1 extends Thread {
private PhoneDirectory pd = null;
private ServerSocket ss = null;
private BufferedReader in = null;
private PrintWriter out = null;
private volatile boolean serverRunning = true; // można zakończyć wątek
// metodą ustalającą
// wartość tej zmiennej na false
private String serverTID; // identyfikator wątku
public PhoneBookServerMT1(String serverTID, PhoneDirectory pd,
ServerSocket ss) {
this.serverTID = serverTID;
this.pd = pd;
this.ss = ss;
System.out.println("Server " + serverTID + " started");
System.out.println("listening at port: " + ss.getLocalPort());
System.out.println("bind address: " + ss.getInetAddress());
start(); // uruchomienie wątku
}
public void run() {
while (serverRunning) {
try {
Socket conn = ss.accept();
System.out.println("Connection established by " + serverTID);
serviceRequests(conn);
} catch (Exception exc) {
exc.printStackTrace();
}
} // zamknięcie gniazda serwera
try { ss.close(); } catch (Exception exc) {}
}
// Pozoatełe metody m.in.serviceRequest jak w poprzednio pokazanej klaeie
private void serviceRequests(Socket connection) {
// ...
}
private void writeResp(int rc, String addMsg)
throws IOException {
// ...
}
public static void main(String[] args) {
final int SERVERS_NUM = 4; // liczba serwerów
PhoneDirectory pd = null;
ServerSocket ss = null;
try {
String phdFileName = args[0];
String host = args[1];
int port = Integer.parseInt(args[2]);
pd = new PhoneDirectory(phdFileName);
InetSocketAddress isa = new InetSocketAddress(host, port);
ss = new ServerSocket();
ss.bind(isa);
} catch(Exception exc) {
exc.printStackTrace();
System.exit(1);
}
// Start wielu wątków (serwerow) dzialających równolegle
// na tym samym gnieżdzie serwera
for (int i=1; i <= SERVERS_NUM; i++) {
new PhoneBookServerMT1("serv thread " + i, pd, ss);
}
}
}
Tym razem nasza klasa serwera dziedziczy Thread, a jej obiekty-wątki są uruchamiane
metodą start() z konstruktora. Akceptacja i obsługa połączeń (przekazywana
metodzie serviceRequests) jest zapisana w metodzie run(). Zatem każdy z uruchomionych
wątków-serwerów jest zdolny do równoległej z innymi wątkami-serwerami obsługi
połączeń od klientów.
W metodzie main() tworzymy kilka egzemplarzy serwerów. Po uruchomieniu programu uzyskamy następujące komunikaty:
>java PhoneBookServerMT1 Book.txt localhost 2300
Server serv thread 1 started
listening at port: 2300
bind address: localhost/127.0.0.1
Server serv thread 2 started
listening at port: 2300
bind address: localhost/127.0.0.1
Server serv thread 3 started
listening at port: 2300
bind address: localhost/127.0.0.1
Server serv thread 4 started
listening at port: 2300
bind address: localhost/127.0.0.1
Cztery serwery czekają tu na połączenia klientów. Każdy z nich może je zaakceptować i obsłużyć zlecenia.
Teraz nasz poprzedni program testujący, w którym trzy wątki klienckic pytały
po kilka razy o telefony (jeden - do Asi, drugi - do Adama, trzeci - do Jacka)
będzie się wykonywał jak trzeba: klienci będą mieli praktycznie równoległy
dostęp do serwera.
Pokazuje to wydruk działania programu.
>java PhoneBookClients localhost 2300
Adam - tel. 333333
Jacek - tel. 111111
Asia - tel. 171717
Jacek - tel. 111111
Adam - tel. 333333
Asia - tel. 171717
Jacek - tel. 111111
Adam - tel. 333333
Asia - tel. 171717
Jacek - tel. 111111
Adam - tel. 333333
Asia - tel. 171717
Jacek - tel. 111111
Adam - tel. 333333
Asia - tel. 171717
Widzimy tu, że żaden z wątków klienckich nie blokuje innym dostępu do serwera
(w trakcie obsługi zleceń jednego klienta, obsługiwane są również - przez
inny egzemplarz serwera - zlecenia innego klienta).
Inną możlwością zapewnienia współbieżnej obsługi wielu klientów jest wyodrębnienie
wątków obsługi zleceń.
Ideę tą można zrealizować na wiele sposobów skladniowych. Tutaj pokazany
zostanie przykład, w ktorym obsługiwać zlecenia klientów będą obiekty-wątki
klasy RequestHandler (dziedziczącej Thread).
Zobaczmy najpierw co - w tej sytuacji - robi główny fragment serwera.
import java.net.*;
import java.io.*;
public class PhoneBookServerMT2 {
private PhoneDirectory pd = null;
private ServerSocket ss = null;
public PhoneBookServerMT2(PhoneDirectory pd,ServerSocket ss) {
this.pd = pd;
this.ss = ss;
System.out.println("Server started");
System.out.println("listening at port: " + ss.getLocalPort());
System.out.println("bind address: " + ss.getInetAddress());
serviceConnections();
}
private void serviceConnections() {
boolean serverRunning = true;
while (serverRunning) {
try {
Socket conn = ss.accept();
System.out.println("Connection established");
// start wątku obsługi zleceń
new RequestHandler(pd, conn).start();
} catch (Exception exc) {
exc.printStackTrace();
}
}
try { ss.close(); } catch (Exception exc) {}
}
//...
}
Klasę obsługi zleceń (RequestHandler) pokazuje poniższy wydruk.
import java.net.*;
import java.io.*;
import java.util.regex.*;
class RequestHandler extends Thread {
private PhoneDirectory pd = null;
private Socket connection = null;
private BufferedReader in = null;
private PrintWriter out = null;
private static Pattern reqPatt = Pattern.compile(" +", 3);
private static String msg[] = { "Ok", "Invalid request", "Not found",
"Couldn't add - entry already exists",
"Couldn't replace non-existing entry",
};
public RequestHandler(PhoneDirectory pd, Socket connection) {
this.pd = pd;
this.connection = connection;
try {
in = new BufferedReader(
new InputStreamReader(
connection.getInputStream()));
out = new PrintWriter(
connection.getOutputStream(), true);
} catch (Exception exc) {
exc.printStackTrace();
try { connection.close(); } catch(Exception e) {}
return;
}
}
public void run() {
try {
for (String line; (line = in.readLine()) != null; ) {
String resp;
String[] req = reqPatt.split(line, 3);
String cmd = req[0];
if (cmd.equals("bye")) {
writeResp(0, null);
break;
}
else if (cmd.equals("get")) {
if (req.length != 2) writeResp(1, null);
else {
String phNum = (String) pd.getPhoneNumber(req[1]);
if (phNum == null) writeResp(2, null);
else writeResp(0, phNum);
}
}
else if (cmd.equals("add")) {
if (req.length != 3) writeResp(1, null);
else {
boolean added = pd.addPhoneNumber(req[1], req[2]);
if (added) writeResp(0, null);
else writeResp(3, null);
}
}
else if (cmd.equals("replace")) {
if (req.length != 3) writeResp(1, null);
else {
boolean replaced = pd.replacePhoneNumber(req[1], req[2]);
if (replaced) writeResp(0, null);
else writeResp(4, null);
}
}
else writeResp(1, null);
}
} catch (Exception exc) {
exc.printStackTrace();
} finally {
try { // by nie być zbyt drobiazgowym:
connection.close(); // przy zamknięciu gniazda
connection = null; // strumienie są zamykane automatycznie
} catch (Exception exc) { }
}
}
private void writeResp(int rc, String addMsg)
throws IOException {
out.println(rc + " " + msg[rc]);
if (addMsg != null) out.println(addMsg);
}
}
Przy programowaniu serwerów wielowątkowych musimy zadbać o właściwą synchronizację dostępu do wspóldzielonych zasobów.
W przypadku omawianych tu serwerów "książki telefonicznej" takim zasobem jest mapa zdefiniowana w klasie PhoneDirectory.
Nie jest ona synchronizowana, ale możemy ( i powinniśmy) zastąpić ją wersją synchronizowaną:
public class PhoneDirectory {
private Map pbMap = Collections.synchronizedMap(new HashMap());
// ...
}
Uwaga: to rozwiązanie nie zapewnia synchronizacji dostępu do większych fragmentów mapy (np. operacje zbiorcze lub iterowanie).
Ale synchronizacja zmniejsza efektywność dzialania (przypomnijmy programowanie
wspólbieżne). Przy tym, wszystkie rodzaje dostępu będą synchronizowane,
a przecież nie jest to konieczne przy dostępie "tylko do odczytu" (pobieraniu
numerów telefonów).
Może więc moglibyśmy zrobić tak: nie synchronizowac mapy, a jedynie te metody
w klasie PhoneDirectory, które modyfikują jej zawartość. Niestety, to nie
jest dobry pomysł.
Przecież, jeśli nie zsynchronizujemy również metody odczytującej numer telefonu,
to jej wyniki mogą być niespójne z aktualnym stanem mapy (odczyt może pokazać
np. brak numeru, który był akurat zapisywany przez wywłaszczony wątek).
Rozwiązaniem tego dylematu są tzw. read-write locks, semafory, które pozwalają
wątkom czytającym pobierać informacje bez narzutu synchronizacji (o ile akurat
zasób nie jest zajęty przez wątek modyfikujący). Krótkie wprowadznie do tej
problematyki można znaleźć w artukule Amandeep Singha "Implementig Read/Write
Locks in Java" (http://www.asingh.net/technical/rwlocks.html).
W Javie 1.5 mamy w pakiecie java.util.concurrent
interfejs ReadWriteLock oraz jefo implementację w klasie ReentrantReadWriteLock.
5.12. Nieblokujące kanały i użycie selektorów przy programowaniu serwerów
Oba przedstawione w poprzednim punkcie rozwiązania serwerów wielowątkowych mają swoje
wady.
Pierwsze (wiele egzemplarzy serwera) jest praktycznie nieskalowalne
(uruchamiamy zadaną liczbę wątków-serwerów i nie wiadomo czy jest to liczba
za duża czy za mała wobec nie znanych a priori, dynamicznie zmieniających
sie, potrzeb).
W drugim rozwiązaniu - po akceptacji połączenia z klientem - uruchamiamy
odrębny dla każdego klienta wątek obsługi zleceń. Przy bardzo dużej liczbie
klientów, łączących się i kończących połączenia z dużą czestotliwością, powstaje
bardzo dużo wątków i bardzo dużo wątków kończy działanie. Maszyna wirtualna
Java może nie nadążać w tej sytuacji z odśmiecaniem pamięci.
Z problemami skali - częściowo - można radzić sobie prowadząc dynamiczną pulę wątków-połączeń.
W każdym przypadku jednak będziemy mieli do czynienia z pelnowymiarowymi
problemami synchronizacji dostępu do wspólnych zasobów, które to problemy
nie tylko utrudniają programowanie, ale często obniżają efektywność działania
serwera.
Pewnym rozwiązaniem i ułatwieniem jest użycie nieblokujących kanałów gniazd
(zob. też punkt 9 tego wykładu oraz - ogólnie o NIO).
Dla nieblokujacych kanałów możliwe jest ich multipleksowanie czyli obsługiwanie przez jeden wątek wielu kanałów, bowiem klasy kanałów gniazd (SocketChannel i ServerSocketChannel) pochodzą od klasy SelectableChannel, która pozwala na rejestrowanie kanałów do monitorowania przez selektory.
Selektor jest obiektem monitorującym zarejestrowane kanały, reagującym
na zlecenia przychodzące od klientów przez te kanały i przekazującym serwerowi
sygnały o gotowości do wykonania konkretnych operacji na poszczególnych kanałach
"Sygnały gotowości" są przekazywane w kluczach selekcji (obiektach
klasy SelectionKey). Obiekty te zawierają informację o kanale i o rodzaju
operacji, która aktualnie może być na kanale wykonana (jest "gotowa do wykonania").
Ideowy schemat działania slektora przedstawia poniższy rysunek.
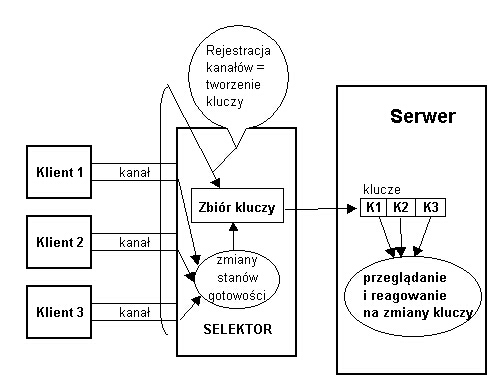
- Najpierw kanały są rejestrowane do monitorowania przez selektor (obiekt
klasy Selector). Rejestracja kanału tworzy klucz selekcji dla tego kanału
(obiekt klasy SelectionKey).
- W kluczach zapisywane są stany gotowości kanałów
do wykonania określonych operacji.
-
Selektor reaguje na zmiany stanów kanałów, wynikające z żądań klientów.
- Gdy
jakiś klient łączy się z serwerem przez kanał, związany z gniazdem serwera,
selektor ustala stan gotowości klucza identyfikującego ten kanał, tak by
klucz wskazywał , że istnieje połączenie gotowe do zaakceptowania przez serwer.
- Gdy klient pisze do kanału komunikacyjnego, selektor ustala stan gotowości
klucza identyfikującego ten kanał, tak by wskazywał na to, że w kanale
są gotowe dane do odczytania
Wkażdym momencie może być dostępnych wiele kluczy w zbiorze kluczy, opisujących gotowe do wykonania operacje.
Serwer przegląda
ten (zmieniający się) zbiór kluczy i odpowiednio do rodzaju gotowych do wykonania operacji wykonuje
je na identyfikowanych przez klucze kanalach. Ponieważ kanały są w trybie nieblokującym,
to operacje kanałowe nie blokują wątku.
W tej sytuacji obsługa zleceń klientów może być wykonywana synchronicznie (!!!).
W przeciwieństwie
do także synchronicznie dzialającego serwera sekwencyjnego uzyskujemy przy
tym efekt rownoległej obsługi klientów (o ile obsługa zlecenia nie trwa długo).
Serwer sekwencyjny musiał bowiem obsłużyć jednego klienta niejako "od początku
do końca" (w naszym przypadku serwera telefonicznego od połączenia, poprzez
wszystkie zlecenia odczytywania czy zapisywania książki telefonicznej, aż
do kończącego komunikację zlecenia "bye").
Natomiast przy nieblokujących
kanałach selektory rozbijają komunikację na pojedyńcze zlecenia (np. odczytu
konkretnego numeru telefonu) i każde takie zlecenie (przychodzące od różnych
klientów przez różne kanały) jest obsługiwane przez serwer niezależnie od
innych.
Przykładowy schemat programowaniu serwerów z użyciem
selektorów
1 | Utworzenie kanału gniazda serwera
i związanie go z konkretnym adresem (host+port)
|
String host = ...;
int port = ...;
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.socket().bind(new InetSocketAddress(host, port));
|
Uwaga: metoda socket() z klasy ServerSocketChannel
zwraca skojarzone z kanałem gniazdo klasy ServerSocket. Używamy tu jednej
z wersji metody bind tej klasy.
|
2 | Ustalenie trybu nieblokującego
dla kanału serwera gniazda
|
serverChannel.configureBlocking(false);
|
Uwaga: kanały rejestrowane z selektorami
(a więc przeznaczone do multipleksowania) muszą być skonfigurowane w trybie
nieblokującym i nie można zmienić tego trybu na blokujący, zanim kanał nie zostanie wyrejestrowany.
|
.
3 |
Utworzenie selektora
|
Selector selector = Selector.open();
|
Statyczna metoda open() z klasy Selector
zwraca refencję do obiektu-selektora, który jest tworzony przez domyślnego,
systemowego kreatora selektorów. Można jednak stworzyć własną klasę "dostawcy
selektorów" dostarczającą selektory niejako "własnej konstrukcji".
|
4
| Rejestracja kanału gniazda serwera u selektora
|
SelectionKey sscKey = serverChannel.register(selector,
SelectionKey.OP_ACCEPT);
|
Drugi argument wywolania określa rodzaje
operacji na danym kanale, którymi jesteśmy zainteresowani przy wykorzystaniu
tego selektora do wyboru operacji.
Rodzaje operacji są określane przez bity liczby całkowitej i możemy je podawać
jako bitową alternatywę następujących stałych statycznych typu int z klasy
SelectionKey:
OP_ACCEPT
Akceptacja połaczenia. | OP_CONNECT
Operacja łączenie (kanały gniazd klienckich). | OP_READ
Operacja czytania | OP_WRITE
Operacja pisania |
Na kanale gniazda serwera interesują nas tylko gotowe do zaakceptowania połączenia - dlatego podajemy SelectionKey.OP_ACCEPT.
Uwaga: można specyfikować tylko operacje właściwe dla danego rodzaju kanału.
Dopuszczalen operacje możemy uzyskać od kanału za pomocą metody validOps().
Rodzaje operacji są właściwoscią tworzonego przez rejestrację klucza. Możemy
je w każdej chwili zmienić za pomocą metody interestOps(int) z klasy SelectionKey.
Metoda zwraca klucz selekcji dla zarejestrowanego kanału.
Kanał zostaje wyrejestrowany, gdy wobec klucza reprezentującego jego rejestrację
(zwróconego przez metodę register) zastosujemy odwołanie cancel, lub gdy
kanał zostanie zamknięty.
|
5 | Selekcja gotowych operacji do wykonania i ich obsługa
w pętli dzialania serwera
|
for(;;) { // Nieskończona pętla działania serwera
// Selekcja gotowej operacji
// To wywolanie jest blokujące
// Czeka aż selektor powiadomi
// o gotowości jakiejś operacji na jakimś kanale
selector.select();
// Teraz jakieś operacje są gotowe do wykonania
// Zbiór kluczy opisuje te operacje (i kanały)
Set keys = selector.selectedKeys();
// Przeglądamy "gotowe" klucze
Iterator iter = keys.iterator();
while(iter.hasNext()) {
// pobranie klucza
SelectionKey key = (SelectionKey) iter.next();
// musi być usunięty ze zbioru (nie ma autonatycznego usuwania)
// w przeciwnym razie w kolejnym kroku pętli "obsłużony" klucz
// dostalibyśmy do ponownej obsługi
iter.remove();
// Wykonanie operacji opisywanej przez klucz
if (key.isAcceptable()) { // połaczenie klienta gotowe do akceptacji
// Uzyskanie kanału do komunikacji z klientem
// accept jest nieblokujące, bo już klient czeka
SocketChannel cc = serverChannel.accept();
// Kanał nieblokujący, bo będzie rejestrowany u selektora
cc.configureBlocking(false);
// rejestrujemy kanał komunikacji z klientem
// do monitorowania przez ten sam selektor
cc.register(selector, SelectionKey.OP_READ | OP_WRITE);
continue;
}
if (key.isReadable()) { // któryś z kanałów gotowy do czytania
// Uzyskanie kanału na którym czekają dane do odczytania
SocketChannel cc = (SocketChannel) key.channel();
// obsługa zleceń klienta
// ...
continue;
}
if (key.isWriteable()) { // któryś z kanałów gotowy do pisania
// Uzyskanie kanału
SocketChannel cc = (SocketChannel) key.channel();
// pisanie do kanału
// ...
continue;
}
}
}
|
Pokazaną pętlę działania serwera można bliżej wyjasnić w następujący sposób..
Metoda select() wstrzymuje dzialanie pętli dopóki selektor moniturający zarejestrowane
u niego kanały nie określi gotowych do wykonania operacji. Gotowe operacje
są reprezentowane przez podzbiór wszystkich kluczy (tzw. selected-keys set)
i podzbiór ten przy każdorazowym wywołaniu select() jest przez selektor modyfikowany
zgodnie z aktualnym stanem kanałów. W każdym kroku pętli przeglądany jest
aktualny zbiór "selected-keys" (metoda selectedKeys()) i dla każdego klucza
z tego zbioru wykonywane są na kanale identyfikowanym przez ten klucz (kanał
uzyskujemy od klucza za pomocą metody channel()) określone przez klucz operacje
(rodzaj operacji uzyskujemy wołając metody isAccepteble(), isReadable(),
isWriteable()).
Sczególną operacją jest akceptacja połączenia nowego klienta. Jak wspomniano
na schemacie wywolanie metody accept() tym razem nie jest blokujące (bo selektor
już określił, że na kanale gniazda serwera czeka kolejny klient). Wywołując
metodę accept() natychmiast więc tworzymy kanał komunikacji z klientem (SocketChannel).
Ten kanał rejestrujemy u tego samego selektora który monitoruje kanał gniazda
serwera i inne kanały klienckie (zwrócmy uwagę - mamy tu jeden selektor).
W ten sposób ta sama pętla, w sposób jednolity, obsługuje wszystkie zlecenia.
Tę właściwość pokazanego podejścia ilustruje poniższy rysunek.
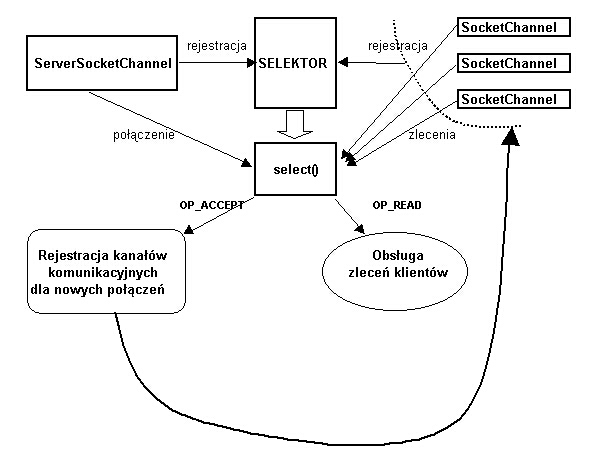
Mamy już teraz wystarczające wiadomości, aby napisać omawiany w poprzednich
punktach serwer "książki telefonicznej" w konwencji nieblokującego we/wy
i selektorów.
Jego kod może wyglądać tak.
import java.net.*;
import java.io.*;
import java.util.*;
import java.util.regex.*;
import java.nio.*;
import java.nio.channels.*;
import java.nio.charset.*;
public class PhoneBookServerNB {
private PhoneDirectory pd = null;
private ServerSocketChannel ssc = null;
private Selector selector = null;
public PhoneBookServerNB(PhoneDirectory pd, String host, int port ) {
this.pd = pd;
try {
// Utworzenie kanału dla gniazda serwera
ssc = ServerSocketChannel.open();
// Tryb nieblokujący
ssc.configureBlocking(false);
// Ustalenie adresu (host+port) gniazda kanału
ssc.socket().bind(new InetSocketAddress(host, port));
// Utworzenie selektora
selector = Selector.open();
// Zarejestrowanie kanału do obsługi przez selektor
// dla tego kanału interesuje nas tylko nawiązywanie połączeń
// tryb - OP_ACCEPT
ssc.register(selector,SelectionKey.OP_ACCEPT);
} catch(Exception exc) {
exc.printStackTrace();
System.exit(1);
}
System.out.println("Server started and ready for handling requests");
serviceConnections();
}
private void serviceConnections() {
boolean serverIsRunning = true;
while(serverIsRunning) {
try {
// Wywołanie blokujące
// czeka na zajście zdarzenia związanego z kanałami
// zarejestrowanymi do obslugi przez selektor
selector.select();
// Coś się wydarzyło na kanałach
// Zbiór kluczy opisuje zdarzenia
Set keys = selector.selectedKeys();
Iterator iter = keys.iterator();
while(iter.hasNext()) { // dla każdego klucza
SelectionKey key = (SelectionKey) iter.next(); // pobranie klucza
iter.remove(); // usuwamy, bo już
// go zaraz obsłużymy
if (key.isAcceptable()) { // jakiś klient chce się połączyć
// Uzyskanie kanału do komunikacji z klientem
// accept jest nieblokujące, bo już klient się zgłosił
SocketChannel cc = ssc.accept();
// Komunikacja z klientem - nieblokujące we/wy
cc.configureBlocking(false);
// rejestrujemy kanał komunikacji z klientem
// do obsługi przez selektor
// - typ zdarzenia - dane gotowe do czytania przez serwer
cc.register(selector, SelectionKey.OP_READ);
continue;
}
if (key.isReadable()) { // któryś z kanałów gotowy do czytania
// Uzyskanie kanału na którym czekają dane do odczytania
SocketChannel cc = (SocketChannel) key.channel();
serviceRequest(cc); // obsluga zlecenia
continue;
}
}
} catch(Exception exc) {
exc.printStackTrace();
continue;
}
}
}
private static Pattern reqPatt = Pattern.compile(" +", 3);
private static String msg[] = { "Ok", "Invalid request", "Not found",
"Couldn't add - entry already exists",
"Couldn't replace non-existing entry",
};
// Strona kodowa do kodowania/dekodowania buforów
private static Charset charset = Charset.forName("ISO-8859-2");
private static final int BSIZE = 1024;
// Bufor bajtowy - do niego są wczytywane dane z kanału
private ByteBuffer bbuf = ByteBuffer.allocate(BSIZE);
// Tu będzie zlecenie do pezetworzenia
private StringBuffer reqString = new StringBuffer();
// Obsługa (JEDNEGO) zlecania
private void serviceRequest(SocketChannel sc) {
if (!sc.isOpen()) return; // jeżeli kanał zamknięty - nie ma nic do roboty
// Odczytanie zlecenia
reqString.setLength(0);
bbuf.clear();
try {
readLoop: // Czytanie jest nieblokujące
while (true) { // kontynujemy je dopóki
int n = sc.read(bbuf); // nie natrafimy na koniec wiersza
if (n > 0) {
bbuf.flip();
CharBuffer cbuf = charset.decode(bbuf);
while(cbuf.hasRemaining()) {
char c = cbuf.get();
if (c == '\r' || c == '\n') break readLoop;
reqString.append(c);
}
}
}
// Analiza zlecenia (jak poprzednio) i wołanie nowej metody
// writeResp zapisującej odpowiedź do kanału
String[] req = reqPatt.split(reqString, 3);
String cmd = req[0];
if (cmd.equals("bye")) { // koniec komunikacji
writeResp(sc, 0, null); // - zamknięcie kanału
sc.close(); // i gniazda
sc.socket().close();
}
else if (cmd.equals("get")) {
if (req.length != 2) writeResp(sc, 1, null);
else {
String phNum = (String) pd.getPhoneNumber(req[1]);
if (phNum == null) writeResp(sc, 2, null);
else writeResp(sc, 0, phNum);
}
}
else if (cmd.equals("add")) {
if (req.length != 3) writeResp(sc, 1, null);
else {
boolean added = pd.addPhoneNumber(req[1], req[2]);
if (added) writeResp(sc, 0, null);
else writeResp(sc, 3, null);
}
}
else if (cmd.equals("replace")) {
if (req.length != 3) writeResp(sc, 1, null);
else {
boolean replaced = pd.replacePhoneNumber(req[1], req[2]);
if (replaced) writeResp(sc, 0, null);
else writeResp(sc, 4, null);
}
}
else writeResp(sc, 1, null); // nieznane zlecenie
} catch (Exception exc) { // przerwane polączenie?
exc.printStackTrace();
try { sc.close();
sc.socket().close();
} catch (Exception e) {}
}
}
private StringBuffer remsg = new StringBuffer(); // Odpowiedź
private void writeResp(SocketChannel sc, int rc, String addMsg)
throws IOException {
remsg.setLength(0);
remsg.append(rc);
remsg.append(' ');
remsg.append(msg[rc]);
remsg.append('\n');
if (addMsg != null) {
remsg.append(addMsg);
remsg.append('\n');
}
ByteBuffer buf = charset.encode(CharBuffer.wrap(remsg));
sc.write(buf);
}
public static void main(String[] args) {
try {
String phdFileName = args[0];
String host = args[1];
int port = Integer.parseInt(args[2]);
PhoneDirectory pd = new PhoneDirectory(phdFileName);
new PhoneBookServerNB(pd, host, port);
} catch(Exception exc) {
exc.printStackTrace();
System.exit(1);
}
}
}
W programie tym warto zwrócić uwagę na zastosowanie buforów i na sposób radzenia sobie z niepewnością
co do liczby odczytanych w jednej operacji read() bajtów przy nieblokującym
wejściu-wyjściu. Na uwagę zasługuje również staranie by nie tworzyć zbyt
wielkiej liczby obiektów. Dlatego bufor bajtowy, wykorzystywany do czytania
z kanału utworzono i alokowano jednorazowo na poziomie pól klasy. Takie podejście
jest uzasadnione, gdy nie ma wielu wątków, które mogłyby dzielić ten zasób.
No, właśnie, nasza nowy serwer w ogóle nie wykorzystuje wątków i nie mamy
rownież problemów z synchronizacją odwołań do klasy PhoneDirectory (bowiem
wszystkie operacje na zawartej w niej mapie są wykonywane synchronicznie,
kolejno).
A jego działanie jest tak samo efektywne przy równoległej obsłudze wielu
klientów, jak działanie serwerów wielowątkowych (ale: z mutexami, w środowiskach jednoprocesorowych).
Trzeba jednak wyraźnie podkreślić, że w praktycznym programowaniu "poważnych"
serwerów stosowane są zarówno selektory jak i wspólbieżność (pule wątków).
Tylko w ten sposób można uzyskać wymaganą efektywność działania, a zastosowanie
nieblokującego wejścia-wyjścia i selektorów pomaga przy tym rozwiązywać problemy
skalowalności i syncjronizacji.
W takich zastosowanich używane są jeszcze inne środki klas SelectableChannel,
Selector i SelectionKey. Na koniec więc krótko o nich:
- istnieje wersja metody register(...) z klasy SelectableChannel, pozwalająca
podać - jako trzeci argument - dowolny obiekt, który będzie związany z utworzonym
przy rejestracji kluczem. Możemy też związać obiekt z kluczem już po rejestracji
za pomocą metody attach(Object) z klasy SelctionKey. Obiekt ten póżniej -
w fazie selekcji gotowych do wykonania operacji - będziemy mogli uzyskać
od klucza za pomocą metody attachment() i wykorzystać np. do wykonania wybranej
operacji. Pozwala to nie tylko na lepszą strukturyzację kodu, ale jest jednym
ze sposobów uruchamiania wątków obsługi zleceń;
- oprócz blokującej metody select() w klasie Selector mamy do dyspozycji
dwie inne wersje tej metody: select(long) blokuje, ale nie dłużej niż podany
jako arguemnt czas, selectNow() jest wywołaniem nieblokującym (zatem przy
braku gotowosci kanałów i operacji nasz serwer może wykonywac inne czynności,
sprawdzając tę gotowośc co jakiś czas np. 300 ms);
- metoda wakeup() z klasy Selector przerywa blokowanie na select(..);
jest intensywnie używana przy łączeniu "dużej dozy" współbieżności z mechanizmem
selekcji.
5.13. Klasy Javy wspomagające programowanie aplikacji klienckich
Tworząc programy klienckie nie zawsze musimy sięgać do programownaia na poziomie gniazd.
W Javie istnieją zestawy klas, które ukrywają przed programistą szczegóły
komunikacji poprzez gniazda. O jednym takim zestawie już wspominano - jest
nim bogato oprzyrządowany pakiet Java Mail API.
Inne to:
- (niestandardowy) pakiet sun.net.ftp, służący do programowania klientów
FTP (a także liczne, publicznie dostępne pakiety klientów FTP dostępne w
Sieci),
- zestaw klas pozwalajacych na połączenia i komuniakcję z zasobami sieciowymi, w szczególności przy wykorzystaniu protokołu HTTP.
Poniższy program łączy sie z serwerem FTP, w kolejnych dialogach wejściowych
pyta użytkownika o pliki do pobrania i zapisuje je na lokalnym dysku.
import java.io.*;
import sun.net.ftp.FtpClient; // podstawowa klasa pakietu sun.net.ftp
import java.text.*;
import javax.swing.*;
public class FtpFileRetriever {
public static void main(String args[]) {
FtpClient client = null;
String userName = null;
try {
String host = args[0];
userName = args[1];
String password = args[2];
client = new FtpClient(host);
client.login(userName, password); // logowanie
client.binary(); // tryb transmisji - binarny
} catch(Exception exc) {
exc.printStackTrace();
System.exit(1);
}
String dir = null;
String file = "";
String dialogMsg = "Podaj nazwę pliku do pobrania:";
while((file = JOptionPane.showInputDialog(dialogMsg)) != null) {
try {
String fileName = file;
int lastSlash = file.lastIndexOf('/');
// jeżeli w podanej nazwie pliku występuje ścieżka katalogowa
// zmieniamy biezący katalog, jesli nie - pobierany jest plik
// z aktualnego bieżącego katalogu
if (lastSlash != -1) {
fileName = file.substring(lastSlash+1);
dir = file.substring(0,lastSlash);
client.cd(dir); // zmiana biezącego katalogu
}
BufferedInputStream in = new BufferedInputStream(
client.get(fileName) // zwraca strumień
); // do czytania pliku
BufferedOutputStream out = new BufferedOutputStream(
new FileOutputStream(fileName)
);
System.out.println("Pobieram: " + fileName);
byte[] data = new byte[1024];
int bytesRead, totalBytes = 0;
long start = System.currentTimeMillis();
while( (bytesRead = in.read(data)) > 0) {
out.write(data, 0, bytesRead);
totalBytes += bytesRead;
System.out.print("\r... " + totalBytes);
}
out.close();
double sec = (System.currentTimeMillis() - start)/1000.0;
double kb = totalBytes/1024.0;
double kbps = kb/sec;
DecimalFormat dn = new DecimalFormat("#.#");
System.out.println("\nPobieranie ukonczone");
System.out.println("Pobrano " + dn.format(kb) + "KB" +
" - " + dn.format(kbps) + " KB/sek.");
} catch (IOException exc) {
exc.printStackTrace();
}
dialogMsg = "Ostatnio pobrany plik: " + file +'\n' +
"Podaj nazwę pliku do pobrania:";
}
// Zamkniecie połaczenia
try {client.closeServer(); } catch(Exception exc) {}
System.exit(1);
}
}
Działanie tego programiku ilustruje rysunek.
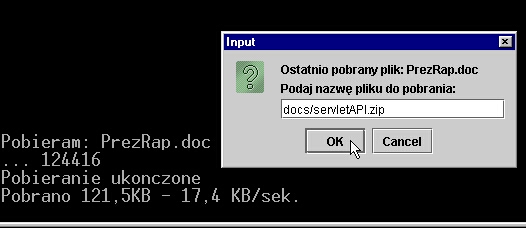
Jak wspomniano, pakiet sun.net.ftp nie należy do standardu Javy.
W pakiecie java.net znajdziemy natomiast standardowe klasy przeznaczone
do pracy z zasobami sieciowymi, m.in. klasy URL i URI oraz URLConnection i HttpURLConnection.
Obiekty klasy URL (Uniform Resource Locator) reprezentują - dobrze chyba
znane wszystkim - adresy zasobów sieciowych (jednolite lokalizatory zasobów).
Składniowo lokalizator taki składa się z kilku części, m.in.:
- opisu protokołu (np. http, ftp, gopher, file)
- nazwy hosta (np. www.ibm.com)
- odniesienia do konkretnego zasobu (np. ścieżki dostępu do pliku i jego nazwy).
Przykład:
http://www.java.sun.con/j2ee/index.html
Konkretne znaczenie treści zasobu zależy od protokołu i hosta (np. http://www.java.sun.com/j2ee/index.html
może oznaczac konkretny dokument lub treść dokumentu generowaną dynamicznie).
Zasoby sieciowe - to nie tylko pliki czy katalogi. mogą oznaczać również
inne rodzaje informacji (np. wynik zapytania kierowanego do bazy danych).
O lokalizatorach zasobów sieciowych bedziemy czasem mówić krótko: url.
URI (Uniform Resource Identifier) jest uogólnieniem pojęcia URL - opisuje
dowolne (fizyczne i abstrakcyjne) zasoby w sieci, które mogą być w jakikolwiek
sposób zidentyfikowane.
Lokalizatory (URLe) są podzbiorem identyfikatorów (URI).
O ile lokalizator (url) opisuje zasób w taki sposób, że jednoznaczny jest
mechanizm dostępu do niego (np. położenie pliku w sieci i protokół), to identyfikator
(URI) może oznaczać zasób o nieznanej lub niejednoznacznej konkretnej lokalizacji
i mechanizmie dostępu, charakteryzujący sie jedynie unikalną, jednoznaczną
nazwą (Uniform Resource Name - URN).
Więcej informacji na ten temat można znaleźć w dokumencie RFC 2396: Uniform Resource Identifiers (URI): Generic Syntax.
URI - identyfikacja, parsowanie
URL - fizyczny dostęp
Klasa URI w Javie nie dostarcza metod dostępu do zasobów (znajdziemy tu
głównie metody służące do rozbioru identyfikatorów na części składowe, normalizacji,
relatywizacji i rozwikływania idnetyfikatorów - o rozwikływaniu zob. w następnym
przykładowym programie).
Natomiast poprzez obiekty klasy URL możemy uzyskać dostęp do zasobów sieciowych i to co najmniej na dwa sposoby.
Najprostszy sposób (zarazem jednak najmniej elastyczny) uzyskiwania dostępu
do zasobow sieciowych polega na wykorzystaniu strumienia wejściowego, związanego
z lokalizatorem zasobu (URLem - obiektem klasy URL).
Kolejne kroki są następujące:
-
stworzyć URL za pomocą jednego z konstruktorów klasy URL (jęsli podamy błędny adres powstanie wyjątek MalformedURLException),
-
uzyskać od niego strumień wejściowy za pomocą metody getInputStream(),
-
odczytać treść zasobu ze strumienia.
Przykładowy program wykorzystujący ten sposób wczytuje podaną stronę WWW
i dokonuje jej analizy składniowej w celu wyróżnia znajdujących się na stronie
plików graficznych, po czym ładuje te pliki i pokazuje w "przeglądarce obrazków",
zbudowanej jako własna klasa ImageViewer.
import java.net.*;
import java.io.*;
import java.util.*;
import java.util.regex.*;
public class SimpleGet {
public SimpleGet(String urlString) {
try {
URL url = new URL(urlString);
BufferedReader in = new BufferedReader(
new InputStreamReader(
url.openStream() // zwraca InputStream
// związany z URLem
));
// Częsci URL-a
String protocol = url.getProtocol();
String host = url.getHost();
String file = url.getFile();
System.out.println("Protocol: " + protocol);
System.out.println("Host: " + host);
System.out.println("File: " + file);
// Zapiszemy dokument za pomocą strumienia StringWriter
StringWriter sw = new StringWriter(10240);
String line;
while ((line = in.readLine()) != null) {
sw.write(line);
}
in.close();
// Matcher do wyodrebniania referencji do plików graficznych na stronie
Matcher matcher = Pattern.compile("img src=\"(.+?)\"",
Pattern.CASE_INSENSITIVE).matcher(sw.toString());
// Obrazy będziemy przechosywać na liście
java.util.List imgList = new ArrayList();
while (matcher.find()) {
String imgRef = matcher.group(1); // wyodrębniamy zapisany na stronie
// url obrazka
// zwykle będzie relatywny
// za pomocą konstruktora URL(kontekst, referencja)
// uzyskamy właściwy lokalizator wskazujący zasób
URL imgUrl = new URL(url, imgRef);
System.out.println(imgRef + " ==> " + imgUrl);
// utworzenie obiektu Image i dodanie do listy
imgList.add(Toolkit.getDefaultToolkit().createImage(imgUrl));
}
System.out.println("Preparation complete... wait for viewer init");
// Listę obrazów przekażemy utworzonemu obiektowi przeglądarki obrazków
new ImageViewer(imgList);
} catch (MalformedURLException exc) {
exc.printStackTrace();
System.exit(1);
} catch (Exception exc) {
exc.printStackTrace();
}
}
public static void main(String[] args) {
String url = JOptionPane.showInputDialog("Adres");
new SimpleGet(url);
}
}
W programie wczytujemy stronę, której adres podano w dialogu i wyodrębniamy
na niej wszystkie zapisane w znacznikach <img src ... > odniesienia
do obrazków.
Takie odniesienie może być relatywne (w stosunku do lokalizacji wczytanej
strony). Dlatego urle obrazków tworzymy za pomoca konstruktora URL(URL context, String spec). Konstruktor ten potrafi:
- rozwikłać relatywne adresy, czyli skomponować url, w którym brakujące w spec składniki są brane z context (urla dokumentu bazowego - czyli adresu wczytanej strony),
- znormalizować rozwikłane adresy, czyli odpowiednio usunąć wszystkie
niepotrzebne "." i ".." (oznaczające w symboliczny sposób: katalog bieżący
i katalog nadrzędny) ze ścieżki opisującej dostep do zasobu.
Przykładowo, jezeli nasz program uruchomimy podając jako adres:
http://bugbog.com/beaches/beach_pictures_thailand/beach_pictures_ko%20samet_4.html;
to na konsoli uzyskamy najpierw wydruk składników urla (ilustracja metod get... pobierających różne cześci lokalizatora);
Protocol: http
Host: bugbog.com
File: /beaches/beach_pictures_thailand/beach_pictures_ko%20samet_4.html
a z części programu wyodrębniającj adresy obrazków uzyskamy wydruk tych
adresów w literalnie zapisanej na stronie postaci, z następującym po znakach
==> adresem rozwikłanym i znormalizowanym przez konstruktor URL(URL context,
String spec):
../../images/beaches/thailand_beaches_west/thailand_beaches_ko_samet_9.jpg
==> http://bugbog.com/images/beaches/thailand_beaches_west/thailand_beaches_ko_samet_9.jpg
../../images/bugbog/bugbog.gif ==> http://bugbog.com/images/bugbog/bugbog.gif
../../images/beaches/thailand_beaches_west/thailand_beaches_ko_samet_7.jpg
==> http://bugbog.com/images/beaches/thailand_beaches_west/thailand_beaches_ko_samet_7.jpg
../../images/beaches/thailand_beaches_west/thailand_beaches_ko_samet_8.jpg
==> http://bugbog.com/images/beaches/thailand_beaches_west/thailand_beaches_ko_samet_8.jpg
../../images/bugbog/line.gif ==> http://bugbog.com/images/bugbog/line.gif
Program z uzyskanych urli obrazków za pomocą metody createImage z klasy Toolkit
tworzy obiekty klasy Image i dodaje je do listy. Ta lista jesr przekazywana
przeglądarce obrazków - ImageViewer.
Klasy ImageViewer i wykorzystaywana przez nią ImagePanel (stanowiąca
obszar prezentacji obrazu z pliku) przedstawiono - dla porządku - na poniższym
wydruku (warto na nie spojrzeć choćby dla przypomnienia wiadomości o kolekcjach
i programowaniu GUI):
import java.util.*;
import java.util.regex.*;
import java.awt.*;
import java.awt.event.*;
import javax.swing.*;
class ImagePanel extends JPanel {
private Image img;
private boolean correct;
private Dimension defd = new Dimension(200,200);
private String msg;
public ImagePanel(String msg) {
this.msg = msg;
setPreferredSize(defd);
setBorder(BorderFactory.createLineBorder(Color.blue, 2));
}
public void setImage(Image img) {
this.img = img;
int w = img.getWidth(this); // szerokość obrazka
int h = img. getHeight(this); // wysokość obrazka
if (w != -1 && w != 0 && h != -1 && h != 0) {
correct = true;
setPreferredSize(new Dimension(w, h));
}
else setPreferredSize(defd);
repaint();
}
public void paintComponent(Graphics g) {
super.paintComponent(g);
if (img != null && correct)
g.drawImage(img, 0, 0, getWidth(), getHeight(), this);
else
g.drawString(msg, 10, 10);
}
}
class ImageViewer extends JFrame implements ActionListener {
private ListIterator lit;
private ImagePanel imagePanel = new ImagePanel("Loading images ...");
private JButton left = new JButton(new ImageIcon("arrow1.gif"));
private JButton right = new JButton(new ImageIcon("arrow2.gif"));
private JButton os = new JButton("<html><b>Oryginalna<br>skala</b></html>");
public ImageViewer(java.util.List imgList) {
lit = imgList.listIterator();
getContentPane().add(imagePanel);
JPanel p = new JPanel(new FlowLayout(FlowLayout.CENTER));
left.addActionListener(this);
right.addActionListener(this);
os.addActionListener(this);
p.add(left); p.add(right); p.add(os);
getContentPane().add(p, "South");
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
pack();
show();
MediaTracker mt = new MediaTracker(this);
int i=0;
while(lit.hasNext()) mt.addImage((Image) lit.next(), ++i);
try {
mt.waitForAll();
} catch (InterruptedException exc) { }
System.out.println("Image viewer ready");
SwingUtilities.invokeLater(new Runnable() {
public void run() { getNext(); }
});
}
public void actionPerformed(ActionEvent e) {
Object src = e.getSource();
if (src == right) getNext();
else if (src == left) getPrevious();
else pack();
}
private boolean lastOperWasNext = true;
private void getNext() {
if (!lastOperWasNext) lit.next();
if (!lit.hasNext()) while (lit.hasPrevious()) lit.previous();
imagePanel.setImage( (Image) lit.next() );
lastOperWasNext = true;
}
private void getPrevious() {
if (lastOperWasNext) lit.previous();
if (!lit.hasPrevious()) while (lit.hasNext()) lit.next();
imagePanel.setImage( (Image) lit.previous() );
lastOperWasNext = false;
}
}
Wynik dzialania programu ilustruje rysunek (dwa przyciski - strzałki, w
programie oznaczane jako left i right) służą do przechodzenia do kolejnych
obrazków; warto przy okazji zwrócić uwage na zastosowanie w tym celu iteratora
listowego).
Przedstawiony bardzo prosty sposób pobierania zasobów (za pomocą strumienia uzyskanego do URLa) ma jednak co najmniej dwie wady:
- nie pozwala na odczytanie i interpretację nagłówków odpowiedzi serwera HTTP,
- nie pozwala na uzyskanie przekazywanych przez serwer kodów błędów HTTP i związanych z nimi komunikatów.
Klasa URLConnection i pochodna od niej HttpURLConnection usuwają te wady,
a co więcej pozwalają nie tylko na odczytywanie treści zasobów, ale również
na posyłanie do serwera innych zleceń HTTP.
No, właśnie - jak w każdym protokole - komunikacja pomiędzy klientem i serwerem
HTTP polega na wymianie zleceń (od klienta) i odpowiedzi (od serwera). Rodzaje
zleceń HTTP podaje poniższa tabela.
|
Zlecenie
(request method)
|
Znaczenie
|
| GET | uzyskanie zasobu identyfikowanego przez URL (odczytanie treści zasobu)
|
| HEAD | Uzyskanie nagłówków
|
| POST | Wysłanie danych o nielimiotowanej długości
|
| PUT | Zapisanie zasobu
|
| DELETE | Usunięcie zasobu
|
| OPTIONS | Zwraca metody HTTP podtrzymywane przez serwer
|
| TRACE | Zwraca nagłówki wysłane z
leceniem TRACE (do celów testowania_
|
Każde zlecenie składa się m.in. z
- nazwy metody zlecenia ,
- nagłówków HTTP zlecenia ,
- treści.
W odpowiedzi serwera również występują nagłówki, opisujące "parametry"
treści odpowiedzi ( np. wielkośc, datę modyfikacji, typ treści)
W odróżnieniu od komunikacji z serwerem HTTP za pomocą gniazd, gdzie do/z
strumieni gniazda zapisuje się/czyta całą wymaganą przez protokół informację
przy zastosowaniu klas URL i URLConnection nagłówki nie mogą być zapisywane
do strumieni i nie mogą być z tych strumieni odczytane.
Analizę nagłówków
odpowiedzi serwera umożliwją metody klasy URLConnection. Klasa ta (wraz z pochodną od niej HttpURLConnection)
pozwala również na wysyłanie do serwera innych od najprostszego GET zleceń HTTP i ustalanie nagłówków tych zleceń.
Komunikację z serwerem HTTP za pomocą klasy URLConnection można przedstawić w nastepujących krokach.
1
|
Tworzymy obiekt klasy URLConnection, wiążąc go z podanym URLem:
URL url = new URL(...);
URLConenction conn = URLConnection.open(url);
|
2
|
Opcjonalnie:
- Za pomocą metody setRequestProperty(String key, String value) ustalamy zawartość nagłówków zlecenia (np. nagłówek "accept-language")
- Za pomocą wywolania metody conn.doOutput() ustalamy, że
zlecenie będzie zleceniem POST, służącym do przesyłania do serwera dowolnych
danych, najczęściej danych formularza HTTP, zapisanych jako parametry zlecenia.
Domyślnie zlecnie jest typu GET (a do ustalenia tego trybu służy metoda doInput). |
3
|
Nawiązujemy połączenie:
conn.connect()
|
4
|
Możemy teraz - jeśli tego potrzebujemy - odczytać
nagłówki przesłane przez serwer za pomocą metod getHeader(...), getHeaders(...)
oraz metod przeznaczonych do odczytywania często używanych nagłówków (np.
getContentType()).
|
5
|
Jeżeli zlecenie jest typu POST (ustalone metodą doOutput()) to za pomoca metody conn.getOutputStream() uzyskujemy dostęp do strumienia wyjściowego połączenia i zapisujemy do niego treśc zlecenia (np. parametry formularza)
|
6
|
Uzyskujemy strumień wejściowy do czytania odpowiedzi serwera (conn.getInputStream()) i za jego pomoca czytamy tę odpowiedź
|
Spójrzmy najpierw na bardzo prosty program, odczytujący z serwera dokument
HTML za pomocą obiektu klasy URLConnection (domyślnie posyłane zlecenie jest
typu GET).
Przy okazji zapoznamy sie ze sposobem uzyskiwania całego zestawu nagłówków
odpowiedzi (w mapie zawierajacej jako klucze nazwy nagłówków a jako wartości
- ich zawartość). Dla często używanych nagłówków (np. contnet-type, content-length)
istnieją dodatkowe odrębne metody pobierania (np. getContentType(), getVontentLength()).
import java.net.*;
import java.io.*;
import java.util.*;
import javax.swing.*;
public class Connection1 {
public Connection1(String urlString) {
try {
URL url = new URL(urlString);
URLConnection conn = url.openConnection();
conn.setUseCaches(false);
conn.connect();
Map map = conn.getHeaderFields();
for (Iterator it = map.keySet().iterator(); it.hasNext(); ) {
String header = (String) it.next();
System.out.println(header + ":" + map.get(header));
}
BufferedReader in = new BufferedReader(
new InputStreamReader(
conn.getInputStream() ) );
for ( String line; (line = in.readLine()) != null; ) {
System.out.println(line);
}
in.close();
} catch (MalformedURLException exc) {
exc.printStackTrace();
System.exit(1);
} catch (FileNotFoundException exc) {
System.out.println("Podanego zasobu nie ma na serwerze");
System.exit(2);
} catch (Exception exc) {
exc.printStackTrace();
}
}
public static void main(String[] args) {
String url = JOptionPane.showInputDialog("Adres");
new Connection1(url);
}
}
Po wprowaddzeniu jakiegoś (prawidłowego) adresu dokumnetu na początku wydruku uzyskamy nagłówki np.
null:[HTTP/1.1 200 OK]
Content-Language:[pl]
Date:[Mon, 17 Nov 2003 02:29:38 GMT]
Accept-Ranges:[bytes]
Server:[Apache]
Content-Type:[text/html; charset=iso-8859-2]
Transfer-Encoding:[chunked]
...
// dalej treśc dokumentu html
Zwróćmy uwagę, interpretacja nagłówków może sie nam przydać do prawidłowego
kodowania treści dokumentu (nagłówek Content-Type będzie często, choć nie
zawsze, podawał stronę kodową).
Zauważmy też, że w pierwszesj linii wydruku podany jest kod odpowiedzi serwera
(200) i związany z nim komunikat (OK - zlecenie było poprawne i uzyskaliśmy
odpowiedź).
Gdyby np. podać nieistniejący plik, to uzyskalibyśmy nagłówki np.:
null:[HTTP/1.1 404 Not Found]
Connection:[Keep-Alive]
Expires:[Tue, 01 Jan 1980 12:00:00 GMT]
Date:[Mon, 17 Nov 2003 02:39:46 GMT]
Keep-Alive:[timeout=15, max=100]
Pragma:[no-cache]
Server:[Apache]
Content-Type:[text/html]
Last-Modified:[Thu, 01 Jan 1970 00:00:00 GMT]
Transfer-Encoding:[chunked]
Cache-control:[no-cache, must-revalidate]
ale przy czytaniu treści odpowiedzi wystąpiłby wyjątek FileNotFoundException.
Na marginesie nalezy dodać tu, że wygodniejszym i bardziej szczegółowym
sposobem identyfikacji wyniku zlecenia jest użycie metod getResponseCode()
i getResponseMessage() z klasy HttpURLConnection (obiekt tej klasy dla URLi
z protokołem HTTP jest zwracany z metody URLConnection.openConnectuin(),
musimy tylko dokonać zawężajacej konwesrji referencyjnej z formalnego typu
URLConncetion do HttpURLConnection).
Drugi przykladowy programik kliencki, używający klasy URLConenction jest
nieco ciekawszy, pokazuje bowiem jak zapisywać zlecenie typu POST. W tym
celu ustalamy właściwość połączenia jako "do pisania" - metodą doOutput().
Możemy także ustalić nagłówki naszego zlecenia. Ustalimy tu język, dzięki
czemu aplikacje dzialajace po stronie serwera bedą mogły wykorzystać informacje
o lokalizacji (np. przesyłać informacje po polsku).
Nastepnie piszemy treść zlecenia do strumienia wyjściowego. Może to być dowolna
informacja, którą umieją przetworzyć aplikacje serwerowe. Najcześciej będziemy
tu zapisywać parametry formularzy HTTP w formie: nazwa_parametru=wartośc_
parametru. Ponieważ przy przekazywaniu parametrów przyjęto konwencje, że
muszą one być specjalnie kodowane (tzw. url-kodowanie), to parametry będziemy
kodować za pomocą klasy URLEncoder (o sczegółach url-kodowania zobacz w dokumentacji
tej klasy).
Po przekazaniu parametrów odczytujemy odpowiedź serwera. Umówimy się, że
aplikacja obsługująca po stronie serwera zlecenia naszego przykładowego klienta
zwraca informacje tekstową o rodzaju zlecenia, lokalizacji, kodowaniu, jego
nagłówkach oraz przekazanych wartościach parametrów.
Klient wypisze te informacje na konsoli.
import java.io.*;
import java.net.*;
public class Client1 {
public static void main(String[] args) throws Exception {
// Z tego pliku przeczytamy zlecnie do posłania
// bedą to pary "nazwa_parametru=wartość"
BufferedReader br = new BufferedReader(
new FileReader(args[0])
);
URL url = new URL("http://...."); // adres aplikacji
// po stronie serwera
// obsługującej klienta
URLConnection connection = url.openConnection();
// Ustalenie nagłówka "accept-language" zlecenia
// Po stronie serwera da to informację o lokalizacji
// Tutaj jej nie używamy, ale może sie przydac w innych okolicznościach
connection.setRequestProperty("accept-language", "pl");
// Będziemy pisać treść zlecenia
connection.setDoOutput(true);
String charset = "UTF-8"; // kodowanie treści
PrintWriter out = new PrintWriter(
new OutputStreamWriter(
connection.getOutputStream(), charset)
);
// Czytamy z pliku i zapisujemy jako treść zlecenia
// pary: nazwa_parametru=wartośc parametru
String line;
while ((line = br.readLine()) != null)
out.println(URLEncoder.encode(line, "UTF-8"));
br.close();
out.close();
System.out.println("Zapis dokonany");
// Odczytujemy odpowiedź serwera
BufferedReader in = new BufferedReader(
new InputStreamReader(
connection.getInputStream(), charset));
while ((line = in.readLine()) != null)
System.out.println(line);
in.close();
}
}
Jesli w pliku podanym jako argument znajdują się zapisy:
parametr1=Pies
parametr2=Kot
parametr3=Wróbel ćwierkający > 20
to program wyprowadzi na konsoli:
Zapis dokonany
Klient wysłał zlecenie
Metoda: POST
Locale: pl
Character encoding: UTF-8
Nagłówki:
accept-language: pl
user-agent: Java/1.4.2
host: localhost:8080
accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2
connection: keep-alive
content-type: application/x-www-form-urlencoded
content-length: 90
Parametry:
parametr1=Pies
parametr2=Kot
parametr3=Wróbel ćwierkający > 20
Warto zauważyć, że do url-kodowania przyjęliśmy bezpieczną stronę kodową
UTF-8. W związku z tym i treści kodujemy w tej stronie kodowej.
Oczywiście, tajemnicze jest nieco skąd akurat bierze sie taka odpowiedź
serwera. Napisano, że tworzy ją aplikacja dzialająca po stronie serwera.
Pora więc na zapoznanie się z takimi aplikacjami i temu poświęcony będzie
następny wykład. Jednocześnie można tam znaleźć dodatkowe infomacje o protokole
HTTP, zleceniach i ich obsłudze, a także kwestiach związanych z formularzami
HTTP i ich parametrami.