Formatowanie, lokalizacja i internacjonalizacja
Pierwsze spotkanie z lokalizacją
double d = 10/3.0;
System.out.println(d);
wynik:
3.3333333333333335
Sformatować wynik.
NumberFormat nf = NumberFormat.getInstance();
nf.setMaximumFractionDigits(3);
String wynik = nf.format(d);
System.out.println(wynik);
wynik (na komputerze w Polsce):
3,333
wynik (na komputerze w Anglii):
3.333
Co się dzieje? Dlaczego?
Lokalizacje
Specyficzne
dla danego języka, regionu/kraju - reguły, dotyczące prezentacji różnych
informacji (np.formatowania liczb i dat, pisowni tekstów, porządku alfabetycznego)
nazwiemy lokalizacją
.
Potrzebny jest mechanizm lokalizacji i internacjonalizacji aplikacji, co wynika z kosztów dostosowania (zmian kodu).
W Javie cały zestaw klas:
java.text i trochę w java.util.
Taligent ====> Sun zastosował w Javie 1.1.
Do dziś bez większych zmian.
Taligent ====> Unicode group w IBM Globalization Center of Competency
w Cupertino (rozwój, przenoszenie do języków C++i C, na zasadach "open source").
Bblioteka International Components for Unicode:
poszerzone wersje klas lokalizacyjno-internacjonalizacyjnych,
a także pewne dodatkowe klasy, których w standardzie Javy brak.
Biblioteka
wdraża najnowsze standardy Unicode (w tej chwili Unicode 4.0) i jest dostępna
w wersjach dla języków Java (ICU4J), C++ i C (ICU4C) na stronie http://www.icu-project.org/
W Javie lokalizacje reprezentowane są przez obiekty klasy Locale z pakietu java.util
.
Lokalizacja określana jest przez kombinację:
- kodu języka,
- kodu kraju,
- kodu wariantu.
Kody te - wartości typu String - podajemy przy tworzeniu obiektu klasy Locale
jako argumenty konstruktora tej klasy, przy czym mamy do dyspozycji trzy
przeciążone konstruktory:
Locale(String language) |
Locale(String language,
String country) |
Locale(String language,
String country,
String variant) |
Kod języka - kombinacja dwóch małych liter, standard
ISO-639 (zob dostępne kody :
http://www.ics.uci.edu/pub/ietf/http/related/iso639.txt
)
Kod kraju - to kombinacja dwóch dużych liter, określająca kraj
wg standardu ISO-3166 (
http://www.chemie.fu-berlin.de/diverse/doc/ISO_3166.html
)
Kod wariantu - dodatkowa informacja, którą możemy dodać i która nie
musi spełniać żadnych standardów, wobec czego jest specyficzna w danych warunkach (np. pakietu lokalizacyjnego) lub dla danej
aplikacji.
Przykłady:
Locale a = new Locale("en", "GB"); // język angielski, kraj Wielka Brytania
Locale b = new Locale("en", "US"); // język angielski, kraj Stany Zjednoczone
Locale c = new Locale("en"); // język angielski, kraj nieokreślony
Locale d = new Locale("pl", "PL", "Zakopane");
Jakie są dostępne lokalizacje?
Locale[] loc = Locale.getAvailableLocales();
Domyślna lokalizacja - na podstawie właściwości ustalonych dla platformy systemowej.
Można się dowiedzieć:
Locale dloc = Locale.getDefault();
i zmienić:
Locale newDefLoc = new Locale(...);
Locale.setDefault(newDefLoc)
Obiekt klasy Locale określa lokalizację (czyli wspomniane wcześniej reguły),
Zastosowanie tych reguł - przy przetwarzaniu i formatowaniu informacji -
spoczywa na obiektach innych klas. Te klasy, które biorą pod uwagę wymagania
lokalizacyjne nazywają się czułymi na lokalizację (locale-sensitive).
Należą do nich:
|
Klasa
|
Przeznaczenie
|
NumberFormat (i pochodne)
|
Do formatowania liczb
|
Calendar (i pochodne)
|
Do operowania na datach i czasie
|
DateFormat (i pochodne)
|
Do formatowania dat i czasu
|
Collator
|
Do określania porządku alfabetycznego
|
BreakIterator
|
Do zlokalizowanego rozbioru tekstu
|
| Scanner | Skanowanie tekstów z różnych źródeł |
| Formatter | Formatowanie danych |
Aby przetwarzać informacje w zlokalizowanej formie posługujemy się obiektami
klas czułych na lokalizację.
Dla zastosowania domyślnych reguł lokalizacyjnych
uzyskujemy te obiekty za pomocą statycznych metod
get...Instance()
bez argumentu, określającego lokalizację.
Np. kod na listingu pokazuje domyślną lokalizację i zgodnie z tą lokalizacją
wypisuje bieżącą datę oraz liczbę 1234567.1, przy czym w trakcie działania
zmienia domyślną lokalizację i ponawia wyprowadzanie informacji.
import java.text.*;
import java.util.*;
public class DefLok {
static public void report() {
Locale defLoc = Locale.getDefault();
System.out.println("Domyślna lokalizacja : " + defLoc);
DateFormat df = DateFormat.getDateInstance(DateFormat.LONG);
NumberFormat nf = NumberFormat.getInstance();
System.out.println(df.format(new Date()));
System.out.println(nf.format(1234567.1));
}
public static void main(String[] args) {
report();
Locale.setDefault(new Locale("en"));
report();
}
}
Wydruk programu:
Domyślna lokalizacja : pl_PL
12 lipiec 2003
1_234_567,1
Domyślna lokalizacja : en
July 12, 2003
1,234,567.1
Klasy lokalizacyjnie-czułe pozwalają również na uzyskiwanie ich obiektów
przetwarzających informacje w sposób wymagany przez konkretną (nie domyślną)
lokalizację:
get...Instance(...)
z argumentem
typu Locale - określającym konkretną lokalizację.
Np. poniższy program wyprowadz datę w lokalizacji domyślnej, a liczbę - najpierw
w domyślnej, a później zgodnej z językiem angielskim.
import java.text.*;
import java.util.*;
public class MiscLok {
public static void main(String[] args) {
System.out.println("Domyślna lokalizacja : " + Locale.getDefault());
DateFormat df = DateFormat.getDateInstance(DateFormat.LONG);
System.out.println(df.format(new Date()));
double num = 123.4;
NumberFormat nf = NumberFormat.getInstance();
System.out.println("Liczba " + num +
" w lokalizacji domyślnej: " + nf.format(num));
nf = NumberFormat.getInstance(new Locale("en"));
System.out.println("Liczba " + num +
" w lokalizacji angielskiej: " + nf.format(num));
}
}
Domyślna lokalizacja : pl_PL
12 lipiec 2003
Liczba 123.4 w lokalizacji domyślnej: 123,4
Liczba 123.4 w lokalizacji angielskiej: 123.4
Uwaga: w/w getInstance() nie dotyczą formtora i skanera.
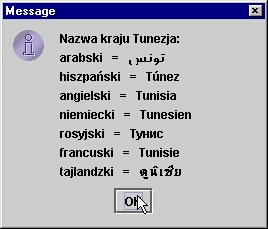
Poniższy przykładowy program pokazuje wykorzystanie prostej klasy Locale w celu tłumaczenia nazw krajów na różne języki.
import java.util.*;
import java.text.*;
import javax.swing.*;
class CountryTranslator {
public static void main(String[] args) {
Locale[] loc = Locale.getAvailableLocales();
Map map = new HashMap();
String kraj;
// Dodanie dostępnych lokalizacji do mapy
// klucz: nazwa kraju po polsku, wartośc - lokealizacja
for (int i=0; i<loc.length; i++) {
String countryCode = loc[i].getCountry(); // kod kraju
if (countryCode.equals("")) continue;
kraj = loc[i].getDisplayCountry();
map.put(kraj, loc[i]);
}
String msg = "Podaj kraj";
String in = "";
while((kraj = JOptionPane.showInputDialog(msg)) != null ) {
// Pobieramy lokalizację dla podanego kraju
Locale savedLoc = (Locale) map.get(kraj);
if (savedLoc == null) continue;
msg = "Podaj kody języków, rozdzielone spacjami";
while((in = JOptionPane.showInputDialog(null, msg, in)) != null ) {
StringTokenizer st = new StringTokenizer(in);
if (st.countTokens() == 0) continue;
String rep = "Nazwa kraju " + kraj + ":\n";
// Dla kolejnych kodów języków
// uzyskujemy nazwę kraju w języku odpowiadającym
// lokalizacji związanej z kodem jęsyka
while(st.hasMoreTokens()) {
Locale lang = new Locale(st.nextToken());
rep += lang.getDisplayLanguage() + " = " +
savedLoc.getDisplayCountry(lang) + "\n";
}
JOptionPane.showMessageDialog(null,rep);
}
msg = "Podaj kraj";
}
System.exit(0);
}
}
Formatowanie liczb
NumberFormat.
Ale wygodniejszy i bardziej uniwersalny sposób formatowania liczb polega na specyfikowaniu
wzorców formatu.
Mogą one być stosowane wobec formatorów, które są obiektami
klasy DecimalFormat.
Możemy postąpić tak:
- stworzyć obiekt klasy DecimalFormat, podając jako argument konstruktora wzorzec formatowania,
- wywołać metodę format na rzecz tego obiektu.
Na przykład:
double d = 10/3.0;
DecimalFormat dform = new DecimalFormat("###.###");
String wynik = dform.format(d);
System.out.println(wynik);
Wynik: 3,333.
Wzorce formatowania są łańcuchami znakowymi i mają następującą postać:
[prefiks][częśc_całkowita][.część_dziesiętna][sufiks]
gdzie:
- prefiks i sufiks - dowolny ciąg znaków oprócz znaków specjalnych,
- część całkowita i część dziesiętna - zero lub więcej znaków specjalnych
'#' albo zero lub więcej znaków specjalnych '0' oraz ew. pojedyncze inne
znaki specjalne.
Uwagi:
- nawiasy kwadratowe oznaczają opcjonalność elememetu wzorca, z tym, że co najmniej jeden z elementów musi wystąpić;
- jako wzorzec formatujący można podac dwa wzorce w powyższej postaci,
rozdzielone średnikiem; pierwszy z nich będzie dotyczył liczb dodatnich,
drugi - ujemnych.
Najważniejsze znaki specjalne używane we wzorcach formatujących podaje tabela.
| Symbol | Opis |
|---|
| 0 | cyfra, jeśli jest nieznaczącym zerem pokazywana jako 0 |
| # | cyfra, nieznaczące zera nie są pokazywane |
| . | miejsce separatora dziesiętnego |
| , | miejsce separatora grup cyfr (np. tysięcy) |
| E | miejsce separatora dla notacji inżynieryjnej lub naukowej ( np. 1E-11) |
| ; | separator formatu dla liczb dodatnich i formatu dla liczb ujemnych
&
lt;
/td> |
| - | znak minus |
| % | powoduje mnożenie liczby przez 100 i pokazanie jej w postaci procentowej
|
| ¤ | symbol waluty (np. zł); użyty dwukrotnie daje międzynarodowy symbol waluty |
| ' | ujęte w apostrofy znaki specjalne mogą być pokazywane w części prefiks lub sufiks
|
Program na wydruku pokazuje jak można korzystać z różnych formatów.
import java.text.*;
import java.math.*;
public class Format1 {
public static void show(double n1, Double n2, BigDecimal n3,
String format) {
DecimalFormat df = new DecimalFormat(format);
System.out.println("Format " + format);
System.out.println("Liczba: " + n1 + " wygląda tak: " + df.format(n1));
System.out.println("Liczba: " + n2 + " wygląda tak: " + df.format(n2));
System.out.println("Liczba: " + n3 + " wygląda tak: " + df.format(n3));
}
public static void main(String[] args) {
double num1 = 1.346;
Double num2 = new Double(0.765474);
BigDecimal num3 = new BigDecimal("100.2189091");
show(num1, num2, num3, "#.##");
show(num1, num2, num3, "#.## %");
show(num1, num2, num3, "#.0000");
show(num1, num2, num3, "#.00 ¤");
show(num1, num2, num3, "#.00 ¤¤");
show(num1, num2, num3, "[ 000.0 ]");
}
}
Wyniki jego dzialania pokazuje wydruk.
Format #.##
Liczba: 1.346 wygląda tak: 1,35
Liczba: 0.765474 wygląda tak: 0,77
Liczba: 100.2189091 wygląda tak: 100,22
Format #.## %
Liczba: 1.346 wygląda tak: 134,6 %
Liczba: 0.765474 wygląda tak: 76,55 %
Liczba: 100.2189091 wygląda tak: 10021,89 %
Format #.0000
Liczba: 1.346 wygląda tak: 1,3460
Liczba: 0.765474 wygląda tak: ,7655
Liczba: 100.2189091 wygląda tak: 100,2189
Format #.00 ¤
Liczba: 1.346 wygląda tak: 1,35 zł
Liczba: 0.765474 wygląda tak: ,77 zł
Liczba: 100.2189091 wygląda tak: 100,22 zł
Format #.00 ¤¤
Liczba: 1.346 wygląda tak: 1,35 PLN
Liczba: 0.765474 wygląda tak: ,77 PLN
Liczba: 100.2189091 wygląda tak: 100,22 PLN
Format [ 000.0 ]
Liczba: 1.346 wygląda tak: [ 001,3 ]
Liczba: 0.765474 wygląda tak: [ 000,8 ]
Liczba: 100.2189091 wygląda tak: [ 100,2 ]
Za pomocą metody format(...) można formatowac nie
tylko liczby typu double, ale również typu long oraz obiekty klas pochodnych
od Number (np. Double, Float, Long, Integer) i BigInteger oraz BigDecimal.
Klasy formatujące liczby
są przygotowane na prezentację liczb według reguł lokalizacyjnych. Jeśli
w metodzie getInstance() nie podamy lokalizacji - będzie użyta lokalizacja domyślna (np. polska z przecinkiem).
Jak uzyskać kropkę zamiast przecinka?
DecimalFormat df = (DecimalFormat)
NumberFormat.getInstance(new Locale("en", "US"));
df.applyPattern(format);
Problem z walutą (będzie USD).
Można: setCurrency(...).
Albo nie zmieniać lokalizacji, a zmienić symbole formatora decymalnego:
Zmiana separatora miejsc dziesiętnych na kropkę może wyglądać tak:
DecimalFormat df = new DecimalFormat(format); // formator w domyślnej lokalizacji
DecimalFormatSymbols sym = df.getDecimalFormatSymbols(); // symbole
sym.setDecimalSeparator('.'); // ustalenie separatora miejsc dziesiętnych
Inne symbole używane przy formatowaniu i metody ich zmian opisane są w dokumentacji.
Specjalne formatory do formatowania:
- liczb całkowitych - metoda NumberFormat.getIntegerInstance(...)
- wartości wyrażonych w walucie - metoda NumberFormat.getCurrencyInstance(...)
- wartości w procentach - metoda NumberFormat.getPercentInstance(...)
Prostsza drogą uzyskiwania efektów podobnych
do użycia wzorców formatowania w szczególnych przypadkach.
Formatory potrafią także dokonywać przekształceń odwrotnych: zamieniać napisy
reprezentujące liczby na postać binarną tych liczb.
Np. tekst, w którym liczby podawane są z przecinkami jako separatorami miejsc
dziesiętnych, Metoda parseDouble z klasy Double nie da oczekiwanych wyników (wyjątek).
Należy zastosować metodę parse(..) zdefiniowaną w klasach formatorów
i metoda ta poradzi sobie z dowolnymi sposobami zapisu liczb wedle różnych
reguł lokalizacyjnych (a także wedle różnych formatów).
Metoda parse(String) użyta na rzecz formatora.
- zwraca referencję do obiektu podklasy klasy Number,
który - w zależności od wartości interpretowanego napisu może wskazywać na
Long lub Double,
- napis podlega interpretacji jako liczba zgodnie z lokalizacją (np.
w polskiej lokalizacji użycie przecinka jako separatora miejsc dziesiętnych),
- w zależności od zastosowanego formatu w trakcie interpretacji napisu
może wystąpić wyjątek ParseException (albo interpretacja będzie przebiegać
"dopóki się da", a nie pasujące znaki będą pominięte).
W tych przypadkach, gdy błąd może pojawić się nie tylko na samym początku
napisu, użyteczna może okazać się metoda getErrorOffset() z klasy ParseException,
która zwraca pozycję w napisie, na której pojawił się błąd.
Zobaczmy na przykładzie zmodyfikowanego programu:
public static void main(String[] args) {
NumberFormat format = new DecimalFormat("[ #.0000 ]");
//...
while ((in = JOptionPane.showInputDialog(msg)) != null) {
System.out.println("Wejscie: " + in);
try {
num = format.parse(in);
} catch (ParseException exc) {
System.out.println("Wadliwe dane: " + in);
System.out.println(exc);
System.out.println("Wadliwa pozycja: " + exc.getErrorOffset());
continue;
}
System.out.println("Parse daje: " +
num.getClass().getName()+ " = " + num);
}
}
Przykładowy wydruk zmodyfikowanego programu :
Wejscie: [23]
Wadliwe dane [23]
java.text.ParseException: Unparseable number: "[23]"
Wadliwa pozycja: 0
Wejscie: [ 23 ]
Parse daje: java.lang.Long = 23
Wejscie: [ 23
Wadliwe dane: [ 23
java.text.ParseException: Unparseable number: "[ 23 "
Wadliwa pozycja: 4
Wejscie: [ 23 a ]
Wadliwe dane: [ 23 a ]
java.text.ParseException: Unparseable number: "[ 23 a ]"
Wadliwa pozycja: 4
Wejscie: [ 23.000 ]
Wadliwe dane: [ 23.000 ]
java.text.ParseException: Unparseable number: "[ 23.000 ]"
Wadliwa pozycja: 4
Wejscie: [ 23, 00 ]
Wadliwe dane: [ 23, 00 ]
java.text.ParseException: Unparseable number: "[ 23, 00 ]"
Wadliwa pozycja: 5
Wejscie: [ 23,0 ]
Parse daje: java.lang.Long = 23
Inną formą metody parse z klas formatorów jest:
Number num = parse(String dane, ParsePosition pos);
Tutaj używamy obiektu pos klasy ParsePosition, który określa bieżącą pozycję rozbioru napisu dane oraz ew. pozycję (indeks) na której wystąpił błąd.
Rozbiór danych (wedle formatu) rozpoczyna się od pozycji okreslonej przez
podany obiekt klasy ParsePosition. Napis podlega interpretacji (dopóki kolejne
jego znaki można traktować jako znaki liczby wg danego formatu), po czym
bieżąca pozycja rozbioru (indeks) jest ustawiana za ostatnim zinterpretowanym
znakiem i zwracana jest liczba jako obiekt klasy Number.
Ta metoda nie zgłasza żadnych wyjątków. W przypadku błędu interpretacji (a
w zależności od formatu - występuje on albo tylko na początku napisu, albo
gdzieś dalej) zwracana jest wartość null, bieżąca pozycja nie ulega zmianie,
a indeks błędu ustawiany jest na znaku, który spowodowłą bład. Jeżeli nie
ma błędu indeks błędu ma wartość -1.
Pozycje (indeks) - bieżący i błędu - możemy uzyskiwac od obiektu ParsePosition
za pomocą metod getIndex() i getErrorIndex() oraz ustawiać za pomocą odpowiednich
metod setIndex(...) i setErrorIndex(...).
Program na wydruku pokazuje przykładowe użycie tej metody parse do wyodrębnienia
z pliku tekstowego wszystkich informacji zapisanych w formacie walutowym
(możemy sobie wyobrażać, że jest to plik opisujący jakieś wydatki, a naszym
zadaniem jest ich podsumowanie)
.import java.io.*;
import java.text.*;
import java.util.*;
public class Parse2 {
public static void main(String[] args) {
// Format walutowy w domyślnej lokalizacji
// czyli w PL np. 12 zł
NumberFormat format = NumberFormat.getCurrencyInstance();
// Lista wartości wydatków (zapisanych w tekście pliku)
List numList = new ArrayList();
try {
BufferedReader br = new BufferedReader(
new FileReader("testdata.txt")
);
// czytanie kolejnych wierszu
String in;
while ((in = br.readLine()) != null) {
int p = 0; // bieżący indeks rozbioru
int last = in.length() - 1; // ostatni indeks w wierszu
// Utworzenie pozycji rozbioru wiersza (od 0)
ParsePosition ppos = new ParsePosition(0);
// Dopóki nie dobiegliśmy do końca wiersza
while (p <= last) {
// Próbujemy pobrać kolejną liczbę w formacie walutowym
Number num = format.parse(in, ppos);
if (num == null) // jeżeli błąd,
p = ppos.getErrorIndex()+1; // indeks na znaku po błędzie
else { // jeżeli udało się sczytać wartość
numList.add(num); // dodajemy ją do listy
p = ppos.getIndex(); // indeks na następnym znaku po
}
ppos.setIndex(p); // ustawiamy następną pozycję
} // od której kontynuacja rozbioru
}
br.close();
} catch(Exception exc) {
exc.printStackTrace();
System.exit(1);
}
// Wypisanie i podsumowanie zapisanych w pliku wydatków
System.out.println("Wydatki w zł:");
double suma = 0;
for (Iterator iter = numList.iterator(); iter.hasNext(); ) {
Number val = (Number) iter.next();
System.out.println(val);
suma += val.doubleValue();
}
System.out.println("Wydano w sumie: " + format.format(suma));
}
}
Gdy użyjemy tego programu wobec pliku, zawierającego następujący tekst:
Wydano najpierw 123 zł na 23 kilo jabłek
Kolejny wydatek objął 77,77 zł (70 litrów maślanki)
a potem jeszcze doszło 999,99 zł w 4 ratach.
to w wyniku uzyskamy:
Wydatki w zł:
123
77.77
999.99
Wydano w sumie: 1 200,76 zł
Przy okazji: spójrzmy na nowe środki Javy 1.5
import java.io.*;
import java.text.*;
import java.util.*;
public class Parse2j5 {
public static void main(String[] args) {
// Format walutowy w domyślnej lokalizacji
// czyli w PL np. 12 zł
NumberFormat format = NumberFormat.getCurrencyInstance();
// Lista wartości wydatków (zapisanych w tekście pliku)
// GENERIC!!!
List<Double> numList = new ArrayList<Double>();
try {
BufferedReader br = new BufferedReader(
new FileReader("testdata.txt")
);
// czytanie kolejnych wierszu
String in;
while ((in = br.readLine()) != null) {
int p = 0; // bieżący indeks rozbioru
int last = in.length() - 1; // ostatni indeks w wierszu
// Utworzenie pozycji rozbioru wiersza (od 0)
ParsePosition ppos = new ParsePosition(0);
// Dopóki nie dobiegliśmy do końca wiersza
while (p <= last) {
// Próbujemy pobrać kolejną liczbę w formacie walutowym
Number num = format.parse(in, ppos);
if (num == null) // jeżeli błąd,
p = ppos.getErrorIndex()+1; // indeks na znaku po błędzie
else { // jeżeli udało się sczytać wartość
numList.add(num.doubleValue()); // BOXING!!!
p = ppos.getIndex(); // indeks na następnym znaku po
}
ppos.setIndex(p); // ustawiamy następną pozycję
} // od której kontynuacja rozbioru
}
br.close();
} catch(Exception exc) {
exc.printStackTrace();
System.exit(1);
}
// Wypisanie i podsumowanie zapisanych w pliku wydatków
System.out.println("Wydatki w zł:");
double suma = 0;
for( Double val : numList ) { // FOR-EACH
System.out.println(val);
suma += val; // UNBOXING!!!
}
/*for (Iterator iter = numList.iterator(); iter.hasNext(); ) {
Number val = (Number) iter.next();
System.out.println(val);
suma += val.doubleValue();
}*/
System.out.println("Wydano w sumie: " + format.format(suma));
}
}
Kontrola wyjścia - sposobu formatowania: klasa FieldPosition.
Istnieją też inne sposoby formatowania liczb.
Wśród podklas klasy NumberFormat znajdziemy klasę ChoiceFormat.
Generalnie pozwala ona kojarzyć dowolne napisy z (półotwartymi z prawej
strony) przedziałami liczb. Formatowanie za jej pomocą polega na zastąpieniu
liczby, "trafiającej" w dany przedział, skojarzonym z tym przedziałem napisem.
Klasa ChoiceFormat jest szczególnie użyteczna przy internacjonalizacji napisów
w programie z wykorzystaniem klasy MessageFormat.
Uwaga: aby korzystać z klas pakietów ICU należy udostępnić archiwum
JAR z tymi pakietami. Możemy to uczynić na kilka sposobów:
- umieścić archiwum w katalogu javax katalogu instalacyjnego Javy (wtedy
biblioteka ICU stanie się standardowym rozszerzeniem - inaczej zwanym pakietem
opcjonalnym - i nasze programy będą miały do niej dostęp,
- umieścić nazwę archiwum JAR biblioteki ICU na ścieżce classpath,
- kompilować i uruchamiać programy z opcją -classpath, podając archiwum
JAR biblioteki ICU wraz z innymi elmentami ścieżki (%classpath%); przy uruchamianiu
klas z pakietu domyślnego nie należy zapomnieć o podaniu jako elementu ścieżki
bieżącego katalogu, oznaczanego kropką,
Pozwala ona na formatowanie liczb za pomocą definiowania zestawów reguł.
Przykładowe zdefiniowane już reguły dla formatora RuleBasedNumber to:
- SPELLOUT - przedstawianie liczb w postaci słownej,
- ORDINAL - przedstawianie liczb jako liczebników porządkowych (z odpowiednimi końcówkami),
- DURATION - przekształcanie liczb na jednostki czasu (godziny, minuty, sekundy).
Waluty
Klasa Currency z pakietu java.util opisuje waluty. Obiekty tego typu są wykorzystywane
przez klasę DecimalFormat i możemy je np. stosować dla zmiany formatów walutowych
(metoda setCurrency(Currency) z klasy DecimalFormat).
Klasa Currency może być użyteczna w różnych sytuacjach.
Wyobraźmy sobie taki scenariusz: mamy stworzyć aplikację, która generuje
raporty o aktualnych kursach wybranych walut w kilku językach. Aktualne kursy
pobieramy z jakiegoś serwisu WEB na podstawie podanych międzynarodowych symboli
walut.
Aby taki program można było napisać, trzeba wiedzieć jakie są symbole
walut i umieć tłumaczyć symbole walut na wybrane języki.
Pakiet ICU dostarcza dodatkowych możliwości, gdy chodzi o waluty. M.in. możemy
uzyskać bardziej opisową, stosowaną w podanej lokalizacji nazwę waluty. Pokazuje
to poniższy program.
Strefy czasowe
Strefy czasowe są przedstawiane przez obiekty klasy TimeZone z pakietu java.util.
Aby uzyskać aktualną, domyślną dla komputera na którym działa nasz program,
strefę czasową stosujemy statyczną metodę getDefault() z klasy TimeZone.
W naszym programie możemy skonstruować dowolną strefę czasową, używając metody
TimeZone.getTimeZone(String ID) i podając jako argument identyfikator strefy
czasowej.
Listę dostępnych identyfikatorów można uzyskać jako tablicę Stringów za pomoca odwołania TimeZone.getAvailableIDs().
Poniższy przykładowy programik pokazuje jak można wyliczyć aktualną różnicę
czasu pomiędzy podanymi strefami czasowymi oraz jak można dowiedzieć się
jakie strefy czasowe mają podaną różnicę czasu wobec GMT.
import java.util.*;
import java.awt.*;
import java.awt.event.*;
import javax.swing.*;
public class Strefy1 {
public static void main(String[] args) {
// Konstruowanie stref czasowych
TimeZone myTz = TimeZone.getTimeZone("Europe/Warsaw");
TimeZone java = TimeZone.getTimeZone("Asia/Jakarta");
TimeZone cuba = TimeZone.getTimeZone("America/Havana");
// za pomocą pokazanej dalej metody getDiffMsg
// wyliczamy i pokazujemy aktualną różnicę czasu
// pomiędzy sterfami czasowymi
System.out.println(getDiffMsg(myTz, java));
System.out.println("--------------------------------------------------");
System.out.println(getDiffMsg(myTz, cuba));
System.out.println("--------------------------------------------------");
System.out.println(getDiffMsg(cuba, java));
System.out.println("--------------------------------------------------");
// Jakie strefy czasowe mają podaną różnicę czasu wobec GMT
for (int k = 12; k <= 14; k++) {
String[] ids = TimeZone.getAvailableIDs(k*3600000);
Arrays.sort(ids);
System.out.println(
"Strefy czasowe mające różnice +" + k + " godzin wobec GMT" );
for (int i=0; i < ids.length; i++) {
System.out.println(ids[i]);
}
System.out.println("--------------------------------------------------");
}
}
static String getDiffMsg(TimeZone z1, TimeZone z2) {
Date data = new Date();
long teraz = data.getTime();
double offset1 = z1.getOffset(teraz)/3600000.0;
double offset2 = z2.getOffset(teraz)/3600000.0;
double diff;
if (offset1 > offset2) diff = -(offset1 - offset2);
else diff = offset2 - offset1;
String out = "Różnica czasu pomiędzy" + '\n' +
z1.getID() + " i " + z2.getID() + '\n' +
"wynosi teraz : " + diff + " godz." + '\n' +
"W strefie " + z1.getID() +
(z1.inDaylightTime(data) ? " " : " nie ") +
"działa czas letni" + '\n' +
"W strefie " + z2.getID() +
(z2.inDaylightTime(data) ? " " : " nie ") +
"działa czas letni";
return out;
}
}
Wydruk:
Różnica czasu pomiędzy
Europe/Warsaw i Asia/Jakarta
wynosi teraz : 5.0 godz.
W strefie Europe/Warsaw działa czas letni
W strefie Asia/Jakarta nie działa czas letni
--------------------------------------------------
Różnica czasu pomiędzy
Europe/Warsaw i America/Havana
wynosi teraz : -6.0 godz.
W strefie Europe/Warsaw działa czas letni
W strefie America/Havana działa czas letni
--------------------------------------------------
Różnica czasu pomiędzy
America/Havana i Asia/Jakarta
wynosi teraz : 11.0 godz.
W strefie America/Havana działa czas letni
W strefie Asia/Jakarta nie działa czas letni
--------------------------------------------------
Strefy czasowe mające różnice +12 godzin wobec GMT
Antarctica/McMurdo
Antarctica/South_Pole
Asia/Anadyr
Asia/Kamchatka
Etc/GMT-12
Kwajalein
NST
NZ
Pacific/Auckland
Pacific/Fiji
Pacific/Funafuti
Pacific/Kwajalein
Pacific/Majuro
Pacific/Nauru
Pacific/Tarawa
Pacific/Wake
Pacific/Wallis
--------------------------------------------------
Strefy czasowe mające różnice +13 godzin wobec GMT
Etc/GMT-13
Pacific/Enderbury
Pacific/Tongatapu
--------------------------------------------------
Strefy czasowe mające różnice +14 godzin wobec GMT
Etc/GMT-14
Pacific/Kiritimati
--------------------------------------------------
Kalendarze
Informacje o datach i czasie są w Javie reprezentowane przez obiekty klasy Calendar.
Informacje o bieżącej dacie i czasie możemy uzyskać m.in. za pomocą odwołania:
Calendar c = Calendar.getInstance();
które zwraca obiekt - domyślny kalendarz dla domyślnej lokalizacji
ustawiony na bieżącą datę i czas w strefie czasowej właściwej dla domyślnej
lokalizacji.
Informacje o dacie i czasie są zapisane w polach obiektu-kalendarza. Dostęp do tych pól uzyskujemy za pomocą metody get(...)
, użytej na rzecz obiektu-kalendarza, z argumentem - stałą statyczną klasy
Calendar, okreslającą o jaki rodzaj informacji nam chodzi. Oprócz tego pewne
informacje, związane z właściwościami danego kalendarza lub dla danej lokalizacji
można uzyskać za pomocą innych metod get... (np. jaki jest pierwszy dzień
tygodnia - niedziela czy poniedziałek - getFirstDayOfWeek()).
Przykładowy program spełnia funkcję przewodnika po polach kalendarza, pokazują
ich znaczenie oraz sposoby uzyskiwania ich wartości.
import java.util.*;
public class Kal1 {
public static void say(String s) { System.out.println(s+'\n'); }
public static void main(String[] args) {
// uzyskanie kalendarza domyślnego
// (obowiązującgo dla domyślnej lokalizacji - tu dla Polski)
// ustawionego na bieżącą datę i czas
Calendar cal = Calendar.getInstance();
say("ERA.............. " + cal.get(Calendar.ERA) +
" (tu: 0=pne, 1=AD)");
say("ROK.............. " + cal.get(Calendar.YEAR));
say("MIESIĄC.......... " + cal.get(Calendar.MONTH) +
" (0-styczeń, 2-luty, ..., 11-grudzień)");
say("LICZBA DNI\n" +
"W MIESIĄCU....... " + cal.getActualMaximum(Calendar.DAY_OF_MONTH));
say("DZIEŃ MIESIĄCA... " + cal.get(Calendar.DAY_OF_MONTH));
say("DZIEŃ MIESIĄCA... " + cal.get(Calendar.DATE));
say("TYDZIEŃ ROKU..... " + cal.get(Calendar.WEEK_OF_YEAR));
say("TYDZIEŃ MIESIĄCA. " + cal.get(Calendar.WEEK_OF_MONTH));
say("DZIEŃ W ROKU..... " + cal.get(Calendar.DAY_OF_YEAR));
say("PIERWSZY DZIEŃ\n" +
"TYGODNIA......... " + cal.getFirstDayOfWeek() +
" (1-niedziela, 2-poniedziałek, ..., 7 sobota)");
say("DZIEŃ TYGODNIA... " + cal.get(Calendar.DAY_OF_WEEK) +
" (1-niedziela, 2-poniedziałek, ..., 7-sobota)");
say("GODZINA.......... " + cal.get(Calendar.HOUR) +
" (12 godzinna skala; następne odwolanie czy AM czy PM)");
say("AM/PM............ " + cal.get(Calendar.AM_PM) +
" (AM=0, PM=1)");
say("GODZINA.......... " + cal.get(Calendar.HOUR_OF_DAY) +
" (24 godzinna skala)");
say("MINUTA........... " + cal.get(Calendar.MINUTE));
say("SEKUNDA......... " + cal.get(Calendar.SECOND));
say("MILISEKUNDA: " + cal.get(Calendar.MILLISECOND));
int msh = 3600*1000; // liczba milisekund w godzinie
say("RÓŻNICA CZASU\n" +
"WOBEC GMT........ " + cal.get(Calendar.ZONE_OFFSET)/msh);
say("PRZESUNIĘCIE\n" +
"CZASU............ " + cal.get(Calendar.DST_OFFSET)/msh +
" (w Polsce obowiązuje w lecie)");
}
}
Na wydruku pokazano wyniki działania programu, uruchomionego we wtorek 6 maja 2003 roku o godzinie 18:05:00.
Wydruk:
ERA.............. 1 (tu: 0=pne, 1=AD)
ROK.............. 2003
MIESIĄC.......... 4 (0-styczeń, 2-luty, ..., 11-grudzień)
LICZBA DNI
W MIESIĄCU....... 31
DZIEŃ MIESIĄCA... 6
DZIEŃ MIESIĄCA... 6
TYDZIEŃ ROKU..... 19
TYDZIEŃ MIESIĄCA. 2
DZIEŃ W ROKU..... 126
PIERWSZY DZIEŃ
TYGODNIA......... 2 (1-niedziela, 2-poniedziałek, ..., 7 sobota)
DZIEŃ TYGODNIA... 3 (1-niedziela, 2-poniedziałek, ..., 7-sobota)
GODZINA.......... 6 (12 godzinna skala; następne odwolanie czy AM czy PM)
AM/PM............ 1 (AM=0, PM=1)
GODZINA.......... 18 (24 godzinna skala)
MINUTA........... 5
SEKUNDA......... 0
MILISEKUNDA: 550
RÓŻNICA CZASU
WOBEC GMT........ 1
PRZESUNIĘCIE
CZASU............ 1 (w Polsce obowiązuje w lecie)
Uwaga: należy zwrócić baczną uwagę na to, że indeksowanie miesięcy rozpoczyna
się od 0, a nie od 1 (czyli styczeń ma numer 0). Jest to fatalny błąd, który
popełniono w pierwszej wersji Javy, wprowadzając klasę Date.
Za pomocą metod set... kalendarza możemy ustawiać jego bieżącą datę i czas.
Np. aby ustawić kalendarz na 7 maja 2003 roku na tę samą godzinę co "teraz" możemy napisać:
Calendar c = Calendar.getInstance();
c.set(2003, 4, 7); // rok 2003, indeks miesiąca = 4 (maj), dzień 7
a jeśli chcemy zarazem ustalić godzinę 18 minut 05 napiszemy:
c.set(2003, 4, 7, 18, 5);
Możemy też zmieniać (ustawiać) wartości poszczególnych pól.
Służą do tego metody, które wykonują operacje na datach.
Operacje na datach wykonujemy za pomocą następujących metod:
set(id_pola, wartość)
add(id_pola, wartość)
roll(id_pola, wartość)
gdzie:
id_pola - stała statyczna z klasy
Calendar, określająca pole na którym wykonywana jest oparacja,
wartość - nowa wartość pola.
Wszystkie w/w operacje uwzględniają reguły danego kalendarza, a różnica pomiędzy nimi jest następująca:
- set - ustala wartość pola; jeśli trzeba dostosowując inne pola (np.
ustawienie pola DAY_OF_MONTH na wartość 31 dla kalendarza ustawionego na
dowolną datę w czerwcu spowoduje, że kalendarz będzie wskazywał na 1 lipca,
gdyż w czerwcu jest tylko 30 dni),
- add - dodaje do pola podaną wartość, stosując przy tym arytmetykę
kalendarzową (np. dodanie do 30 maja 2 dni spowoduje ustawienie kalendarza
na 1 czerwca),
- roll - również wykonuje dodawanie, ale przy tym nie zmienia wartości
"starszych" pól np. jeżeli dodajemy dni i okaże się, że nowa data znajdzie
się w innym niż teraz miesiącu, to miesiąc nie zostanie zmieniony, zaś "nadwyżka"
dni (poza końcem bieżącego miesiąca) będzie dodawana od początku miesiąca.
Dokładne reguły obliczeniowe są podane w dokumentacji klasy Calendar.
Możemy uzyskać inne kalendarze (niż domyślny):
- dla domyślnej lokalizacji, ale ustawiony na podaną strefę czasową (Calendar.getInstance(TimeZone)),
- dla podanej lokalizacji (Calendar.getInstance(Locale)),
- dla podanej lokalizacji i strefy czasowej (Calendar.getInstance(TimeZone,Locale)),
Oto prosty przykłady.
W poniższym fragmencie kodu:
TimeZone tz = TimeZone.getTimeZone("Asia/Jakarta");
Calendar c = Calendar.getInstance(tz);
System.out.println("Current time: " + c.getTime());
System.out.println("Java time: " +
c.get(Calendar.HOUR_OF_DAY) + ":" + c.get(Calendar.MINUTE));
kalendarz ustawiany jest na strefę czasową Javy (wyspy, nie języka). Metoda
getTime() zwróći aktualny czas w domyślnej lokalizacji, ale pola kalendarza
są ustawiane z uwzględnieniem różnicy czasu.
W wyniku otrzymamy.
Current time: Fri Jul 18 12:44:47 CEST 2003
Java time: 17:44
Czym różnią się kalendarze dla różnych lokalizacji?
Następujący fragment kodu:
Calendar c = Calendar.getInstance();
System.out.println(c.getClass().getName());
c = Calendar.getInstance(new Locale("th", "TH"));
System.out.println(c.getClass().getName());
wyprowadzi:
java.util.GregorianCalendar
sun.util.BuddhistCalendar
Dużo więcej kalendarzy znajdziemy w pakiecie ICU.
Mamy tam kalendarze: buddyjski, tradycyjny chiński, tradycyjny japoński, islamski, hebrajski.
Sposób użycia tych kalendarzy oraz tóżnice pomiędzy nimi pokazuje poniższy program.
import com.ibm.icu.util.*;
import com.ibm.icu.text.*;
public class MiscCal {
public static void main(String[] args) {
Calendar[] kal = {
Calendar.getInstance(), // domyślny kalendarz - gregoriański
new GregorianCalendar(), // jeszcze raz - ale inaczej tworzony
new BuddhistCalendar(), // buddyjski
new ChineseCalendar(), // chiński
new JapaneseCalendar(), // japoński
new IslamicCalendar(), // islamski
new HebrewCalendar(), // hebrajski
};
java.util.Date teraz = new java.util.Date(); // aktualny czas
System.out.println("Teraz jest: " + teraz); // po angielsku
// przebiegamy po klaendarzach
// ustawiamy je na bieżący czas
// i pokazujemy wartości takich pól jak rok, miesiąc itp.
for (int i=0; i<kal.length; i++) {
kal[i].setTime(teraz);
String className = kal[i].getClass().getName();
String name = className.substring(className.lastIndexOf(".") + 1);
System.out.println(name + " - " +
"era " + kal[i].get(Calendar.ERA) +
"; rok " + kal[i].get(Calendar.YEAR) +
(name.equals("ChineseCalendar") ?
" czyli " + kal[i].get(Calendar.EXTENDED_YEAR) : "") +
"; mies " + kal[i].get(Calendar.MONTH) +
"; dzień mies. " + kal[i].get(Calendar.DAY_OF_MONTH) +
"; dzień tyg. " + kal[i].get(Calendar.DAY_OF_WEEK)
);
}
}
}
Program wyprowadzi następujące wyniki.
Teraz jest: Fri Jul 18 15:02:24 CEST 2003
GregorianCalendar - era 1; rok 2003; mies 6; dzień mies. 18; dzień tyg. 6
GregorianCalendar - era 1; rok 2003; mies 6; dzień mies. 18; dzień tyg. 6
BuddhistCalendar - era 0; rok 2546; mies 6; dzień mies. 18; dzień tyg. 6
ChineseCalendar - era 78; rok 20 czyli 4640; mies 5; dzień mies. 19; dzień tyg. 6
JapaneseCalendar - era 235; rok 15; mies 6; dzień mies. 18; dzień tyg. 6
IslamicCalendar - era 0; rok 1424; mies 4; dzień mies. 18; dzień tyg. 6
HebrewCalendar - era 0; rok 5763; mies 10; dzień mies. 18; dzień tyg. 6
Dostosowanie kalendarza do lokalizacji nie polega tylko na zmianie samego
kalendarza. Ten sam kalendarz - np. gregoriański - w różnych lokalizacjach
może się różnić np. pierwszym dniem tygodnia. W Polsce pierwszym dniem tygodnia
jest poniedziałek (indeks 2). Dla innych krajów - może być to inny dzień
tygodnia.
Formatowanie dat
Przy formatowaniu dat podobnie jak w przypadku liczb musimy najpierw uzyskać odpowiedni formator
za pomocą statycznych metod getXXXInstance(...) z klasy DateFormat, a następnie
na jego rzecz użyć metody format z argumentem typu Date.
Możemy zastosować:
- formator dla dat - metody getDateInstance(...)
- formator dla czasu - metody getTimeInstance(...)
- formator dla daty i czasu - metody getDateTimeInstance(...)
- domyślny formator dla daty i czasu - metoda getInstance().
Argumenty w/w metod określają lokalizację oraz styl formatowania .
Oprócz tego możemy posłużyć się wzorcami formatowania.
Metoda getXXXInstance() klasy DateFormat zwraca (zlokalizowany, jeśli można)
obiekt klasy SimpleDateFormat. Za pomocą tej klasy możemy zastosować wzorce
formatowania do pokazywania (i parsowania) dat i czasu.
Wzorzec formatowania składa się z liter ('a' - 'z', 'A' - 'Z')), które mają
specjalne znaczenie i są interpretowane jako składowe daty/czasu (lub zarezerwowane)
oraz innych symboli, które są po prostu kopiowane przy formatowaniu. Litery
ujęte w apostrofy nie są interpretowane.
Litery, mające specjalne znaczenie pokazuje tablica.
| Litera
| Znaczenie
| Typ
| Przykład
|
|---|
G | Era
| Tekst | AD |
y | Rok
| Rok | 1996; 96 |
M | Miesiąc w roku
| Miesiąc | July; Jul; 07 |
w | Tydzień w roku
| Liczba
| 27 |
W | Tydzień w miesiącu | Liczba | 2 |
D | Dzień roku
| Liczba | 189 |
d | Dzień miesiąca
| Liczba | 10 |
F | Dzień tygodnia
| Liczba | 2 |
E | Dzień tygodnia
| Tekst | Tuesday; Tue |
a | Tekst Am/pm
| Tekst | PM |
H | Godzina dnia (0-23)
| Liczba | 0 |
k | Godzina dnia (1-24)
| Liczba | 24 |
K | Godzina am/pm (0-11)
| Liczba | 0 |
h | Gdodzina am/pm (1-12) | Liczba |
| 12 |
m | Minuta
| Liczba | 30 |
s | Sekunda
| Liczba | 55 |
S | Milisekunda | Liczba | 978 |
z | Strefa czasowa
| Symbol strefy
| Pacific Standard Time; PST; GMT-08:00 |
Z | Strefa czasowa
| Symbol RFC 822 | -0800 |
Przyjrzyjmy
się kilku przykładom zastosowania wzorców formatowania dat.
Poniższy program:
import java.util.*;
public class Daty1 {
public static void main(String[] args) {
Calendar c = Calendar.getInstance();
Date teraz = c.getTime();
SimpleDateFormat df = (SimpleDateFormat) DateFormat.getDateInstance();
String[] pattern = {"dd-MM-yyyy",
"MMMM, 'dzień 'dd ( EE ), 'roku 'yyyy GGGG",
"EEEE, dd MMM yyyy 'r.'"
};
for (int i=0; i<pattern.length; i++) {
df.applyPattern(pattern[i]);
System.out.println(df.format(teraz));
}
}
}
wyprowadzi:
18-07-2003
lipiec, dzień 18 ( Pt ), roku 2003 n.e.
piątek, 18 lip 2003 r.
Przy parsowaniu z użyciem zdefiniowanych wzorców formatowania teksty (zapisane
zgodnie z tymi wzorcami) przekształcane są na daty (obiekty klasy Date).
Reguły parsowania są podobne jak w przypadku klasy NaumberFormat.
Poniższy przykładowy fragment:
public static void main(String[] args) {
SimpleDateFormat df = (SimpleDateFormat) DateFormat.getDateInstance();
String[] pattern = {"dd-MM-yyyy",
"MMMM, 'dzień 'dd ( EE ), 'roku 'yyyy GGGG",
"EEEE, dd MMM yyyy 'r.'"
};
for (int i=0; i<pattern.length; i++) {
String in=JOptionPane.
showInputDialog("Wprowadź datę wg wzorca " + pattern[i]);
df.applyPattern(pattern[i]);
Date data = df.parse(in, new ParsePosition(0));
System.out.println(data);
}
}
po wprowadzeniu w dialogach tekstów:
12-12-1999
lipiec, dzień 18 ( Pt ), roku 2003 n.e.
wtorek, 12 lipiec 2003 r.
wyprowadzi na konsolę:
Sun Dec 12 00:00:00 CET 1999
Fri Jul 18 00:00:00 CEST 2003
Sat Jul 12 00:00:00 CEST 2003
Zwróćmy uwagę: błędny dzień tygodnia (wtorek zamiast soboty) nie spowodował
błędu interpretacji, ale uzyskana data jest właściwa (nazwa dnia tygodnia
została skorygowana).
Oczywiście, formatowanie i parsowanie podlega zasadom lokalizacji.
Istotnych informacji lokalizacyjnych dostarcza klasa DateFormatSymbols.
Przykładowy program tworzy obiekty klasy DateFormatSymbols dla kilku lokalizacji
i wywołuje na ich rzecz metody takie jak getWeekdays() (zwracającą nazwę
dni tygodnia) czy getMonths() (nazwy dni miesiąca). Nazwy metod pozyskujących
zlokalizowane informacje są samoobjaśniające sie, wynik działania programu
pokazujemy w obszarze wielowierszowego pola edycyhnego (JTextArea) po to
by właściwie były interpretowane znaki Unicode (zob. rysunek).
import java.util.*;
import java.text.*;
import java.awt.*;
import javax.swing.*;
public class DateFormatSymbolsShow {
String[] lang = { "fr", "es", "de", "ru" };
String out = "";
public DateFormatSymbolsShow() {
for (int i=0; i<lang.length; i++) {
Locale loc = new Locale(lang[i]);
DateFormatSymbols dfs = new DateFormatSymbols(loc);
out += '\n' + loc.getDisplayLanguage();
// nazwy er
addToOut("Ery: ", dfs.getEras());
// nazwy miesięcy
addToOut("Miesiące: ", dfs.getMonths());
// skróty miesięcy
addToOut("Miesiące - skróty: ", dfs.getShortMonths());
// nazwy dni tygodnia
addToOut("Dni tygodnia: ", dfs.getWeekdays());
// skróty nazw dni tygodnia
addToOut("Dni tygodnia - skróty: ", dfs.getShortWeekdays());
}
JTextArea ta = new JTextArea(out);
ta.setFont(new Font("Dialog", Font.BOLD, 14));
JFrame f = new JFrame();
f.getContentPane().add(ta);
f.pack();
f.show();
}
void addToOut(String msg, String[] s) {
out += "\n" + msg;
for (int i=0; i<s.length; i++) {
out += ' ' + s[i];
}
}
public static void main(String[] args) {
new DateFormatSymbolsShow();
}
}

Zwykle nie korzystamy z klasy DateFormatSymbols (jest ona używana automatycznei
przy formatowaniu dat), Czasem jednak może zajść taka potrzeba. Wtedy można
użyc konstruktora klasy SimpleDateFormat, dostarczając mu oprócz pierwszego
argumentu (wzorca formatowania) argument drugi - refrencję do obiektu DateFormatSymbols.
Wykorzystamy to teraz do poprawieniu błędów gramatycznych, które nieuchronnie
powstają przy formatowaniu dat w języku polskim ze względu na brak uwzględnienia
właściwej odmiany nazw miesięcy.
Przy okazji zobaczymy, że właściwości lokalizacyjne formatowania dat można
łatwo zmieniać (za pomocą rozlicznych metod set... z klasy DateFormatSymbols).
import java.util.*;
import java.text.*;
public class DateFormatPol {
public static String polskaData(Date data) {
String[] mies = { "stycznia", "lutego", "marca", "kwietnia",
"maja", "czerwca", "lipca", "sierpnia",
"września", "października", "listopada",
"grudnia"
};
DateFormatSymbols dfs = new DateFormatSymbols();
dfs.setMonths(mies);
SimpleDateFormat df = new SimpleDateFormat("dd MMMM yyyy", dfs);
return df.format(data);
}
public static void main(String[] args) {
System.out.println( polskaData( new Date() ) );
}
}
Prrzykładowy listing programui:
20 lipca 2003
Zlokalizowany rozbiór tekstów
zob. w książce
Porównywanie i sortowanie napisów
Różne języki implikują różny alfabetyczny porządek napisów.
Właściwe porównywanie napisów możemy przeprowadzić za pomocą obiektu klasy Collator z pakietu java.text.
Jest to klasa czuła na lokalizację, zatem właściwą instancję kolatora dla
domyślnej lokalizacji uzyskamy za pomocą odwołania Collator.getInstance().
Możemy też uzyskać kolator dla dowolnej lokalizacji, podając w metodzie getInstance(...) argument-lokalizację
Mając obiekt-kolator dla okreslonej (domyślnej lub podanej) lokalizacji możemy
za pomocą metody compare(...) wywołanej na jego rzecz uzyskać własciwy dla
danej lokalizacji wynik porównania dwóch napisów podanych jako argumenty
metody.
Łatwo się domyślić, że klasa Collator implementuje interfejs Comparator.
Zatem porównania uzyskiwane za pomoca metody compare(...) kolatora łatwo
uczynić podstawą sortowania tablic i kolekcji, a także decydowania o dodawaniu
elementów do uporządkowanych zbiorów i map.
Zobaczmy najprostszy przykład. Niech domyślna lokalizacja będzie lokalizacją
polską, Jak posortować tablicę napisów w tej lokalizacji ? Reguła jest prosta:
- uzyskać kolator dla lokalizacji domyslnej (polskiej) - metoda Collator.getInstance(),
- podać ten kolator jako komparator w metodzie Arrays.sort(...)
import java.util.*;
import java.text.*;
public class Kolator0 {
static void sortShow(String msg, String[] txt, Collator col) {
String[] copyTxt = (String[]) txt.clone();
Arrays.sort(copyTxt, col);
System.out.println(msg);
for (int i=0; i < copyTxt.length; i++) {
System.out.println(copyTxt[i]);
}
}
public static void main(String[] args) {
String[] txt = { "bela", "Ala", "ą", "Ą", "ą", "ala" , "Be", "Ala",
"alabama", "be", "Be", "1", "ć", "my", "My", "Myk", "myk" };
Collator col = Collator.getInstance();
sortShow("Sort pol", txt, col);
Collator col1 = Collator.getInstance(new Locale("en"));
sortShow("Sort en", txt, col1);
}
}
Program wyprowadzi na konsolę:
Sort pol
1
ala
Ala
Ala
alabama
ą
ą
Ą
be
Be
Be
bela
ć
my
My
myk
Myk
Sort en
1
ą
ą
Ą
ala
Ala
Ala
alabama
be
Be
Be
bela
ć
my
My
myk
Myk
W jaki sposób (dla różnych lokalizacji) uzyskujemy właściwe porównania?
Otóż konkretne kolatory są obiektami klasy RuleBasedCollator, która jest podklasą klasy Collator.
Uporządkowanie za pomocą kolatorów klasy RuleBasedCollator odbywa się na
podstawie porównywanie znaków w oparciu o reguły zapisane za pomocą prostej
składni. Reguły te określają cztery (a w pakieice ICU nawet pięć) porządki:
- podstawowy (PRIMARY), w którym rozróżniane są (zdefiniowane w zestawie reguł jako rozróżnialne) znaki,
- drugorzędny (SECONDARY) , który określa porządek napisów identycznych
ze względu na porządek podstawowy, ale różniących się akcentowanymi znakami
(to dotyczy np. języków francuskiego, hiszpańskiego, angielskiego),
- trzeciorzędny (TERTIARY), który napisy identyczne wedle dwóch poprzednich porządków rozróżnia na podstawie wielkości liter,
- identyczności (IDENTICAL): rozróżniający wszelkie znaki, nawet te uznane
za takie same wedle trzech poprzednicj porządków (np. w wielu lokalizacjach
znaki \u0001 i \u0002 są uznawane za takie same wedle trzech w/w porządków,
natomiast porządek identyczności będzie je rozróżniał)
Stosowany dla danego kolatora porządek nazywa się siłą kolatora.
Nawet nie znając reguł danego kolatora możemy ustalać jego siłę (np. czy
napisy różniące się tylko wielkością liter mają być rozrózniane). Służy temu
metoda setStrength(...) z argumentem określającym siłę kolatora (jedna ze
stałych statycznych klasy Collator o nazwach PRIMARY, SECONDARY, TERTIARY,
IDENTICAL).
Możemy sami definiować reguły dla obiektów klasy RuleBasedCollator.
Reguły są zapisywane jak łańcuchy znakowe w postaci:
<relacja> tekst <relacja> tekst ....
gdzie relacja wprowadzana jest za pomocą znaków:
< - większe wedle pierwszego porządku (rozróżniania liter)
; - większe wedle drugirgo porządku (rozróżniania akcentowanych liter),
, - większe wedle trzeciego porządku (wielkość liter)
= - równe
a tekst jest dowolym ciągiem znaków wyłączając znaki specjalne i znaki opisujące
w/w relacje (jeśli takie znaki chcemy włączyć do porównań ujmujemy je w apostrofy).
Na przykład:
9 < a, A < b, B < c, C
Możemy też użyć znaku &, który łogicznie łączy reguły np:
a < b & b < c
jest identyczne z :
a < b < c
Stworzenie pełnego zestawu reguł dla kolatora może być dość pracochłonne. trzeba bowiem uwzględnić wiele możliwych znaków.
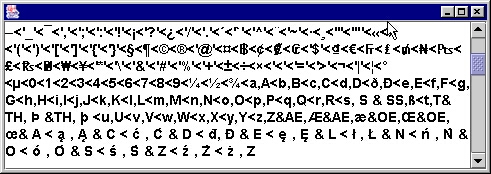
Zobaczmy najpierw jak wygląda fragment reguł dla kolatora w lokalizacji polskiej.
Reguły te możemy uzyskać za pomocą odwołania:
Collator col = Collator.getInstance();
String rules = ((RuleBasedCollator) col).getRules();
i pokazać np. w oknie:
Spróbujmy teraz rozpatrzyć uproszczony przykład (abstrahując od wielu możliwych
znaków). Przykłady sortowania pokazały nam, że rozróżnienie pomiędzy dużymi
i małymi literami nie jest pierwszorzędne: tylko w przypadku gdy napisy
są takie same kolator bierze pod uwagę tę różnicę i ustawia wtedy małe litery
przed wielkimi. Widać to zresztą w zestawie reguł np. ... < a, A <
b, B rozróznia najpierw litery a i b (bez uwzględneinia ich wielkości),
a dopiero gdy napisy (składający się z tych liter) są takie same bierze pod
uwagę
ich wielkość.
Stworzymy więc przykładowy inny zestaw reguł, który (przy sortowaniu rosnącym)
ustawi wyraz "Polska" na początku, a inne napisy posortuje w porządku -
najpierw duże litery, później małe (z uwzględnieniem polskich znaków i tego,
że polskie odpsoiedniki znaleźc sie mają po "normalnych" literach np. ą po
a).
Obrazuje to poniższy program:
import java.util.*;
import java.text.*;
public class Kolator1 {
static void sortShow(String msg, String[] txt, final Collator col) {
String[] copyTxt = (String[]) txt.clone();
Arrays.sort(copyTxt, col);
System.out.println(msg);
for (int i=0; i < copyTxt.length; i++) {
System.out.println(copyTxt[i]);
}
}
public static void main(String[] args) {
// Napisy do posortowania
String[] txt = { "bela", "Ala", "ą", "Ą", "ą", "ala" , "Be", "Ala",
"alabama", "be", "Be", "1", "Ćwikła", "ćwikła",
"ćwikla", "Polska",
"My", "my", "Myk", "myk" };
// Domyślny polski kolator
Collator col = Collator.getInstance();
sortShow("Default sort", txt, col);
// Nowe reguły
String rules = " < Polska < A < Ą < B < C < Ć < D < E < Ę < F < G < H" +
" < I < J < K < L < Ł < M < N < Ń < O < P < Q < R < S < Ś" +
" < T < U < V < W < X < Y < Z < Ź " +
" < a < ą < b < c < ć < d < e < ę < f < g < h" +
" < i < j < k < l < ł < m < n < ń < o < p < q < r < s < ś" +
" < t < u < v < w < x < y < z < ź";
try {
col = new RuleBasedCollator(rules);
} catch (ParseException exc) {
System.out.println("Wadliwa reguła na pozycji " + exc.getErrorOffset());
System.out.println(exc);
System.exit(1);
}
sortShow("My new rules sort", txt, col);
}
}
który wyprowadzi:
Default sort
1
ala
Ala
Ala
alabama
ą
ą
Ą
be
Be
Be
bela
ćwikla
ćwikła
Ćwikła
my
My
myk
Myk
Polska
My new rules sort
Polska
Ala
Ala
Ą
Be
Be
Ćwikła
My
Myk
ala
alabama
ą
ą
be
bela
ćwikla
ćwikła
my
myk
1
Jeżeli sortowanie jakiegoś zestawu napisów ma się powtarzać wielokrotnie,
to dla zwiększenia efektywności działania można przyporządkować napisom klucze
i sortować te klucze (klucze są sortowane szybciej).
Sposób postępowania jest następujący:
- stworzyć kolekcję lub tablicę na przechowywanie kluczy (obiektów klasy CollationKeys),
- dla każdego napisu, który ma podlegać porządkowaniu (sortowaniu) uzyskąc
klucz do kolatora za pomocą wywołania metody getCollationKey(napis) z klasy
Collator,
- wstawić klucz do tablicy lub kolekcji,
- posortować tablicę lub kolekcję,
- teraz klucze w tablicy/kolekcji są ustwaione w porządku napisów, określanym przez kolator
- żeby pokazać wynik sortowania przebiegamy tablicę/kolekcję kluczy i
od każdgeo klucza za pomocą odwołania getSourceString() uzyskujemy skojarzony
z nim napis.
Ilustruje to poniższy program.
import java.util.*;
import java.text.*;
public class Kolator2 {
public static void main(String[] args) {
// Napisy do posortowania
String[] txt = { "bela", "Ala", "ą", "Ą", "ą", "ala" , "Be", "Ala",
"alabama", "be", "Be", "1", "Ćwikła", "ćwikła",
"ćwikla", "Polska",
"My", "my", "Myk", "myk" };
// Domyślny polski kolator
Collator col = Collator.getInstance();
// Lista kluczy
List keys = new ArrayList();
// Uzyskanie kluczy dla napisów
// wartości kluczy uzyskujemy od kolatora
for (int i=0; i<txt.length; i++) {
CollationKey key = col.getCollationKey( txt[i] );
keys.add(key);
}
// Sortowanie
// porównywane mogą być tylko klucze uzyskane od tego samego kolatora!
Collections.sort(keys);
// Pokazanie wyniku
// mamy klucze ułożone w określonym porządku napisów, które reprezentują
// musimy pobrać napis skojarzony z kluczem
for (Iterator it = keys.iterator(); it.hasNext(); ) {
CollationKey key = (CollationKey) it.next();
String napis = key.getSourceString();
System.out.println(napis);
}
}
}
Internacjonalizacja aplikacji i dodatkowe zasoby (resource bundle)
Nie tylka liczby, daty, czas powinny być w aplikacjach przygotowane do prezentacji
zgodnie z wymaganiami danej lokalizacji. Również komunikacja aplikacji z
użytkownikiem powinna przebiegać w języku użytkownika.
Wszelkiego rodzaju napisy i komunikaty dla użytkownika powinny być lokalizacyjnie przygotowane.
Generalnie aplikacja powinna być od początku przygotowana na działanie
w różnych środowiskach językowych. A to oznacza konieczność odseparowania
językowych właściwości apliakcji (takich jak język komunikatów) od samego
jej kodu.
Mechanizmem umożliwiającycm takie odseparowanie w Javie są tzw. dodatkowe zasobu (ResourceBundle).
Istnieją dwa rodzaje dodatkowych zasobów: oparte na klasach (ListResourceBoundle)
i na czystych, tekstowych plikach właściwości (PropertiesResourceBundle).
Pliki właściwości umożliwiają odseparowanie napisów, klasy ListResourceBundle - dowolnych obiektów.
Jako prosty przykład stworzymy dwa pliki wartości klucz=napis: domyślny i dla lokalizacji polskiej:
Plik HelloMessages.properties
# Komunikaty w aplikacji Hello - domyślne przy braku pliku dla danej lokalizacji
hello = Hello!
bye = Good bye!
Plik HelloMessages_pl.properties
# Komunikaty w aplikacji Hello - po polsku
hello = Dzień dobry!
bye = Do widzenia.
Uwaga: klucze (hello, bye) są takie same.
Plików tych i mechanizmu dodatkowych zasobów użyjemy w prościutkiej aplikacji
Hello (dzięki czemu komunikacja z użytkownikiem naprawdę będzie odseparowana
od kodu źródłowego).
import java.util.*;
public class Hello {
static void sayHello() {
Locale defLoc = Locale.getDefault();
ResourceBundle msgs =
ResourceBundle.getBundle("HelloMessages", defLoc);
String powitaj = msgs.getString("hello");
String pozegnaj = msgs.getString("bye");
System.out.println(powitaj);
System.out.println(pozegnaj);
}
public static void main(String[] args) {
sayHello(); // tutaj działa domyślna lokalizacja pl_PL
// zmieniamy domyślną lokalizację
Locale.setDefault(new Locale("en"));
sayHello();
}
}
Wynik działania programu:
Dzień dobry!
Do widzenia.
Hello!
Good bye!
Uwagi:
- pierwsza para napisów powstaje, gdyż domyślną lokalizacją jest pl_PL,
getBundle(defLoc) nie znajduje pliku właściwości o takim sufiksie, ale znajduje
bliski mu z sufiksem pl,
- przy drugim odwołaniu do sayHello poszukiwany jest plik HelloMessages_en.properties,
a ponieważ go nie ma - używany jest domyślny HelloMessages.properties
Tak naprawdę ResourceBundle.getBundle(..) szuka najpierw klas dziedziczących
ListResourceBundle, a dopiero później plików właściwości.
Użycie ListResourceBundle wymaga od nas pisania kodu (i to jest wada w stosunku
do mechanizmu plików właściwości), ale równocześnie pozwala na wprowadzenie
"pod kluczami" - innych obiektów niż napisy (np. jakichś liczb, obrazów,
dźwięków - oczywiścię zlokalizowancyh).
Nasze zlokalizowane listy zasobów są klasami, które:
- mają nazwy zgodne z opisaną wcześniej (przy okazji plików własciwości) konwencją (sufiksy wskazujące na lokalizację)
- dziedziczą klasęe ListResourceBundle,
- dostarczają publicznej metody Object[][] getContents() która zwraca
tablicę odpowiedniości klucze - wartości, przy czym zaróno klucze jak i odpowiadające
im wartości mogą być dowolnymi obiektami.
Przykład:
public class CountryInfo_pl_PL extends ListResourceBundle {
public Object[][] getContents() {
return contents;
}
private Object[][] contents = {
{ "name", "Polska" },
{ "flag", new ImageIcon("PolskaFlaga.gif" },
};
}
Uzyskiwanie wartości z takich zasobów odbywa się w następujący sposób:
ResourceBundle info =
ResourceBundle.getBundle("CountryInfo", currentLocale);
String nazwaKraju = info.getString("name");
ImageIcon flaga = (ImageIcon) info.getObject("flag");
Uwaga: jeżeli wartość nie jest Stringiem należy zastosować metodę getObject()
i dokonać zawężającej konwersji do właściwego typu.
Dodatkowe zasoby (w specjalnej formie) razem z formatorem MessageFormat są
używane do generowania złożonych komunikatów, które opisywane są za pomocą
szablonu z wymiennymi parametrami.
Np.
Number val;
Object[] elts = { new Date(), val };
String format = "Dnia {0,date} o godzinie {0,time}" +
" wypłacono {1,number,currency}" },
MessageFormat.format(format, elts);
Przykład: Msg.java
Java 1.5 - metody ze zmienną liczbą argumentów:
private void setBlue(Component ... comps) {
for (Component c : comps) c.setForeground(Color.blue);
println("Liczba przekazanych kompoenntów: " + comps.length);
println("Szerokość pierwszego komponentu: " +
comps[0].getWidth());
println("Szerokość ostatniego komponentu: " +
comps[comps.length-1]);
}
i wywolanie:
setBlue(lab1, lab2, lab3);
setBlue(button1, button2); // nie trzeba tablic !!!
Statyczna metoda format z klasy MessagFormat jest zdefiniowana jako metoda ze zmienną liczbą argiemnetów.
Przykład: Msg1.java