SocketChannel socketChannel = SocketChannel.open(); // otwarcie kanału
socketChanel.connect(...) // podłączenie do gniazda
socketChannel.configureBlocking (false); // tryb nieblokujący
...
while (true) {
...
if (socketChannel.read (buffer) != 0) { // czy są jakieś dane?
processInput (buffer); // tak - przetwórz je
}
else { // nie - wykonuj inne czynności
...
}
}
Uwaga: co to jest buffer? O tym za chwilę.|
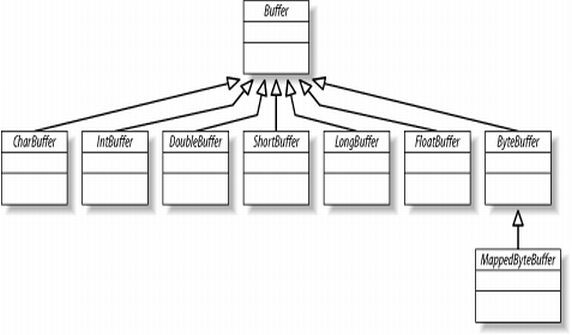
KANAŁY
|
|||
|
Kanały gniazdowe
|
Kanały plikowe
|
Kanały strumieniowe
|
|
| uzyskanie kanału |
metoda open() z klas SocketChannel, ServerSocketChannel, DatagramChannel + connect |
Metoda getChannel() z klas: FileInputStream FileOutputStream RandomAccessFile |
Metody statyczne klasy Channels: newChannel(InputStream) newChannel(OutputStream) |
|
Możliwości dostarczane przez kanały
|
|||
| nieblokujące wejście-wyjście i możliwość stosowania selektorów |
tak |
nie |
nie |
| atomistyczne czytanie rozprowadzające po wielu buforach (scattering read), atomistyczne pisanie gromadzące z wielu buforów (gathering write) |
tak |
tak |
nie |
| mapowanie plików na pamięć |
nie |
tak |
nie |
| bezpośrednie transfery kanałowe (np. jedno wywołanie kopiuje cały plik do innego w sposób bardzo efektywny) |
tak, jeśli jednym z kanałów jest kanał plikowy
|
tak
|
tak, jeśli jednym z kanałów jest kanał plikowy
|
| blokowanie (lock) dostępu do całego pliku lub jego części |
nie |
tak |
nie |
| czytanie, pisanie do/z buforów (zob. możliwości buforów) |
tak |
tak |
tak |
|
Możliwości, dostarczane przez bufory
|
| różne widoki buforów bajtowych (jako ciągu bajtów lub elementów wybranego typu pierwotnego) |
| przestawianie bajtów (możliwość wyboru i/lub
łatwej zmiany konwencj uporządkowania bajtów danych binarnych - czy bardziej
znaczące częsci danej mają w pamięci mniejsze czy większe adresy) |
| kodowanie - dekodowanie danych w buforach
znakowych przy uwzględnieniu wybranej strony kodowej (klasy Charset, CharsetDecoder
i CharsetEncoder, operujące na buforach) |
| bufory bezpośednie (bufory takie "opakowują"
pamięć alokowaną poza JVM przez natywne środki platformy systemowej i umożliwiają
m.in. wysoką efektywność operacji kanałowych, a także dają programiście możliwość
dostępu z poziomu programu Javy do dowolnego obszaru pamięci, alokowanego
w systemie - np. bezpośredniej pamięci graficznej) |
|
Metody get(...) z klas buforowych
(typ oznacza byte, char, short, int, long, float, doble - w zależności od typu bufora). |
|
typ |
get()Relatywna metoda get - zwraca bieżący element |
typBuffer |
get(typ[] dst)Relatywna metoda get - zapisuje tablicę dst elementami bufora, poczynając od jego bieżacej pozycji. |
typBuffer |
get(typ[] dst,
int offset,
int length)j.w. ale diotyczy części tablicy |
typ |
get(int index)Absolutna metoda get - zwraca element na pozycji index. |
|
Metody put z klas buforowych
(typ oznacza byte, char, short, int, long, float, doble - w zależności od typu bufora). |
|
typBuffer |
put(typ b)Relatywna metoda put - zapisuje element b na bieżącej pozycji |
typBuffer |
put(typ[] src)Relatywna metoda put - zapisuje do bufora tablicę elementów |
typBuffer |
put(typ[] src,
int offset,
int length)j.w. - część tablicy |
typBuffer |
put(typBuffer src)Relatywna metoda put - zapisuje zawartosc bufora src do bufora |
typBuffer |
put(int index, typ b)Absolutna metoda put, zapisuje b na pozycji index |
| Uwaga: jeżeli bufor jest tylko do odczytu (read-only), to użycie metody put(...) spowodują powstanie wyjątku ReadOnlyBufferException. Bufor możemy uczynić "tylko do odczytu" za pomocą metod asReadOnly() z klas buforowych. |
|
import java.nio.*;
class Buffers {
static void say(String s) { System.out.println(s); }
static void showParms(String msg, Buffer b) {
say("Charakterystyki bufora - " + msg);
say("capacity :" + b.capacity());
say("limit :" + b.limit());
say("position :" + b.position());
say("remaining :" + b.remaining());
}
public static void main(String args[]) {
// alokacja bufora 10 bajtowego (inicjalnie warości elementów = 0)
ByteBuffer b = ByteBuffer.allocate(10);
showParms("Po utworzeniu", b);
// Zapis dwóch bajtów do bufora
b.put((byte) 7).put((byte) 9);
showParms("Po dodaniu dwóch elementów", b);
// Przestawienie bufora
b.flip();
showParms("Po przestawieniu", b);
// Teraz możemy czytać wpisane dane
say("Czytamy pierwszy element: " + b.get());
showParms("Po pobraniu pierwszego elementu", b);
say("Czytamy drugi element: " + b.get());
showParms("Po pobraniu drugiego elementu", b);
say("Czy możemy jeszcze czytać?");
try {
byte x = b.get();
} catch (BufferUnderflowException exc) {
say("No, nie - proszę spojrzeć na ostatni limit!");
}
// Jeszcze raz odczytajmy dane z bufora
// w tym celu musimy go przewinąć
b.rewind();
showParms("Po przewinięciu", b);
say("Czytanie wszystkiego, co wpisaliśmy");
while (b.hasRemaining())
say("Jest: " + b.get());
}
}
który na wyjściu da:|
Zapis do kanału
|
| 1. Alokacja bufora bajtowego ByteBuffer buf = ByteBuffer.allocate(N); // N - rozmiar bufora 2. Zapis danych do bufora (np. z użyciem metod put...) 3. Uzyskanie kanału klasy FileChannel "do zapisu" Możemy go uzyskać za pomocą metod getChannel() z klas FileOutputStream oraz RandomAccessFile (kanał "do zapisu i do odczytu", jeśli taki był tryb otwarcia pliku o dostępie swobodnym). Np. FileOutputStream out = new FileOutputStream(...); FileChannel fc = out.getChannel(); 4. Zapis bufora - użycie metod write z klasy FileChannel. Np. fc.write(buf); 5. Zamknięcie kanału: fc.close(); Zamknięty kanał pozostaje zamknięty. Metoda isOpen() pozwala stwierdzić czy kanał jest otwarty. |
|
Czytanie z kanału
|
| 1. Alokacja bufora bajtowego ByteBuffer buf = ByteBuffer.allocate(N); // N - rozmiar bufora 2. Uzyskanie kanału klasy FileChannel "do odczytu" Możemy go uzyskać za pomocą metod getChannel() z klas FileInputStream oraz RandomAccessFile (kanał "do zapisu i do odczytu", jesli taki był tryb otwarcia pliku o dostępie swobodnym). Np. FileInputStream out = new FileInputStream(...); FileChannel fc = out.getChannel(); 3. Czytanie do bufora - użycie metod read z klasy FileChannel. Np. fc.read(buf); 4. Zamknięcie kanału: fc.close(); Zamknięty kanał pozostaje zamknięty. 5. Określenie właściwej pozycji i limitu bufora po wczytaniu do niego danych. Np. poprzez przestawienie bufora: buf.flip(); 6. Odczytanie danych z bufora za pomocą metod get... |
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
class SimpleChannel {
String fname = "test.tmp";
byte[] data = {1,2,3,4,5 };
SimpleChannel() {
try {
writeChannel(fname, data);
byte[] wynik = readChannel(fname);
for (int i=0; i < wynik.length; i++) System.out.println(wynik[i]);
} catch(Exception exc) {
exc.printStackTrace();
System.exit(1);
}
}
void writeChannel(String fname, byte[] data) throws Exception {
// Możemy utworzyć bufor przez opakowanie istniejącej tablicy
ByteBuffer buf = ByteBuffer.wrap(data);
FileOutputStream out = new FileOutputStream(fname);
// Uzyakanie kanału
FileChannel fc = out.getChannel();
//Zapis
fc.write(buf);
fc.close();
}
byte[] readChannel(String fname) throws Exception {
// Stworzenie strumienia na podstawie obiektu klasy File
FileInputStream in = new FileInputStream(fname;
// Uzyskanie kanału
FileChannel fc = in.getChannel();
// Metoda size() z klasy FileChannel
// zwraca long -rozmiar plku, do którego podlączony jest kanał
int size = (int) fc.size();
// Utworzenie bufora
ByteBuffer buf = ByteBuffer.allocate(size);
// Czytanie do bufora
// nbytes - liczba przeczytanych bajtów
int nbytes = fc.read(buf);
fc.close();
// Po przeczytaniu danych musimy bufor przestawić
buf.flip();
// Stworzenie tablicy na wynik czytania
// jej rozmiar będzie określony przez liczbę przeczytanuych bajtów
// którą możemy podać na dwa sposoby: poprzednie nbytes
// lub uzyskując informację o liczbie jeszcze nieodczytanych bajtów z bufora
byte[] wynik = new byte[buf.remaining()];
buf.get(wynik);
return wynik;
}
public static void main(String args[]) {
new SimpleChannel();
}
}
import java.nio.*;
class BufView1 {
public static void main(String args[]) {
final int SHORT_SIZE = 2;
// Alokacja buforu bajtowego,
// mogącego przechowywać do 10 liczb typu short
ByteBuffer bb = ByteBuffer.allocate(10*SHORT_SIZE);
// Widok na ten bofor jak na short-bufor
ShortBuffer sb = bb.asShortBuffer();
// Dodanie trzech liczb typu short
short a = 1, b = 2, c = 3;
sb.put(a).put(b).put(c);
// Co wpisano do bufora? Na wydruku: 1, 2, 3
sb.flip();
while (sb.hasRemaining()) System.out.println(sb.get());
// Operujemy teraz na nim za pomocą bufora bajtowego
// zmieniając bajty na pozycji 1, 3 i 5.
byte x = 4, y = 5, z = 6;
bb.put(1, x).put(3, y).put(5, z);
// Co pokaże short-bufor? Na wydruku 4, 5, 6
sb.rewind();
while (sb.hasRemaining()) System.out.println(sb.get());
}
}
public static void main(String args[]) {
final int SHORT_SIZE = 2;
ByteBuffer bb = ByteBuffer.allocate(10*SHORT_SIZE);
ShortBuffer sb = bb.asShortBuffer();
short a = 1, b = 2, c = 3;
sb.put(a).put(b).put(c);
showParms("bufor short - po dodaniu liczb", sb);
showParms("bufor bajtowy - po dodaniu liczb", bb);
sb.flip();
showParms("bufor short - po przestawieniu", sb);
showParms("bufor bajtowy - po flip bufora short", bb);
System.out.print("Dane");
while (bb.hasRemaining()) System.out.print(" " + bb.get());
}
}
Wydruk.
sb.flip();
bb.limit(sb.limit()*SHORT_SIZE);
System.out.print("Bajty wpisanych danych");
while (bb.hasRemaining()) System.out.print(" " + bb.get());
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
class BuffChan {
String fname = "testfile.tmp";
// inicjacja danych testowych
void init() throws Exception {
double[] data = { 0.1, 0.2, 0.3 };
DataOutputStream out = new DataOutputStream(
new FileOutputStream(fname)
);
for (int i=0; i < data.length; i++) out.writeDouble(data[i]);
out.close();
}
BuffChan() throws Exception {
// inicjalcja danych testowych
init();
// utworzenie bufora
ByteBuffer buf = ByteBuffer.allocate(1000); // nie wiemy ile, maks 100B
// uzyskanie kanału
FileChannel fcin = new FileInputStream(fname).getChannel();
// czytanie z kanału do bufora
fcin.read(buf);
fcin.close();
// przestawienie bufora bajtowego
buf.flip();
// Utworzenie widoku bufora
DoubleBuffer dbuf = buf.asDoubleBuffer();
// Wypisanie odczytanych danych
while (dbuf.hasRemaining()) System.out.println(dbuf.get());
}
public static void main(String args[]) throws Exception {
new BuffChan();
}
}
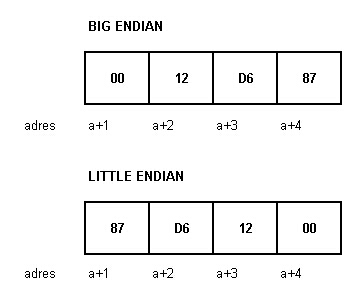
import java.nio.*;
class Endianness {
static void show(int n) {
String s = Integer.toHexString(n);
int l = s.length();
for (int i=l; i < 8; i++) s = '0' + s;
System.out.println("Liczba " + n + " hex -> " + s.toUpperCase());
}
public static void main(String args[]) {
int num = Integer.parseInt(args[0]);
ByteBuffer buf = ByteBuffer.allocate(4);
System.out.println(buf.order().toString());
IntBuffer b1 = buf.asIntBuffer();
System.out.println("Porządek b1 " + b1.order());
b1.put(num);
b1.flip();
show(b1.get());
buf.order(ByteOrder.LITTLE_ENDIAN);
System.out.println("Porządek buf " + buf.order());
System.out.println("Porządek b1 " + b1.order());
b1.rewind();
show(b1.get());
System.out.println("Porządek buf " + buf.order());
System.out.println("Porządek dziedzizcony " + buf.asIntBuffer().order());
show(buf.asIntBuffer().get());
}
}
który dla podanej jako argument liczby 987654321 wyprowadzi następujące wyniki: char |
charAt(int index)Zwraca znak na pozycji index |
int |
length()Zwraca długość sekwencji znaków |
CharSequence |
subSequence(int start,
int end)Zwraca podsekwencję od znaku na pozycji start do znaku na pozycji end (wyłacznie) |
String |
toString()Zwraca referencję do nowego obiektu klasy String, zawierającego tę sekwencję znaków. |
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
class Ende1 {
public static void main(String[] args) {
if (args.length != 4) {
System.out.println("Syntax: in in_enc out out_enc");
System.exit(1);
}
String infile = args[0], // plik wejściowy
in_enc = args[1], // wejściowa strona kodowa
outfile = args[2], // plik wyjściowy
out_enc = args[3]; // wyjściowa strona kodowa
try {
FileChannel fcin = new FileInputStream(infile).getChannel();
FileChannel fcout = new FileOutputStream(outfile).getChannel();
ByteBuffer buf = ByteBuffer.allocate((int)fcin.size());
// czytanie z kanału
fcin.read(buf);
// przeniesienie zawartości bufora do tablicy bytes
buf.flip();
byte[] bytes = new byte[buf.capacity()];
buf.get(bytes);
// dekodowanie - za pomocą konstruktora klasy String
String txt = new String(bytes, in_enc);
// enkodowanie za pomocą metody getBytes z klasy String
// utworzenie nowego bufora dla kanału wyjściowego
// zapis do pliku poprzez kanał
bytes = txt.getBytes(out_enc);
buf = ByteBuffer.wrap(bytes);
fcout.write(buf);
fcin.close();
fcout.close();
} catch (Exception e) {
System.err.println(e);
System.exit(1);
}
}
}
ale jest to rozwiązanie dodatkowo obciążające pamięć operacyjną oraz - jak widać - mało wygodne w programowaniu.
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
import java.nio.charset.*;
class Ende2 {
public static void main(String[] args) {
if (args.length != 4) {
System.out.println("Syntax: in in_enc out out_enc");
System.exit(1);
}
String infile = args[0], // plik wejściowy
in_enc = args[1], // wejściowa strona kodowa
outfile = args[2], // plik wyjściowy
out_enc = args[3]; // wyjściowa strona kodowa
try {
FileChannel fcin = new FileInputStream(infile).getChannel();
FileChannel fcout = new FileOutputStream(outfile).getChannel();
ByteBuffer buf = ByteBuffer.allocate((int)fcin.size());
// czytanie z kanału
fcin.read(buf);
// Strony kodowe
Charset inCharset = Charset.forName(in_enc),
outCharset = Charset.forName(out_enc);
// dekodowanie bufora bajtowego
buf.flip();
CharBuffer cbuf = inCharset.decode(buf);
// enkodowanie bufora znakowego
// i zapis do pliku poprzez kanał
buf = outCharset.encode(cbuf);
fcout.write(buf);
fcin.close();
fcout.close();
} catch (Exception e) {
System.err.println(e);
System.exit(1);
}
}
}
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
public class ScatteringTest {
static final String fname = "scatter.tst"; // nazwa pliku testowego
public static void main(String[] args) throws Exception {
// Zapisywanie danych testowych
DataOutputStream out = new DataOutputStream(
new FileOutputStream(fname) );
short[] dat1 = { 1, 2, 3, };
double[] dat2 = { 10.1, 10.2, 10.3 };
for (int i=0; i < dat1.length; i++) out.writeShort(dat1[i]);
for (int i=0; i < dat2.length; i++) out.writeDouble(dat2[i]);
out.close();
//-----------------------------------------------------------+
// Odczytywanie danych testowych |
//-----------------------------------------------------------+
FileInputStream in = new FileInputStream(fname);
// Uzyskanie kanału
FileChannel channel = in.getChannel();
// Tablica bajt-buforów
final int SHORT_SIZE = 2, // ile bajtów ma short
DOUBLE_SIZE = 8; // ........... i double
ByteBuffer[] buffers = { ByteBuffer.allocate(dat1.length*SHORT_SIZE),
ByteBuffer.allocate(dat2.length*DOUBLE_SIZE)
};
// jedno czytanie z kanału zapisuje kilka buforów !
long r = channel.read(buffers);
System.out.println("Liczba bajtów przeczytanych do obu buforów: " + r);
// Przed uzyskiwaniem danych z buforów - trzeba je przestawić!
buffers[0].flip();
buffers[1].flip();
// Pierwssy bufor
// Widok na bufor jako na zawierający liczby short
ShortBuffer buf1 = buffers[0].asShortBuffer();
System.out.println("Dane 1");
while ( buf1.hasRemaining()) {
short elt = buf1.get();
System.out.println(elt);
}
// Drugi bufor
// Widok na bufor jako na zawierający liczby double
DoubleBuffer buf2 = buffers[1].asDoubleBuffer();
System.out.println("Dane 2");
while ( buf2.hasRemaining()) System.out.println(buf2.get());
}
}
wyprowadzi następujące wyniki:
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
import java.nio.charset.*;
class GatheringTest {
public static void main(String[] args) throws Exception {
// To będą stałe części każdego pliku
String sHeader = "To jest nagłówek. Może być duży";
String sFooter = "To jest zakończenie. Może być duże";
// To będą dane, które się zmieniają od pliku do pliku
byte[][] dane = { { 1, 2, 3}, // dane 1-go pliku
{ 9, 10, 11, 12 }, // dane 2-go pliku
{ 100, 101} // dane 3-go pliku
};
Charset charset = Charset.forName("windows-1250");
ByteBuffer header = charset.encode(CharBuffer.wrap(sHeader)),
footer = charset.encode(CharBuffer.wrap(sFooter));
// Drugi element tablicy buforów będzie dynamicznie się zmienial
// na razie = null
ByteBuffer[] contents = { header, null, footer };
for (int i = 0; i<dane.length; i++) {
FileChannel fc = new FileOutputStream("plik"+i).getChannel();
contents[1] = ByteBuffer.wrap(dane[i]); // podstawienie zmiennych danych
fc.write(contents); // zapis danych ze wszystkich buforów!
fc.close();
header.rewind();
footer.rewind();
}
}
}
|
Tryb mapowania
|
Tryb otwarcia kanału
|
Rodzaj pliku,
do którego podłączamy kanał metodą getChannel() |
| READ_ONLY |
tylko do odczytu |
FileInputStream RandomAccesFile otwarty w trybie tylko do odczytu ("r") |
| READ_WRITE PRIVATE |
do odczytu-zapisu |
RandomAccesFile otwarty w trybie pisania-czytania ("rw") |
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
class MapFiles1 {
String fname = "test";
public MapFiles1() throws Exception {
init(); // inicjacja pliku testowego
mapAndChange(); // mapowanie i zmiana danych pliku
checkResult(); // sprawdzenie wyników
}
void init() throws IOException {
int[] data = { 10, 11, 12, 13 };
DataOutputStream out = new DataOutputStream(
new FileOutputStream(fname)
);
for (int i=0; i<data.length; i++) out.writeInt(data[i]);
out.close();
}
void mapAndChange() throws IOException {
// Aby dokonywać zmian musimy przyłączyć kanal
// do pliku otwartego w trybie "read-write"
RandomAccessFile file = new RandomAccessFile(fname, "rw");
FileChannel channel = file.getChannel();
// Mapowanie pliku
MappedByteBuffer buf;
buf = channel.map(
FileChannel.MapMode.READ_WRITE, // tryb "odczyt-zapis"
0, // od początku pliku
(int)channel.size() // cały plik
);
// Uzyskujemy widok na bufor = zmapowany plik
IntBuffer ibuf = buf.asIntBuffer();
// Dla ciekawości: jakie charakterystyki widoku
System.out.println(ibuf + " --- Direct: " + ibuf.isDirect());
int i = 0;
while (ibuf.hasRemaining()) {
int num = ibuf.get(); // pobieramy kolejny element
ibuf.put(i++, num * 10); // zapisujemy jego wartość*10 na jego pozycji }
}
// Zapewnia, że zmiany na pewno zostaną odzwierciedlone w pliku
buf.force();
channel.close();
}
void checkResult() throws IOException {
DataInputStream in = null;
try {
in = new DataInputStream(new FileInputStream(fname));
while(true) System.out.println(in.readInt());
} catch(EOFException exc) {
return;
} finally {
in.close();
}
}
public static void main(String[] args) throws Exception {
new MapFiles1();
}
}
Program wyprowadzi:
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
import java.nio.charset.*;
class MapFiles2 {
public static void main(String[] args) throws Exception {
Charset inCharset = Charset.forName("windows-1250"),
outCharset = Charset.forName("ISO-8859-2");
RandomAccessFile file = new RandomAccessFile(args[0], "rw");
FileChannel fc = file.getChannel();
// Mapowanie pliku
MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE,
0, (int) fc.size());
// Utworzenia bufora znakowego ze zdekodowanymi znakami
// z bufora bajtowego (mapujące plik). Konwersja: win1250->unicode
CharBuffer cbuf = inCharset.decode(mbb);
// Okazuje się, że ten nowo utworzony bufor opakowuje tablicę
// zatem możemy ją uzyskać i działać na jej elementach
// to dzialanie oznacza dzialanie na elementach bufora
char[] chArr = cbuf.array();
for (int i=0; i < chArr.length; i++)
chArr[i] = Character.toUpperCase(chArr[i]);
// Po dekodowaniu bufor bajtowy musi być przewinięty do początku
// aby koder (zob. dalej) mógł w nim zapisywać kodowane dane
mbb.rewind();
// Utworzenie kodera, zamieniającego Unicode na wyjściową stronę kodową
CharsetEncoder encoder = outCharset.newEncoder();
// Koder zapisuje istniejący bufor mbb (ten który mapuje plik)
// ostatni argument - true oznacza zakończenie pracy kodera na tym wywołaniu
encoder.encode(cbuf, mbb, true);
fc.close();
}
}
import java.nio.*;
import java.nio.channels.*;
import java.io.*;
class DirectTransfer {
String inFileName;
String outFileName;
DirectTransfer(String infn, String outfn) throws Exception {
inFileName = infn;
outFileName = outfn;
directTransfer();
copyByStream();
}
void directTransfer() throws Exception {
FileInputStream in = new FileInputStream(inFileName);
FileOutputStream out = new FileOutputStream(outFileName);
FileChannel fcin = in.getChannel();
FileChannel fcout = out.getChannel();
long size = fcin.size();
System.out.println("Copying file " + size + "B.");
long start = System.currentTimeMillis();
// Bezpośredni transfer
fcout.transferFrom(fcin, 0, size);
long end = System.currentTimeMillis();
System.out.println("Direct transfer time " + (end - start));
}
final int BUFSIZE = 5000000;
void copyByStream() throws Exception {
FileInputStream fin = new FileInputStream(inFileName);
BufferedInputStream in = new BufferedInputStream(fin, BUFSIZE );
FileOutputStream fout = new FileOutputStream(outFileName);
BufferedOutputStream out = new BufferedOutputStream(fout, BUFSIZE);
byte[] b = new byte[BUFSIZE];
long start = System.currentTimeMillis();
while (true) {
int n = in.read(b);
if (n == -1) break;
out.write(b, 0, n);
}
in.close();
out.close();
long end = System.currentTimeMillis();
System.out.println("Stream time " + (end - start));
}
public static void main(String[] args) throws Exception {
new DirectTransfer(args[0], args[1]);
}
}
Możliwy wynik: