|
|
| « poprzedni punkt | następny punkt » |
Jednym z problemów, z którymi spotykamy się w informatyce, jest problem właściwego wykorzystania pamięci. Konstruując algorytm staramy się zwykle nie tylko o zminimalizowanie kosztów czasowych algorytmu, ale także o dobrą złożoność pamięciową algorytmu. Ale co zrobić, jeśli to dane są bardzo duże? Jak je przechowywać w pamięci komputera? I tu przychodzą nam z pomocą techniki kompresji danych, tzn. metody kodowania danych w takiej postaci, która pozwala zapisać ten sam zbiór informacji wykorzystując dużo mniej miejsca. Oczywiście, zależy nam tylko na takich metodach, które pozwalają szybko zakodować dane, oraz szybko i jednoznacznie odkodować zakodowaną informację.
Przykład 2.1
Przypuśćmy, że pewien zbiór danych zawiera 106 znaków. Jeśli każdy z tych znaków jest reprezentowany przez liczbę z przedziału 0-255, to na zapisanie jednego znaku musimy zużyć 8 bitów (256 = 28). Wynika stąd, że na zapisanie całego pliku zużyjemy 8 ´ 106 bitów. Gdybyśmy jednak mieli dodatkową informację, np. że w danych występują jedynie cyfry od 0 do 9, to moglibyśmy na znak przeznaczyć tylko 4 bity co pozwoliłoby zakodować cały zbiór na 4 ´ 106 bitach. Przyporządkowanie znakom kodu mogłoby wyglądać np. tak:
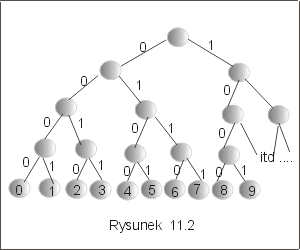
0- 0000, 1- 0001, 2- 0010, 3- 0011 itd... 9-1001.
Dekodowanie zakodowanego pliku jest, przy takim kodzie, banalnie proste: odczytujemy kolejne cztery bity (słowo kodowe) i w słowniczku sprawdzamy jaki to znak. Na przykład, ciąg bitów 0010001100100011 jest kodem liczby 2323. Ponieważ słownik składa się tylko z dziesięciu elementów, więc w najgorszym razie odszukanie jednego znaku wymagać będzie porównania z dziesięcioma słowami kodowymi. Nie musimy jednak przeszukiwać słownika sekwencyjnie. Przedstawmy zbiór słów kodowych w postaci drzewa binarnego (drzewa kodowego), w którego liściach przechowywane są kodowane znaki, a każde przejście w lewo odpowiada bitowi 0, a przejście w prawo- bitowi 1. W ten sposób każda ścieżka od korzenia do liścia odpowiada słowu kodującemu znak zapamiętany w liściu, por. rysunek 11.2.J
|
|
Pytanie 2: Ile bitów trzeba przeznaczyć na zakodowanie tekstu złożonego z 107 znaków, jeśli użyto kodu o stałej długości, a tekst składa się tylko z liczb naturalnych oddzielonych przecinkami lub spacjami, oraz z liter x, y, z?
Zauważmy, że w przykładzie 2.1 niektóre liście drzewa kodowego nigdy nie będą potrzebne, bo ciąg bitów prowadzący do nich, nigdy nie wystąpi w zakodowanym tekście. Na przykład ciąg 1111 nie jest kodem żadnego ze znaków tego tekstu, więc nie wystąpi w zakodowanym tekście. Co więcej, gdyby cyfry 9 i 8 występowały w tekście tylko niewielką liczbę razy, to i tak do ich zakodowania użyjemy aż 4 bitów. Czy to nie jest marnotrawstwo? A może zrezygnować ze stałej długości kodu i długość kodu uzależnić od częstości występowania tego znaku w kodowanym tekście. Zasada jest prosta: znakom, które występują często przypisujemy krótkie kody. Wynika stąd, że kody będą miał różne długości.
Przykład 2.2
Niech w danym pliku, cyfry 0 i 1 występują 3 ´106 razy, a pozostałe cyfry jedynie po 5´105 razy. Wtedy plik zawierający 107 znaków można zakodować używając tylko 8´106 bitów, stosując kod 00 dla cyfry 0, 01 dla cyfry 1 oraz czterobitowe kody dla cyfr 2, 3, ..., 8, 9.
Liczba bitów potrzebna do zakodowania tekstu, dla którego znamy częstości występowania znaków , wynosi
SaÎA f(a) ´ dT(a),
gdzie f(a) jest częstością występowania znaku a, a dT(a) jest długością kodu dla znaku a.
Problem, który się teraz pojawia, to jak zbudować kod uzależniający długość kodu od częstości występowania znaków, w taki sposób, by można go było jednoznacznie odczytać (dekodować). Warunek ten spełniają kody prefiksowe.
Kody prefiksowe są bardzo wygodne, gdyż dekodowanie jest niezwykle proste: odczytujemy pierwsze słowo kodowe znajdujące się na początku zakodowanego tekstu i usuwamy go. Ponieważ żadne słowo kodowe nie jest prefiksem innego słowa, więc to pierwsze słowo jest jednoznacznie wyznaczone. Po jego usunięciu postępowanie możemy powtórzyć. Identyfikację słowa znakomicie upraszcza reprezentacja kodu w postaci drzewa binarnego (drzewa kodowego), por. przykład 2.1.
Uwaga Optymalny kod jest zawsze reprezentowany przez lokalnie pełne drzewo binarne, por. wykład V, definicja 1.1. Zatem, jeśli dany jest alfabet A, to drzewo optymalnego kodu ma |A| liści oraz dokładnie |A|-1 wierzchołków wewnętrznych.
Pytanie 3: Ile bitów wymaga kod stałej długości, a ile kod zmiennej
długości, dla zakodowania tekstu złożonego z 1000 znaków, w którym występuje 8 różnych znaków, a każdy z taką samą częstością?
| « poprzedni punkt | następny punkt » |